 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
Feb 04, 2026Omni-modal Large Language Models (Omni-LLMs) have demonstrated strong capabilities in audio-video understanding tasks. However, their reliance on long multimodal token sequences leads to substantial computational overhead. Despite this challenge, token compression methods designed for Omni-LLMs remain limited. To bridge this gap, we propose OmniSIFT (Omni-modal Spatio-temporal Informed Fine-grained Token compression), a modality-asymmetric token compression framework tailored for Omni-LLMs. Specifically, OmniSIFT adopts a two-stage compression strategy: (i) a spatio-temporal video pruning module that removes video redundancy arising from both intra-frame structure and inter-frame overlap, and (ii) a vision-guided audio selection module that filters audio tokens. The entire framework is optimized end-to-end via a differentiable straight-through estimator. Extensive experiments on five representative benchmarks demonstrate the efficacy and robustness of OmniSIFT. Notably, for Qwen2.5-Omni-7B, OmniSIFT introduces only 4.85M parameters while maintaining lower latency than training-free baselines such as OmniZip. With merely 25% of the original token context, OmniSIFT consistently outperforms all compression baselines and even surpasses the performance of the full-token model on several tasks.
Semantic Routing: Exploring Multi-Layer LLM Feature Weighting for Diffusion Transformers
Feb 03, 2026Recent DiT-based text-to-image models increasingly adopt LLMs as text encoders, yet text conditioning remains largely static and often utilizes only a single LLM layer, despite pronounced semantic hierarchy across LLM layers and non-stationary denoising dynamics over both diffusion time and network depth. To better match the dynamic process of DiT generation and thereby enhance the diffusion model's generative capability, we introduce a unified normalized convex fusion framework equipped with lightweight gates to systematically organize multi-layer LLM hidden states via time-wise, depth-wise, and joint fusion. Experiments establish Depth-wise Semantic Routing as the superior conditioning strategy, consistently improving text-image alignment and compositional generation (e.g., +9.97 on the GenAI-Bench Counting task). Conversely, we find that purely time-wise fusion can paradoxically degrade visual generation fidelity. We attribute this to a train-inference trajectory mismatch: under classifier-free guidance, nominal timesteps fail to track the effective SNR, causing semantically mistimed feature injection during inference. Overall, our results position depth-wise routing as a strong and effective baseline and highlight the critical need for trajectory-aware signals to enable robust time-dependent conditioning.
Research on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
DiaDem: Advancing Dialogue Descriptions in Audiovisual Video Captioning for Multimodal Large Language Models
Jan 27, 2026Accurate dialogue description in audiovisual video captioning is crucial for downstream understanding and generation tasks. However, existing models generally struggle to produce faithful dialogue descriptions within audiovisual captions. To mitigate this limitation, we propose DiaDem, a powerful audiovisual video captioning model capable of generating captions with more precise dialogue descriptions while maintaining strong overall performance. We first synthesize a high-quality dataset for SFT, then employ a difficulty-partitioned two-stage GRPO strategy to further enhance dialogue descriptions. To enable systematic evaluation of dialogue description capabilities, we introduce DiaDemBench, a comprehensive benchmark designed to evaluate models across diverse dialogue scenarios, emphasizing both speaker attribution accuracy and utterance transcription fidelity in audiovisual captions. Extensive experiments on DiaDemBench reveal even commercial models still exhibit substantial room for improvement in dialogue-aware captioning. Notably, DiaDem not only outperforms the Gemini series in dialogue description accuracy but also achieves competitive performance on general audiovisual captioning benchmarks, demonstrating its overall effectiveness.
GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models
Dec 17, 2025The text encoder is a critical component of text-to-image and text-to-video diffusion models, fundamentally determining the semantic fidelity of the generated content. However, its development has been hindered by two major challenges: the lack of an efficient evaluation framework that reliably predicts downstream generation performance, and the difficulty of effectively adapting pretrained language models for visual synthesis. To address these issues, we introduce GRAN-TED, a paradigm to Generate Robust, Aligned, and Nuanced Text Embeddings for Diffusion models. Our contribution is twofold. First, we propose TED-6K, a novel text-only benchmark that enables efficient and robust assessment of an encoder's representational quality without requiring costly end-to-end model training. We demonstrate that performance on TED-6K, standardized via a lightweight, unified adapter, strongly correlates with an encoder's effectiveness in downstream generation tasks. Second, guided by this validated framework, we develop a superior text encoder using a novel two-stage training paradigm. This process involves an initial fine-tuning stage on a Multimodal Large Language Model for better visual representation, followed by a layer-wise weighting method to extract more nuanced and potent text features. Our experiments show that the resulting GRAN-TED encoder not only achieves state-of-the-art performance on TED-6K but also leads to demonstrable performance gains in text-to-image and text-to-video generation. Our code is available at the following link: https://anonymous.4open.science/r/GRAN-TED-4FCC/.
The Unseen Bias: How Norm Discrepancy in Pre-Norm MLLMs Leads to Visual Information Loss
Dec 09, 2025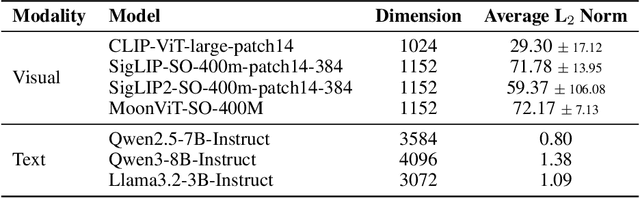

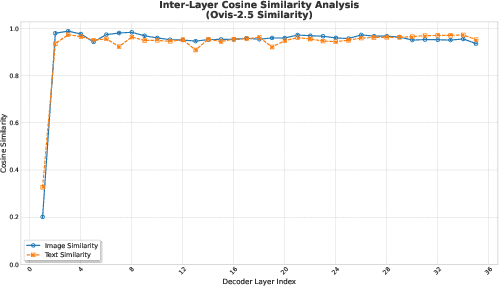

Multimodal Large Language Models (MLLMs), which couple pre-trained vision encoders and language models, have shown remarkable capabilities. However, their reliance on the ubiquitous Pre-Norm architecture introduces a subtle yet critical flaw: a severe norm disparity between the high-norm visual tokens and the low-norm text tokens. In this work, we present a formal theoretical analysis demonstrating that this imbalance is not a static issue. Instead, it induces an ``asymmetric update dynamic,'' where high-norm visual tokens exhibit a ``representational inertia,'' causing them to transform semantically much slower than their textual counterparts. This fundamentally impairs effective cross-modal feature fusion. Our empirical validation across a range of mainstream MLLMs confirms that this theoretical dynamic -- the persistence of norm disparity and the resulting asymmetric update rates -- is a prevalent phenomenon. Based on this insight, we propose a remarkably simple yet effective solution: inserting a single, carefully initialized LayerNorm layer after the visual projector to enforce norm alignment. Experiments conducted on the LLaVA-1.5 architecture show that this intervention yields significant performance gains not only on a wide suite of multimodal benchmarks but also, notably, on text-only evaluations such as MMLU, suggesting that resolving the architectural imbalance leads to a more holistically capable model.
ID-Align: RoPE-Conscious Position Remapping for Dynamic High-Resolution Adaptation in Vision-Language Models
May 27, 2025Currently, a prevalent approach for enhancing Vision-Language Models (VLMs) performance is to encode both the high-resolution version and the thumbnail of an image simultaneously. While effective, this method generates a large number of image tokens. When combined with the widely used Rotary Position Embedding (RoPE), its long-term decay property hinders the interaction between high-resolution tokens and thumbnail tokens, as well as between text and image. To address these issues, we propose ID-Align, which alleviates these problems by reordering position IDs. In this method, high-resolution tokens inherit IDs from their corresponding thumbnail token while constraining the overexpansion of positional indices. Our experiments conducted within the LLaVA-Next framework demonstrate that ID-Align achieves significant improvements, including a 6.09% enhancement on MMBench's relation reasoning tasks and notable gains across multiple benchmarks. Our code is available at the following link: https://github.com/zooblastlbz/ID-Align.
