 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBending the Scaling Law Curve in Large-Scale Recommendation Systems
Feb 19, 2026Learning from user interaction history through sequential models has become a cornerstone of large-scale recommender systems. Recent advances in large language models have revealed promising scaling laws, sparking a surge of research into long-sequence modeling and deeper architectures for recommendation tasks. However, many recent approaches rely heavily on cross-attention mechanisms to address the quadratic computational bottleneck in sequential modeling, which can limit the representational power gained from self-attention. We present ULTRA-HSTU, a novel sequential recommendation model developed through end-to-end model and system co-design. By innovating in the design of input sequences, sparse attention mechanisms, and model topology, ULTRA-HSTU achieves substantial improvements in both model quality and efficiency. Comprehensive benchmarking demonstrates that ULTRA-HSTU achieves remarkable scaling efficiency gains -- over 5x faster training scaling and 21x faster inference scaling compared to conventional models -- while delivering superior recommendation quality. Our solution is fully deployed at scale, serving billions of users daily and driving significant 4% to 8% consumption and engagement improvements in real-world production environments.
ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
Async Learned User Embeddings for Ads Delivery Optimization
Jun 09, 2024



User representation is crucial for recommendation systems as it helps to deliver personalized recommendations by capturing user preferences and behaviors in low-dimensional vectors. High-quality user embeddings can capture subtle preferences, enable precise similarity calculations, and adapt to changing preferences over time to maintain relevance. The effectiveness of recommendation systems depends significantly on the quality of user embedding. We propose to asynchronously learn high fidelity user embeddings for billions of users each day from sequence based multimodal user activities in Meta platforms through a Transformer-like large scale feature learning module. The async learned user representations embeddings (ALURE) are further converted to user similarity graphs through graph learning and then combined with user realtime activities to retrieval highly related ads candidates for the entire ads delivery system. Our method shows significant gains in both offline and online experiments.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023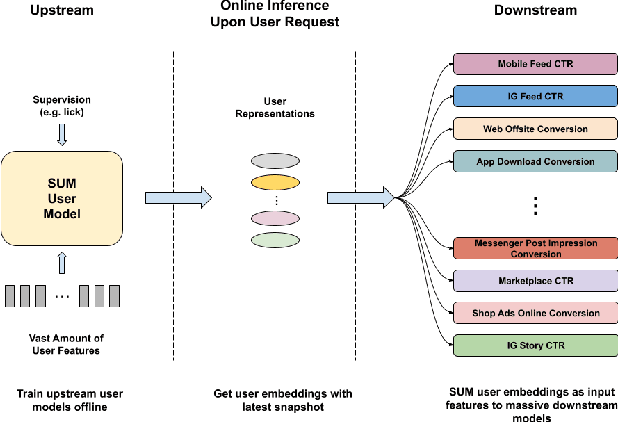
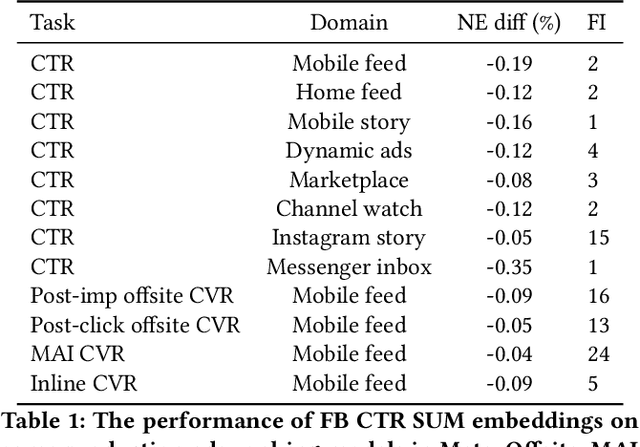
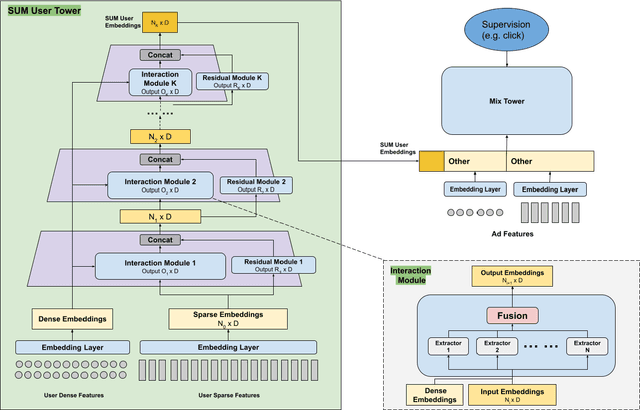

Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.
