 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023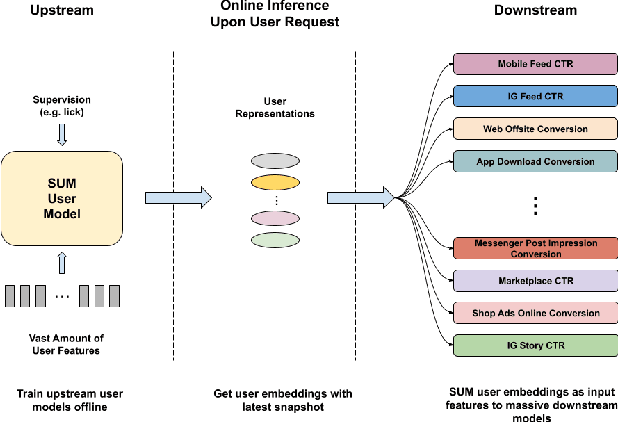
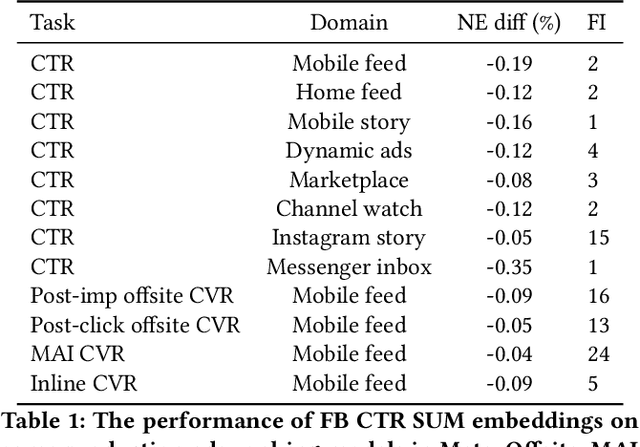
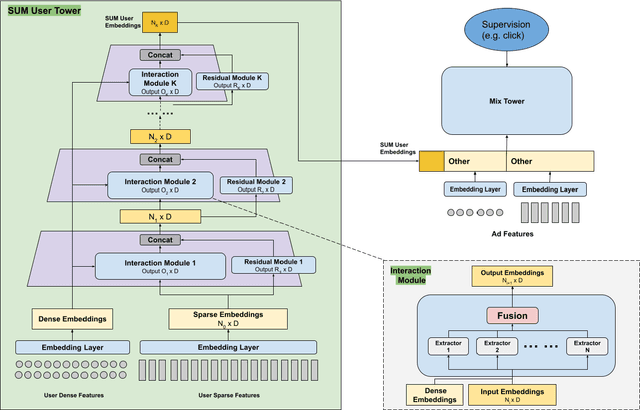

Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.