Gradual Learning: Optimizing Fine-Tuning with Partially Mastered Knowledge in Large Language Models
Oct 08, 2024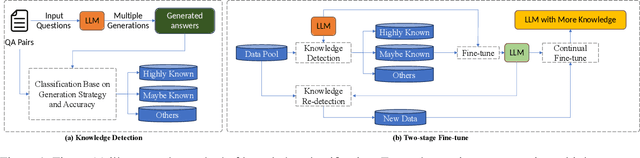
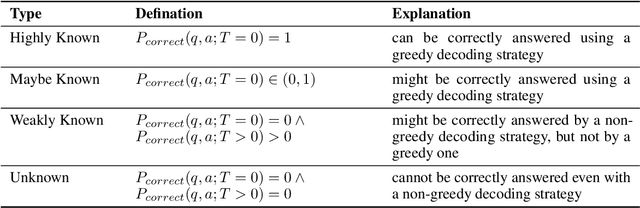

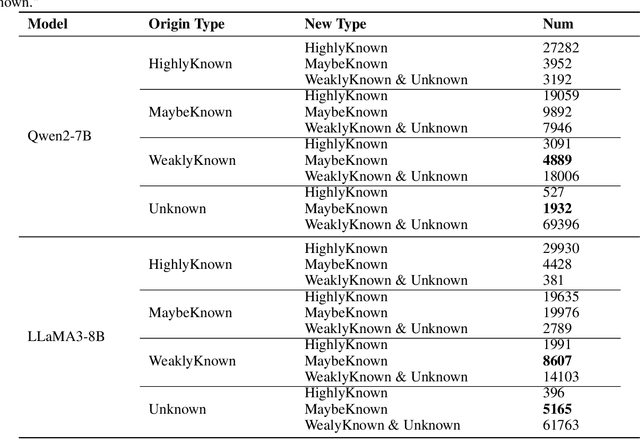
During the pretraining phase, large language models (LLMs) acquire vast amounts of knowledge from extensive text corpora. Nevertheless, in later stages such as fine-tuning and inference, the model may encounter knowledge not covered in the initial training, which can lead to hallucinations and degraded performance. This issue has a profound impact on the model's capabilities, as it will inevitably face out-of-scope knowledge after pretraining. Furthermore, fine-tuning is often required to adapt LLMs to domain-specific tasks. However, this phenomenon limits the model's ability to learn and integrate new information during fine-tuning. The effectiveness of fine-tuning largely depends on the type of knowledge involved. Existing research suggests that fine-tuning the model on partially mastered knowledge-for instance, question-answer pairs where the model has a chance of providing correct responses under non-greedy decoding-can enable the model to acquire new knowledge while mitigating hallucination. Notably, this approach can still lead to the forgetting of fully mastered knowledge, constraining the fine-tuning dataset to a narrower range and limiting the model's overall potential for improvement. Given the model's intrinsic reasoning abilities and the interconnectedness of different knowledge areas, it is likely that as the model's capacity to utilize existing knowledge improves during fine-tuning, previously unmastered knowledge may become more understandable. To explore this hypothesis, we conducted experiments and, based on the results, proposed a two-stage fine-tuning strategy. This approach not only improves the model's overall test accuracy and knowledge retention but also preserves its accuracy on previously mastered content. When fine-tuning on the WikiQA dataset, our method increases the amount of knowledge acquired by the model in this stage by 24%.
Are Bigger Encoders Always Better in Vision Large Models?
Aug 01, 2024In recent years, multimodal large language models (MLLMs) have shown strong potential in real-world applications. They are developing rapidly due to their remarkable ability to comprehend multimodal information and their inherent powerful cognitive and reasoning capabilities. Among MLLMs, vision language models (VLM) stand out for their ability to understand vision information. However, the scaling trend of VLMs under the current mainstream paradigm has not been extensively studied. Whether we can achieve better performance by training even larger models is still unclear. To address this issue, we conducted experiments on the pretraining stage of MLLMs. We conduct our experiment using different encoder sizes and large language model (LLM) sizes. Our findings indicate that merely increasing the size of encoders does not necessarily enhance the performance of VLMs. Moreover, we analyzed the effects of LLM backbone parameter size and data quality on the pretraining outcomes. Additionally, we explored the differences in scaling laws between LLMs and VLMs.
A Survey of Multimodal Large Language Model from A Data-centric Perspective
May 26, 2024



Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.