A Self-Regulated and Reconfigurable CMOS Physically Unclonable Function Featuring Zero-Overhead Stabilization
Jul 07, 2021
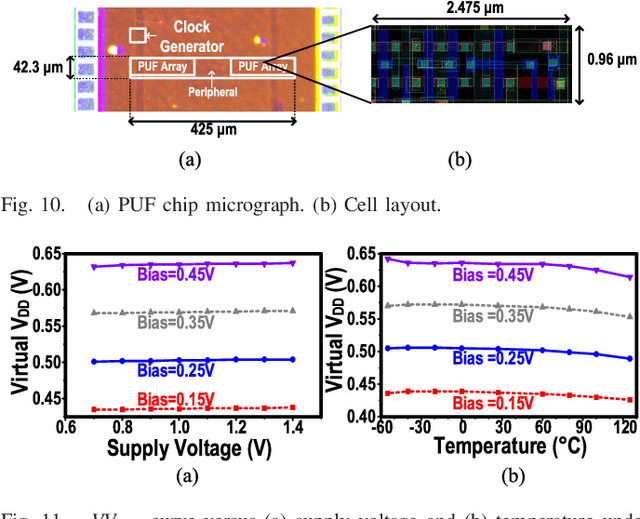
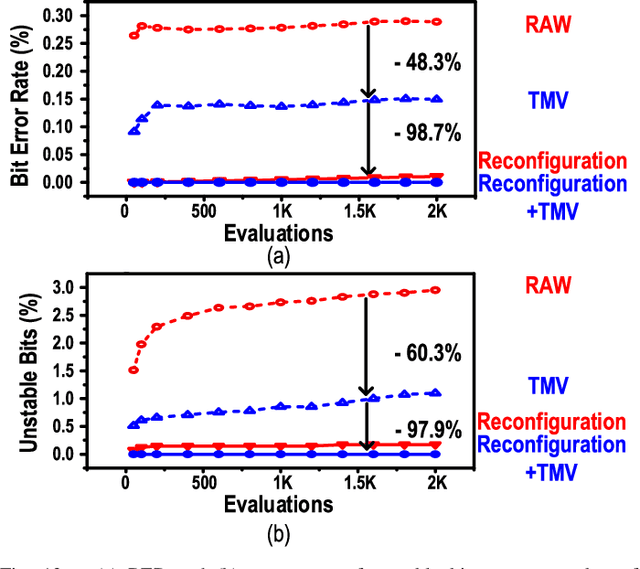
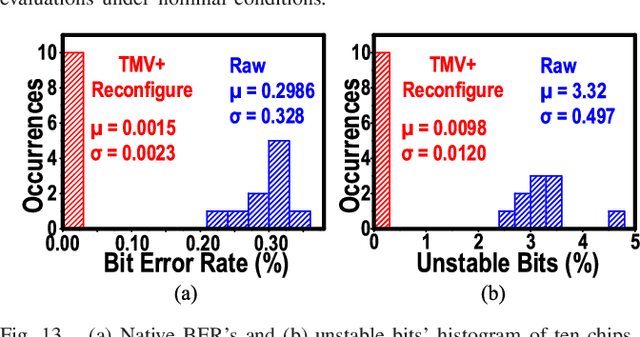
This article presents a reconfigurable physically unclonable function (PUF) design fabricated using 65-nm CMOS technology. A subthreshold-inverter-based static PUF cell achieves 0.3% native bit error rate (BER) at 0.062-fJ per bit core energy efficiency. A flexible, native transistor-based voltage regulation scheme achieves low-overhead supply regulation with 6-mV/V line sensitivity, making the PUF resistant against voltage variations. Additionally, the PUF cell is designed to be reconfigurable with no area overhead, which enables stabilization without redundancy on chip. Thanks to the highly stable and self-regulated PUF cell and the zero-overhead stabilization scheme, a 0.00182% native BER is obtained after reconfiguration. The proposed design shows 0.12%/10 {\deg}C and 0.057%/0.1-V bit error across the military-grade temperature range from -55 {\deg}C to 125 {\deg}C and supply voltage variation from 0.7 to 1.4 V. The total energy per bit is 15.3 fJ. Furthermore, the unstable bits can be detected by sweeping the body bias instead of temperature during enrollment, thereby significantly reducing the testing costs. Last but not least, the prototype exhibits almost ideal uniqueness and randomness, with a mean inter-die Hamming distance (HD) of 0.4998 and a 1020x inter-/intra-die HD separation. It also passes both NIST 800-22 and 800-90B randomness tests.
