 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
Apr 19, 2025The composition of pre-training datasets for large language models (LLMs) remains largely undisclosed, hindering transparency and efforts to optimize data quality, a critical driver of model performance. Current data selection methods, such as natural language quality assessments, diversity-based filters, and classifier-based approaches, are limited by single-dimensional evaluation or redundancy-focused strategies. To address these gaps, we propose PRRC to evaluate data quality across Professionalism, Readability, Reasoning, and Cleanliness. We further introduce Meta-rater, a multi-dimensional data selection method that integrates these dimensions with existing quality metrics through learned optimal weightings. Meta-rater employs proxy models to train a regression model that predicts validation loss, enabling the identification of optimal combinations of quality scores. Experiments demonstrate that Meta-rater doubles convergence speed for 1.3B parameter models and improves downstream task performance by 3.23, with scalable benefits observed in 3.3B models trained on 100B tokens. Additionally, we release the annotated SlimPajama-627B dataset, labeled across 25 quality metrics (including PRRC), to advance research in data-centric LLM development. Our work establishes that holistic, multi-dimensional quality integration significantly outperforms conventional single-dimension approaches, offering a scalable paradigm for enhancing pre-training efficiency and model capability.
Unsupervised Topic Models are Data Mixers for Pre-training Language Models
Feb 24, 2025The performance of large language models (LLMs) is significantly affected by the quality and composition of their pre-training data, which is inherently diverse, spanning various domains, sources, and topics. Effectively integrating these heterogeneous data sources is crucial for optimizing LLM performance. Previous research has predominantly concentrated on domain-based data mixing, often neglecting the nuanced topic-level characteristics of the data. To address this gap, we propose a simple yet effective topic-based data mixing strategy that utilizes fine-grained topics generated through our topic modeling method, DataWeave. DataWeave employs a multi-stage clustering process to group semantically similar documents and utilizes LLMs to generate detailed topics, thereby facilitating a more nuanced understanding of dataset composition. Our strategy employs heuristic methods to upsample or downsample specific topics, which significantly enhances LLM performance on downstream tasks, achieving superior results compared to previous, more complex data mixing approaches. Furthermore, we confirm that the topics Science and Relationships are particularly effective, yielding the most substantial performance improvements. We will make our code and datasets publicly available.
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
Oct 10, 2024



Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pretraining. To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process. We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.
DSDL: Data Set Description Language for Bridging Modalities and Tasks in AI Data
May 28, 2024In the era of artificial intelligence, the diversity of data modalities and annotation formats often renders data unusable directly, requiring understanding and format conversion before it can be used by researchers or developers with different needs. To tackle this problem, this article introduces a framework called Dataset Description Language (DSDL) that aims to simplify dataset processing by providing a unified standard for AI datasets. DSDL adheres to the three basic practical principles of generic, portable, and extensible, using a unified standard to express data of different modalities and structures, facilitating the dissemination of AI data, and easily extending to new modalities and tasks. The standardized specifications of DSDL reduce the workload for users in data dissemination, processing, and usage. To further improve user convenience, we provide predefined DSDL templates for various tasks, convert mainstream datasets to comply with DSDL specifications, and provide comprehensive documentation and DSDL tools. These efforts aim to simplify the use of AI data, thereby improving the efficiency of AI development.
FoundaBench: Evaluating Chinese Fundamental Knowledge Capabilities of Large Language Models
Apr 29, 2024In the burgeoning field of large language models (LLMs), the assessment of fundamental knowledge remains a critical challenge, particularly for models tailored to Chinese language and culture. This paper introduces FoundaBench, a pioneering benchmark designed to rigorously evaluate the fundamental knowledge capabilities of Chinese LLMs. FoundaBench encompasses a diverse array of 3354 multiple-choice questions across common sense and K-12 educational subjects, meticulously curated to reflect the breadth and depth of everyday and academic knowledge. We present an extensive evaluation of 12 state-of-the-art LLMs using FoundaBench, employing both traditional assessment methods and our CircularEval protocol to mitigate potential biases in model responses. Our results highlight the superior performance of models pre-trained on Chinese corpora, and reveal a significant disparity between models' reasoning and memory recall capabilities. The insights gleaned from FoundaBench evaluations set a new standard for understanding the fundamental knowledge of LLMs, providing a robust framework for future advancements in the field.
Advanced Unstructured Data Processing for ESG Reports: A Methodology for Structured Transformation and Enhanced Analysis
Jan 04, 2024In the evolving field of corporate sustainability, analyzing unstructured Environmental, Social, and Governance (ESG) reports is a complex challenge due to their varied formats and intricate content. This study introduces an innovative methodology utilizing the "Unstructured Core Library", specifically tailored to address these challenges by transforming ESG reports into structured, analyzable formats. Our approach significantly advances the existing research by offering high-precision text cleaning, adept identification and extraction of text from images, and standardization of tables within these reports. Emphasizing its capability to handle diverse data types, including text, images, and tables, the method adeptly manages the nuances of differing page layouts and report styles across industries. This research marks a substantial contribution to the fields of industrial ecology and corporate sustainability assessment, paving the way for the application of advanced NLP technologies and large language models in the analysis of corporate governance and sustainability. Our code is available at https://github.com/linancn/TianGong-AI-Unstructure.git.
VIGC: Visual Instruction Generation and Correction
Sep 11, 2023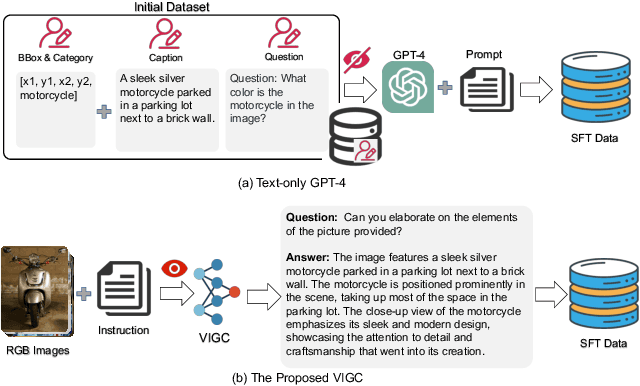

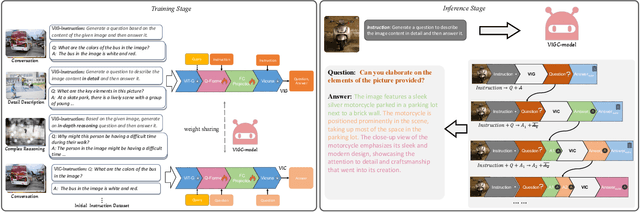

The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code are available at https://opendatalab.github.io/VIGC.