 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Models Follow Visual Instructions? VIBE: A Systematic Benchmark for Visual Instruction-Driven Image Editing
Feb 02, 2026Recent generative models have achieved remarkable progress in image editing. However, existing systems and benchmarks remain largely text-guided. In contrast, human communication is inherently multimodal, where visual instructions such as sketches efficiently convey spatial and structural intent. To address this gap, we introduce VIBE, the Visual Instruction Benchmark for Image Editing with a three-level interaction hierarchy that captures deictic grounding, morphological manipulation, and causal reasoning. Across these levels, we curate high-quality and diverse test cases that reflect progressively increasing complexity in visual instruction following. We further propose a robust LMM-as-a-judge evaluation framework with task-specific metrics to enable scalable and fine-grained assessment. Through a comprehensive evaluation of 17 representative open-source and proprietary image editing models, we find that proprietary models exhibit early-stage visual instruction-following capabilities and consistently outperform open-source models. However, performance degrades markedly with increasing task difficulty even for the strongest systems, highlighting promising directions for future research.
Nearly Optimal Bayesian Inference for Structural Missingness
Jan 27, 2026Structural missingness breaks 'just impute and train': values can be undefined by causal or logical constraints, and the mask may depend on observed variables, unobserved variables (MNAR), and other missingness indicators. It simultaneously brings (i) a catch-22 situation with causal loop, prediction needs the missing features, yet inferring them depends on the missingness mechanism, (ii) under MNAR, the unseen are different, the missing part can come from a shifted distribution, and (iii) plug-in imputation, a single fill-in can lock in uncertainty and yield overconfident, biased decisions. In the Bayesian view, prediction via the posterior predictive distribution integrates over the full model posterior uncertainty, rather than relying on a single point estimate. This framework decouples (i) learning an in-model missing-value posterior from (ii) label prediction by optimizing the predictive posterior distribution, enabling posterior integration. This decoupling yields an in-model almost-free-lunch: once the posterior is learned, prediction is plug-and-play while preserving uncertainty propagation. It achieves SOTA on 43 classification and 15 imputation benchmarks, with finite-sample near Bayes-optimality guarantees under our SCM prior.
Robust and Efficient MuJoCo-based Model Predictive Control via Web of Affine Spaces Derivatives
Dec 24, 2025



MuJoCo is a powerful and efficient physics simulator widely used in robotics. One common way it is applied in practice is through Model Predictive Control (MPC), which uses repeated rollouts of the simulator to optimize future actions and generate responsive control policies in real time. To make this process more accessible, the open source library MuJoCo MPC (MJPC) provides ready-to-use MPC algorithms and implementations built directly on top of the MuJoCo simulator. However, MJPC relies on finite differencing (FD) to compute derivatives through the underlying MuJoCo simulator, which is often a key bottleneck that can make it prohibitively costly for time-sensitive tasks, especially in high-DOF systems or complex scenes. In this paper, we introduce the use of Web of Affine Spaces (WASP) derivatives within MJPC as a drop-in replacement for FD. WASP is a recently developed approach for efficiently computing sequences of accurate derivative approximations. By reusing information from prior, related derivative calculations, WASP accelerates and stabilizes the computation of new derivatives, making it especially well suited for MPC's iterative, fine-grained updates over time. We evaluate WASP across a diverse suite of MJPC tasks spanning multiple robot embodiments. Our results suggest that WASP derivatives are particularly effective in MJPC: it integrates seamlessly across tasks, delivers consistently robust performance, and achieves up to a 2$\mathsf{x}$ speedup compared to an FD backend when used with derivative-based planners, such as iLQG. In addition, WASP-based MPC outperforms MJPC's stochastic sampling-based planners on our evaluation tasks, offering both greater efficiency and reliability. To support adoption and future research, we release an open-source implementation of MJPC with WASP derivatives fully integrated.
Rethinking generative image pretraining: How far are we from scaling up next-pixel prediction?
Nov 11, 2025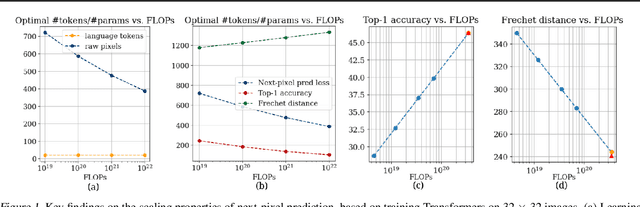