* This work has been accepted by 2020 IEEE Journal of Solid-State Circuits (JSSC)
CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference
Jul 06, 2021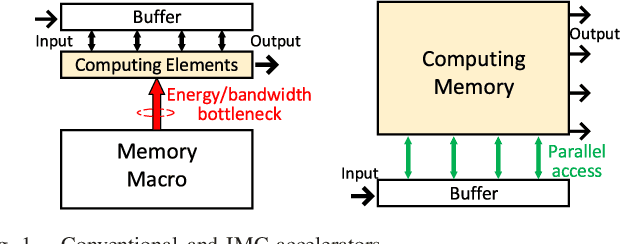
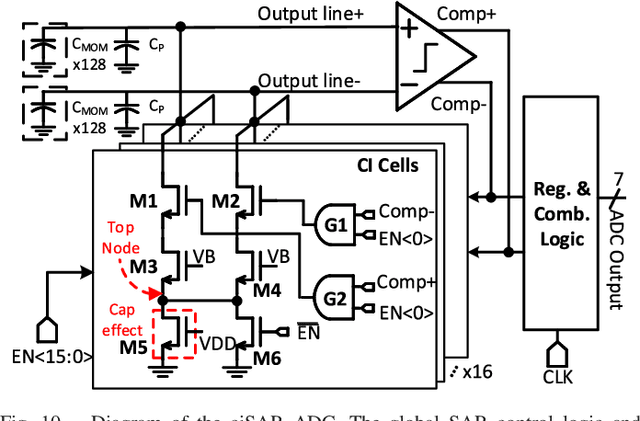
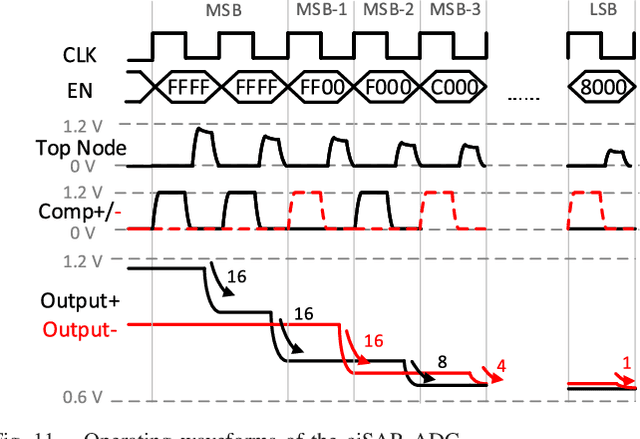
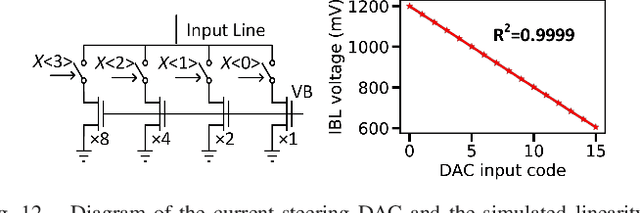
A compact, accurate, and bitwidth-programmable in-memory computing (IMC) static random-access memory (SRAM) macro, named CAP-RAM, is presented for energy-efficient convolutional neural network (CNN) inference. It leverages a novel charge-domain multiply-and-accumulate (MAC) mechanism and circuitry to achieve superior linearity under process variations compared to conventional IMC designs. The adopted semi-parallel architecture efficiently stores filters from multiple CNN layers by sharing eight standard 6T SRAM cells with one charge-domain MAC circuit. Moreover, up to six levels of bit-width of weights with two encoding schemes and eight levels of input activations are supported. A 7-bit charge-injection SAR (ciSAR) analog-to-digital converter (ADC) getting rid of sample and hold (S&H) and input/reference buffers further improves the overall energy efficiency and throughput. A 65-nm prototype validates the excellent linearity and computing accuracy of CAP-RAM. A single 512x128 macro stores a complete pruned and quantized CNN model to achieve 98.8% inference accuracy on the MNIST data set and 89.0% on the CIFAR-10 data set, with a 573.4-giga operations per second (GOPS) peak throughput and a 49.4-tera operations per second (TOPS)/W energy efficiency.
