 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
From Completion to Editing: Unlocking Context-Aware Code Infilling via Search-and-Replace Instruction Tuning
Jan 19, 2026The dominant Fill-in-the-Middle (FIM) paradigm for code completion is constrained by its rigid inability to correct contextual errors and reliance on unaligned, insecure Base models. While Chat LLMs offer safety and Agentic workflows provide flexibility, they suffer from performance degradation and prohibitive latency, respectively. To resolve this dilemma, we propose Search-and-Replace Infilling (SRI), a framework that internalizes the agentic verification-and-editing mechanism into a unified, single-pass inference process. By structurally grounding edits via an explicit search phase, SRI harmonizes completion tasks with the instruction-following priors of Chat LLMs, extending the paradigm from static infilling to dynamic context-aware editing. We synthesize a high-quality dataset, SRI-200K, and fine-tune the SRI-Coder series. Extensive evaluations demonstrate that with minimal data (20k samples), SRI-Coder enables Chat models to surpass the completion performance of their Base counterparts. Crucially, unlike FIM-style tuning, SRI preserves general coding competencies and maintains inference latency comparable to standard FIM. We empower the entire Qwen3-Coder series with SRI, encouraging the developer community to leverage this framework for advanced auto-completion and assisted development.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
Multi-Step Visual Reasoning with Visual Tokens Scaling and Verification
Jun 08, 2025Multi-modal large language models (MLLMs) have achieved remarkable capabilities by integrating visual perception with language understanding, enabling applications such as image-grounded dialogue, visual question answering, and scientific analysis. However, most MLLMs adopt a static inference paradigm, encoding the entire image into fixed visual tokens upfront, which limits their ability to iteratively refine understanding or adapt to context during inference. This contrasts sharply with human perception, which is dynamic, selective, and feedback-driven. In this work, we introduce a novel framework for inference-time visual token scaling that enables MLLMs to perform iterative, verifier-guided reasoning over visual content. We formulate the problem as a Markov Decision Process, involving a reasoner that proposes visual actions and a verifier, which is trained via multi-step Direct Preference Optimization (DPO), that evaluates these actions and determines when reasoning should terminate. To support this, we present a new dataset, VTS, comprising supervised reasoning trajectories (VTS-SFT) and preference-labeled reasoning comparisons (VTS-DPO). Our method significantly outperforms existing approaches across diverse visual reasoning benchmarks, offering not only improved accuracy but also more interpretable and grounded reasoning processes. These results demonstrate the promise of dynamic inference mechanisms for enabling fine-grained, context-aware visual reasoning in next-generation MLLMs.
Hallucination at a Glance: Controlled Visual Edits and Fine-Grained Multimodal Learning
Jun 08, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks but still struggle with fine-grained visual differences, leading to hallucinations or missed semantic shifts. We attribute this to limitations in both training data and learning objectives. To address these issues, we propose a controlled data generation pipeline that produces minimally edited image pairs with semantically aligned captions. Using this pipeline, we construct the Micro Edit Dataset (MED), containing over 50K image-text pairs spanning 11 fine-grained edit categories, including attribute, count, position, and object presence changes. Building on MED, we introduce a supervised fine-tuning (SFT) framework with a feature-level consistency loss that promotes stable visual embeddings under small edits. We evaluate our approach on the Micro Edit Detection benchmark, which includes carefully balanced evaluation pairs designed to test sensitivity to subtle visual variations across the same edit categories. Our method improves difference detection accuracy and reduces hallucinations compared to strong baselines, including GPT-4o. Moreover, it yields consistent gains on standard vision-language tasks such as image captioning and visual question answering. These results demonstrate the effectiveness of combining targeted data and alignment objectives for enhancing fine-grained visual reasoning in MLLMs.
Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
Apr 19, 2025The composition of pre-training datasets for large language models (LLMs) remains largely undisclosed, hindering transparency and efforts to optimize data quality, a critical driver of model performance. Current data selection methods, such as natural language quality assessments, diversity-based filters, and classifier-based approaches, are limited by single-dimensional evaluation or redundancy-focused strategies. To address these gaps, we propose PRRC to evaluate data quality across Professionalism, Readability, Reasoning, and Cleanliness. We further introduce Meta-rater, a multi-dimensional data selection method that integrates these dimensions with existing quality metrics through learned optimal weightings. Meta-rater employs proxy models to train a regression model that predicts validation loss, enabling the identification of optimal combinations of quality scores. Experiments demonstrate that Meta-rater doubles convergence speed for 1.3B parameter models and improves downstream task performance by 3.23, with scalable benefits observed in 3.3B models trained on 100B tokens. Additionally, we release the annotated SlimPajama-627B dataset, labeled across 25 quality metrics (including PRRC), to advance research in data-centric LLM development. Our work establishes that holistic, multi-dimensional quality integration significantly outperforms conventional single-dimension approaches, offering a scalable paradigm for enhancing pre-training efficiency and model capability.
Unsupervised Topic Models are Data Mixers for Pre-training Language Models
Feb 24, 2025The performance of large language models (LLMs) is significantly affected by the quality and composition of their pre-training data, which is inherently diverse, spanning various domains, sources, and topics. Effectively integrating these heterogeneous data sources is crucial for optimizing LLM performance. Previous research has predominantly concentrated on domain-based data mixing, often neglecting the nuanced topic-level characteristics of the data. To address this gap, we propose a simple yet effective topic-based data mixing strategy that utilizes fine-grained topics generated through our topic modeling method, DataWeave. DataWeave employs a multi-stage clustering process to group semantically similar documents and utilizes LLMs to generate detailed topics, thereby facilitating a more nuanced understanding of dataset composition. Our strategy employs heuristic methods to upsample or downsample specific topics, which significantly enhances LLM performance on downstream tasks, achieving superior results compared to previous, more complex data mixing approaches. Furthermore, we confirm that the topics Science and Relationships are particularly effective, yielding the most substantial performance improvements. We will make our code and datasets publicly available.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024
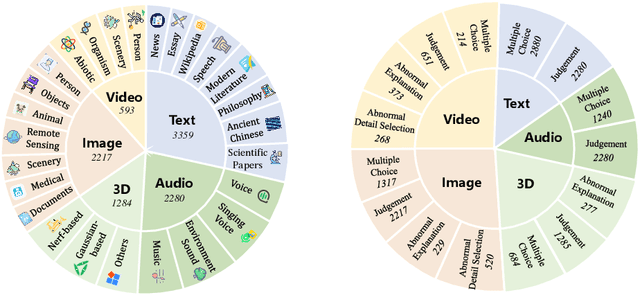

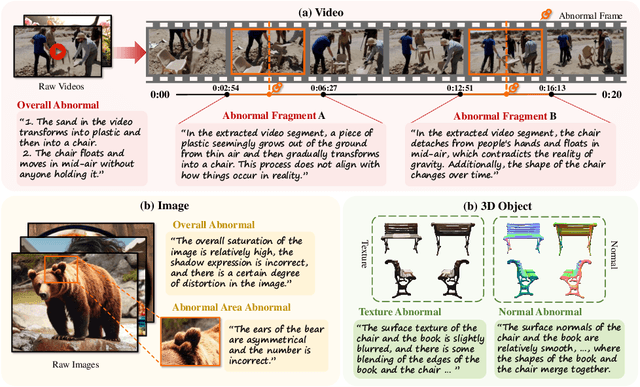
With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
Oct 10, 2024



Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pretraining. To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process. We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.