 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarGym: Benchmarking Deep Research Workflows on Academic Literature Retrieval
Jan 29, 2026Tool-augmented large language models have advanced from single-turn question answering to deep research workflows that iteratively plan queries, invoke external tools, and synthesize information to address complex information needs. Evaluating such workflows presents a fundamental challenge: reliance on live APIs introduces non-determinism, as tool invocations may yield different results across runs due to temporal drift, rate limiting, and evolving backend states. This variance undermines reproducibility and invalidates cross-system comparisons. We present ScholarGym, a simulation environment for reproducible evaluation of deep research workflows on academic literature. The environment decouples workflow components into query planning, tool invocation, and relevance assessment, enabling fine-grained analysis of each stage under controlled conditions. Built on a static corpus of 570K papers with deterministic retrieval, ScholarGym provides 2,536 queries with expert-annotated ground truth. Experiments across diverse backbone models reveal how reasoning capabilities, planning strategies, and selection mechanisms interact over iterative refinement.
Lightweight Dynamic Modeling of Cable-Driven Continuum Robots Based on Actuation-Space Energy Formulation
Dec 15, 2025



Cable-driven continuum robots (CDCRs) require accurate, real-time dynamic models for high-speed dynamics prediction or model-based control, making such capability an urgent need. In this paper, we propose the Lightweight Actuation-Space Energy Modeling (LASEM) framework for CDCRs, which formulates actuation potential energy directly in actuation space to enable lightweight yet accurate dynamic modeling. Through a unified variational derivation, the governing dynamics reduce to a single partial differential equation (PDE), requiring only the Euler moment balance while implicitly incorporating the Newton force balance. By also avoiding explicit computation of cable-backbone contact forces, the formulation simplifies the model structure and improves computational efficiency while preserving geometric accuracy and physical consistency. Importantly, the proposed framework for dynamic modeling natively supports both force-input and displacement-input actuation modes, a capability seldom achieved in existing dynamic formulations. Leveraging this lightweight structure, a Galerkin space-time modal discretization with analytical time-domain derivatives of the reduced state further enables an average 62.3% computational speedup over state-of-the-art real-time dynamic modeling approaches.
Segment Any RGB-Thermal Model with Language-aided Distillation
May 04, 2025The recent Segment Anything Model (SAM) demonstrates strong instance segmentation performance across various downstream tasks. However, SAM is trained solely on RGB data, limiting its direct applicability to RGB-thermal (RGB-T) semantic segmentation. Given that RGB-T provides a robust solution for scene understanding in adverse weather and lighting conditions, such as low light and overexposure, we propose a novel framework, SARTM, which customizes the powerful SAM for RGB-T semantic segmentation. Our key idea is to unleash the potential of SAM while introduce semantic understanding modules for RGB-T data pairs. Specifically, our framework first involves fine tuning the original SAM by adding extra LoRA layers, aiming at preserving SAM's strong generalization and segmentation capabilities for downstream tasks. Secondly, we introduce language information as guidance for training our SARTM. To address cross-modal inconsistencies, we introduce a Cross-Modal Knowledge Distillation(CMKD) module that effectively achieves modality adaptation while maintaining its generalization capabilities. This semantic module enables the minimization of modality gaps and alleviates semantic ambiguity, facilitating the combination of any modality under any visual conditions. Furthermore, we enhance the segmentation performance by adjusting the segmentation head of SAM and incorporating an auxiliary semantic segmentation head, which integrates multi-scale features for effective fusion. Extensive experiments are conducted across three multi-modal RGBT semantic segmentation benchmarks: MFNET, PST900, and FMB. Both quantitative and qualitative results consistently demonstrate that the proposed SARTM significantly outperforms state-of-the-art approaches across a variety of conditions.
Learning Class Prototypes for Unified Sparse Supervised 3D Object Detection
Mar 27, 2025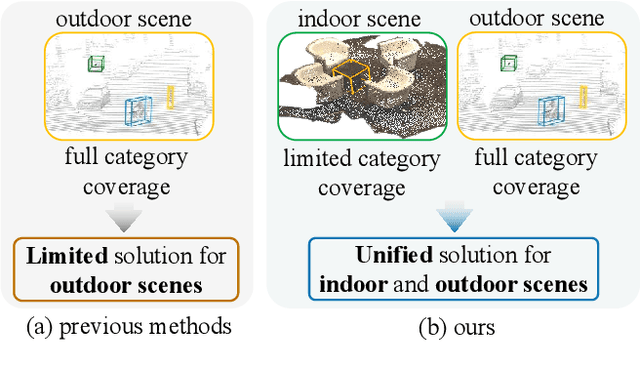
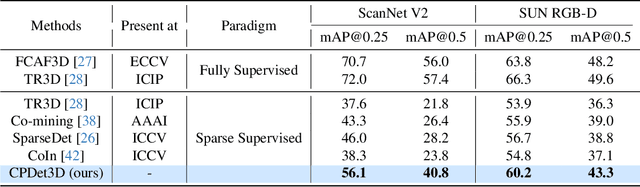
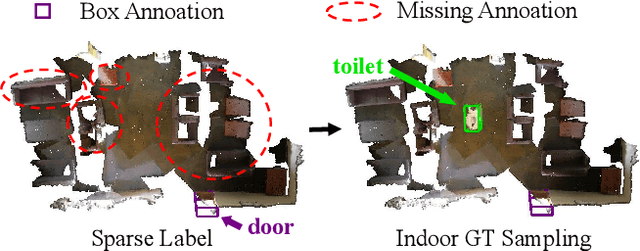
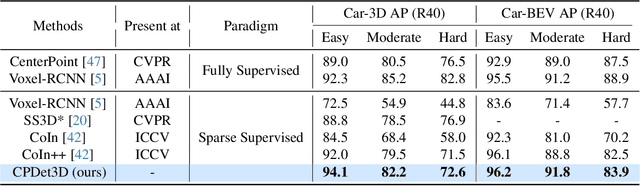
Both indoor and outdoor scene perceptions are essential for embodied intelligence. However, current sparse supervised 3D object detection methods focus solely on outdoor scenes without considering indoor settings. To this end, we propose a unified sparse supervised 3D object detection method for both indoor and outdoor scenes through learning class prototypes to effectively utilize unlabeled objects. Specifically, we first propose a prototype-based object mining module that converts the unlabeled object mining into a matching problem between class prototypes and unlabeled features. By using optimal transport matching results, we assign prototype labels to high-confidence features, thereby achieving the mining of unlabeled objects. We then present a multi-label cooperative refinement module to effectively recover missed detections through pseudo label quality control and prototype label cooperation. Experiments show that our method achieves state-of-the-art performance under the one object per scene sparse supervised setting across indoor and outdoor datasets. With only one labeled object per scene, our method achieves about 78%, 90%, and 96% performance compared to the fully supervised detector on ScanNet V2, SUN RGB-D, and KITTI, respectively, highlighting the scalability of our method. Code is available at https://github.com/zyrant/CPDet3D.
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
Feb 07, 2025The astonishing performance of large language models (LLMs) and their remarkable achievements in production and daily life have led to their widespread application in collaborative tasks. However, current large models face challenges such as hallucination and lack of specificity in content generation in vertical domain tasks. Inspired by the contrast and classification mechanisms in human cognitive processes, this paper constructs an adversarial learning-based prompt framework named ChallengeMe, which includes three cascaded solutions: generation prompts, evaluation prompts, and feedback optimization. In this process, we designed seven core optimization dimensions and set the threshold for adversarial learning. The results of mixed case studies on the text summarization task show that the proposed framework can generate more accurate and fluent text summaries compared to the current advanced mainstream LLMs.
Deep Learning Waveform Modeling for Wideband Optical Fiber Channel Transmission: Challenges and Potential Solutions
Jan 14, 2025