* This work has been accepted by IEEE Journal of Solid-State Circuits (JSSC 2021)
Dynamic Sampling Convolutional Neural Networks
Mar 22, 2018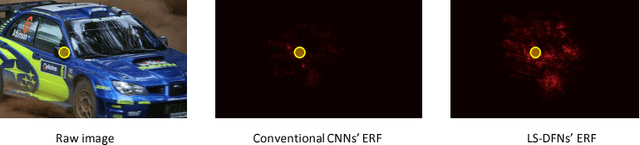
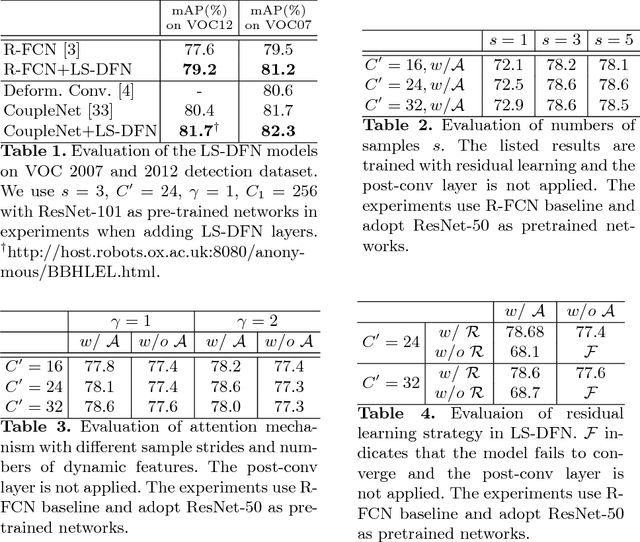
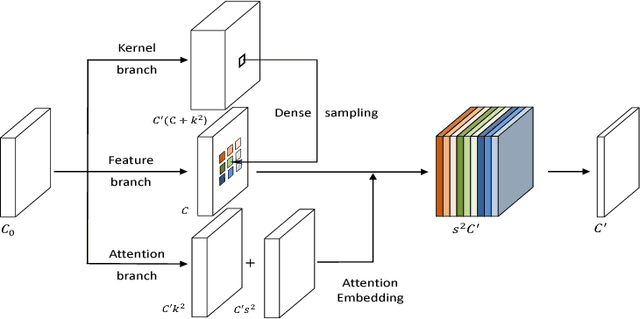
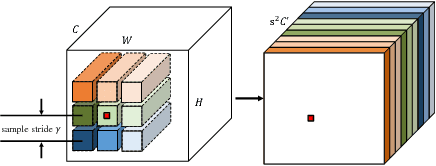
We present Dynamic Sampling Convolutional Neural Networks (DSCNN), where the position-specific kernels learn from not only the current position but also multiple sampled neighbour regions. During sampling, residual learning is introduced to ease training and an attention mechanism is applied to fuse features from different samples. And the kernels are further factorized to reduce parameters. The multiple sampling strategy enlarges the effective receptive fields significantly without requiring more parameters. While DSCNNs inherit the advantages of DFN, namely avoiding feature map blurring by position-specific kernels while keeping translation invariance, it also efficiently alleviates the overfitting issue caused by much more parameters than normal CNNs. Our model is efficient and can be trained end-to-end via standard back-propagation. We demonstrate the merits of our DSCNNs on both sparse and dense prediction tasks involving object detection and flow estimation. Our results show that DSCNNs enjoy stronger recognition abilities and achieve 81.7% in VOC2012 detection dataset. Also, DSCNNs obtain much sharper responses in flow estimation on FlyingChairs dataset compared to multiple FlowNet models' baselines.