 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Learning: Optimizing Fine-Tuning with Partially Mastered Knowledge in Large Language Models
Paper and Code
Oct 08, 2024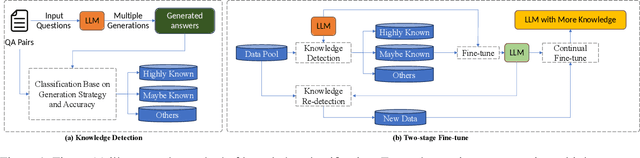
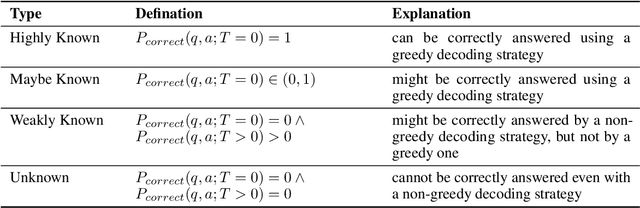

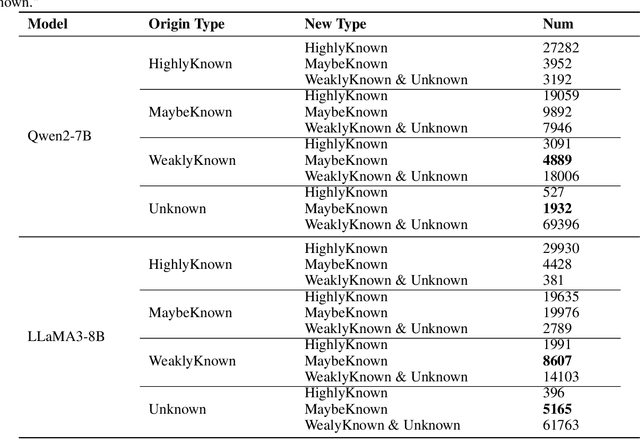
During the pretraining phase, large language models (LLMs) acquire vast amounts of knowledge from extensive text corpora. Nevertheless, in later stages such as fine-tuning and inference, the model may encounter knowledge not covered in the initial training, which can lead to hallucinations and degraded performance. This issue has a profound impact on the model's capabilities, as it will inevitably face out-of-scope knowledge after pretraining. Furthermore, fine-tuning is often required to adapt LLMs to domain-specific tasks. However, this phenomenon limits the model's ability to learn and integrate new information during fine-tuning. The effectiveness of fine-tuning largely depends on the type of knowledge involved. Existing research suggests that fine-tuning the model on partially mastered knowledge-for instance, question-answer pairs where the model has a chance of providing correct responses under non-greedy decoding-can enable the model to acquire new knowledge while mitigating hallucination. Notably, this approach can still lead to the forgetting of fully mastered knowledge, constraining the fine-tuning dataset to a narrower range and limiting the model's overall potential for improvement. Given the model's intrinsic reasoning abilities and the interconnectedness of different knowledge areas, it is likely that as the model's capacity to utilize existing knowledge improves during fine-tuning, previously unmastered knowledge may become more understandable. To explore this hypothesis, we conducted experiments and, based on the results, proposed a two-stage fine-tuning strategy. This approach not only improves the model's overall test accuracy and knowledge retention but also preserves its accuracy on previously mastered content. When fine-tuning on the WikiQA dataset, our method increases the amount of knowledge acquired by the model in this stage by 24%.