Fast and accurate optical fiber communication simulation system are crucial for optimizing optical networks, developing digital signal processing algorithms, and performing end-to-end (E2E) optimization. Deep learning (DL) has emerged as a valuable tool to reduce the complexity of traditional waveform simulation methods, such as split-step Fourier method (SSFM). DL-based schemes have achieved high accuracy and low complexity fiber channel waveform modeling as its strong nonlinear fitting ability and high efficiency in parallel computation. However, DL-based schemes are mainly utilized in single-channel and few-channel wavelength division multiplexing (WDM) systems. The applicability of DL-based schemes in wideband WDM systems remains uncertain due to the lack of comparison under consistent standards and scenarios. In this paper, we propose a DSP-assisted accuracy evaluation method to evaluate the performance for DL-based schemes, from the aspects of waveform and quality of transmission (QoT) errors. We compare the performance of five various DL-based schemes and valid the effectiveness of DSP-assisted method in WDM systems. Results suggest that feature decoupled distributed (FDD) achieves the better accuracy, especially in large-channel and high-rate scenarios. Furthermore, we find that the accuracy of FDD still exhibit significant degradation with the number of WDM channels and transmission rates exceeds 15 and 100 GBaud, indicating challenges for wideband applications. We further analyze the reasons of performance degradation from the perspective of increased linearity and nonlinearity and discuss potential solutions including further decoupling scheme designs and improvement in DL models. Despite DL-based schemes remain challenges in wideband WDM systems, they have strong potential for high-accuracy and low-complexity optical fiber channel waveform modeling.
TDCNet: Transparent Objects Depth Completion with CNN-Transformer Dual-Branch Parallel Network
Dec 19, 2024



The sensing and manipulation of transparent objects present a critical challenge in industrial and laboratory robotics. Conventional sensors face challenges in obtaining the full depth of transparent objects due to the refraction and reflection of light on their surfaces and their lack of visible texture. Previous research has attempted to obtain complete depth maps of transparent objects from RGB and damaged depth maps (collected by depth sensor) using deep learning models. However, existing methods fail to fully utilize the original depth map, resulting in limited accuracy for deep completion. To solve this problem, we propose TDCNet, a novel dual-branch CNN-Transformer parallel network for transparent object depth completion. The proposed framework consists of two different branches: one extracts features from partial depth maps, while the other processes RGB-D images. Experimental results demonstrate that our model achieves state-of-the-art performance across multiple public datasets. Our code and the pre-trained model are publicly available at https://github.com/XianghuiFan/TDCNet.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
PTQ4RIS: Post-Training Quantization for Referring Image Segmentation
Sep 25, 2024Referring Image Segmentation (RIS), aims to segment the object referred by a given sentence in an image by understanding both visual and linguistic information. However, existing RIS methods tend to explore top-performance models, disregarding considerations for practical applications on resources-limited edge devices. This oversight poses a significant challenge for on-device RIS inference. To this end, we propose an effective and efficient post-training quantization framework termed PTQ4RIS. Specifically, we first conduct an in-depth analysis of the root causes of performance degradation in RIS model quantization and propose dual-region quantization (DRQ) and reorder-based outlier-retained quantization (RORQ) to address the quantization difficulties in visual and text encoders. Extensive experiments on three benchmarks with different bits settings (from 8 to 4 bits) demonstrates its superior performance. Importantly, we are the first PTQ method specifically designed for the RIS task, highlighting the feasibility of PTQ in RIS applications. Code will be available at {https://github.com/gugu511yy/PTQ4RIS}.