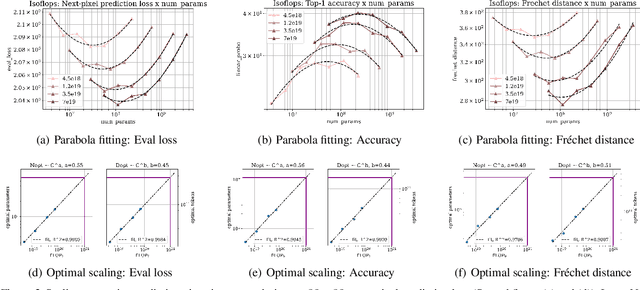
This paper investigates the scaling properties of autoregressive next-pixel prediction, a simple, end-to-end yet under-explored framework for unified vision models. Starting with images at resolutions of 32x32, we train a family of Transformers using IsoFlops profiles across compute budgets up to 7e19 FLOPs and evaluate three distinct target metrics: next-pixel prediction objective, ImageNet classification accuracy, and generation quality measured by Fr'echet Distance. First, optimal scaling strategy is critically task-dependent. At a fixed 32x32 resolution alone, the optimal scaling properties for image classification and image generation diverge, where generation optimal setup requires the data size grow three to five times faster than for the classification optimal setup. Second, as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size. Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years.
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
Coherence-based Approximate Derivatives via Web of Affine Spaces Optimization
Apr 26, 2025Computing derivatives is a crucial subroutine in computer science and related fields as it provides a local characterization of a function's steepest directions of ascent or descent. In this work, we recognize that derivatives are often not computed in isolation; conversely, it is quite common to compute a \textit{sequence} of derivatives, each one somewhat related to the last. Thus, we propose accelerating derivative computation by reusing information from previous, related calculations-a general strategy known as \textit{coherence}. We introduce the first instantiation of this strategy through a novel approach called the Web of Affine Spaces (WASP) Optimization. This approach provides an accurate approximation of a function's derivative object (i.e. gradient, Jacobian matrix, etc.) at the current input within a sequence. Each derivative within the sequence only requires a small number of forward passes through the function (typically two), regardless of the number of function inputs and outputs. We demonstrate the efficacy of our approach through several numerical experiments, comparing it with alternative derivative computation methods on benchmark functions. We show that our method significantly improves the performance of derivative computation on small to medium-sized functions, i.e., functions with approximately fewer than 500 combined inputs and outputs. Furthermore, we show that this method can be effectively applied in a robotics optimization context. We conclude with a discussion of the limitations and implications of our work. Open-source code, visual explanations, and videos are located at the paper website: \href{https://apollo-lab-yale.github.io/25-RSS-WASP-website/}{https://apollo-lab-yale.github.io/25-RSS-WASP-website/}.
ad-trait: A Fast and Flexible Automatic Differentiation Library in Rust
Apr 22, 2025



The Rust programming language is an attractive choice for robotics and related fields, offering highly efficient and memory-safe code. However, a key limitation preventing its broader adoption in these domains is the lack of high-quality, well-supported Automatic Differentiation (AD)-a fundamental technique that enables convenient derivative computation by systematically accumulating data during function evaluation. In this work, we introduce ad-trait, a new Rust-based AD library. Our implementation overloads Rust's standard floating-point type with a flexible trait that can efficiently accumulate necessary information for derivative computation. The library supports both forward-mode and reverse-mode automatic differentiation, making it the first operator-overloading AD implementation in Rust to offer both options. Additionally, ad-trait leverages Rust's performance-oriented features, such as Single Instruction, Multiple Data acceleration in forward-mode AD, to enhance efficiency. Through benchmarking experiments, we show that our library is among the fastest AD implementations across several programming languages for computing derivatives. Moreover, it is already integrated into a Rust-based robotics library, where we showcase its ability to facilitate fast optimization procedures. We conclude with a discussion of the limitations and broader implications of our work.
CRYSIM: Prediction of Symmetric Structures of Large Crystals with GPU-based Ising Machines
Apr 09, 2025Solving black-box optimization problems with Ising machines is increasingly common in materials science. However, their application to crystal structure prediction (CSP) is still ineffective due to symmetry agnostic encoding of atomic coordinates. We introduce CRYSIM, an algorithm that encodes the space group, the Wyckoff positions combination, and coordinates of independent atomic sites as separate variables. This encoding reduces the search space substantially by exploiting the symmetry in space groups. When CRYSIM is interfaced to Fixstars Amplify, a GPU-based Ising machine, its prediction performance was competitive with CALYPSO and Bayesian optimization for crystals containing more than 150 atoms in a unit cell. Although it is not realistic to interface CRYSIM to current small-scale quantum devices, it has the potential to become the standard CSP algorithm in the coming quantum age.
KDSelector: A Knowledge-Enhanced and Data-Efficient Model Selector Learning Framework for Time Series Anomaly Detection
Mar 16, 2025



Model selection has been raised as an essential problem in the area of time series anomaly detection (TSAD), because there is no single best TSAD model for the highly heterogeneous time series in real-world applications. However, despite the success of existing model selection solutions that train a classification model (especially neural network, NN) using historical data as a selector to predict the correct TSAD model for each series, the NN-based selector learning methods used by existing solutions do not make full use of the knowledge in the historical data and require iterating over all training samples, which limits the accuracy and training speed of the selector. To address these limitations, we propose KDSelector, a novel knowledge-enhanced and data-efficient framework for learning the NN-based TSAD model selector, of which three key components are specifically designed to integrate available knowledge into the selector and dynamically prune less important and redundant samples during the learning. We develop a TSAD model selection system with KDSelector as the internal, to demonstrate how users improve the accuracy and training speed of their selectors by using KDSelector as a plug-and-play module. Our demonstration video is hosted at https://youtu.be/2uqupDWvTF0.
LLMs Can Generate a Better Answer by Aggregating Their Own Responses
Mar 06, 2025Large Language Models (LLMs) have shown remarkable capabilities across tasks, yet they often require additional prompting techniques when facing complex problems. While approaches like self-correction and response selection have emerged as popular solutions, recent studies have shown these methods perform poorly when relying on the LLM itself to provide feedback or selection criteria. We argue this limitation stems from the fact that common LLM post-training procedures lack explicit supervision for discriminative judgment tasks. In this paper, we propose Generative Self-Aggregation (GSA), a novel prompting method that improves answer quality without requiring the model's discriminative capabilities. GSA first samples multiple diverse responses from the LLM, then aggregates them to obtain an improved solution. Unlike previous approaches, our method does not require the LLM to correct errors or compare response quality; instead, it leverages the model's generative abilities to synthesize a new response based on the context of multiple samples. While GSA shares similarities with the self-consistency (SC) approach for response aggregation, SC requires specific verifiable tokens to enable majority voting. In contrast, our approach is more general and can be applied to open-ended tasks. Empirical evaluation demonstrates that GSA effectively improves response quality across various tasks, including mathematical reasoning, knowledge-based problems, and open-ended generation tasks such as code synthesis and conversational responses.