 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActWorld: From Explorable to Interactive World Model via Action-Aware Memory
Jun 16, 2026Interactive world models aim to simulate environment dynamics under real-time user actions. However, their action vocabulary is largely confined to navigation: most actions correspond to motion (e.g., walk, turn, look around), while interaction with objects in the scene (e.g., pick up plates, open doors, or trigger physical responses) is either absent, restricted to game domains, or relegated to prompt-to-full-video scenarios. The resulting worlds are visually explorable but not truly actionable. In this work, we present ActWorld, an interactive world model that extends prior navigation-centric generators to support mid-rollout object interaction within a chunk-autoregressive framework. We argue that the navigation-interaction gap stems from two bottlenecks. First, a data bottleneck: the lack of human-object interaction data with accurate, dense labels. Second, a memory bottleneck: recency-biased history compression in existing world models discards the event-transition frames that causally determine subsequent object states, leading to an action-forgetting pathology. On the data side, we construct a 100K interaction video dataset, each annotated with per-chunk captions via chain-of-thought reasoning. On the model side, we introduce a hierarchical action-aware memory design that routes history compression by interaction importance, complemented by a persistent memory bank that maintains event-update and object-identity tokens across long rollouts. Experiments show that ActWorld supports both flexible navigation and rich object interaction within a single model, substantially improving interaction fidelity over navigation-only baselines without sacrificing viewpoint control. Project page is available at https://interactwm.github.io/ActWorld.
PithTrain: A Compact and Agent-Native MoE Training System
May 29, 2026Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have built optimized MoE training stacks over years of engineering effort. Yet evolving these stacks for new architectures and system optimizations remains expensive. With the rise of AI coding agents, they could automate parts of training-framework development and accelerate this evolution. But applying them to these existing frameworks carries hidden costs, invisible to today's throughput-only evaluations. We name this missing dimension agent-task efficiency (ATE): the cost of using coding agents to understand, operate, and extend a framework. Grounded in four agent-native design principles, we build PithTrain, a compact, agent-native MoE training framework. We further introduce ATE-Bench, covering real-world training-framework tasks. Our evaluation shows PithTrain matches the throughput of production frameworks, and on ATE-Bench, PithTrain enables higher agent-task efficiency, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
May 07, 2026We study auto research as a closed empirical loop driven by external measurement. Each submitted trial carries a hypothesis, an executable code edit, an evaluator-owned outcome, and feedback that shapes the next proposal. The output is not a generated paper or a single model checkpoint, but an auditable trajectory of proposals, code diffs, experiments, scores, and failure labels. We instantiate this loop with specialist agents that partition recipe surfaces and share measured lineage across trials. The central empirical finding is that lineage feedback lets agents turn evaluator outcomes, including crashes, budget overruns, size failures, and accuracy-gate misses, into later program-level recipe edits rather than one-shot suggestions. Across 1,197 headline-run trials plus 600 Parameter Golf control trials after one-time setup and launch, humans did not choose proposals, edit recipes, override scores, or repair failed trials during the search. In the three headline runs, the same submitted-trial loop reduces Parameter Golf validation bpb by $0.81\%$, raises NanoChat-D12 CORE by $38.7\%$, and reduces CIFAR-10 Airbench96 wallclock by $4.59\%$, with each task measured by its own external evaluator and legality checks. The trace includes a strict architecture-domain audit of 157 headline-run submissions and program rewrites such as a NanoChat attention-kernel path change. Within this scope the loop autonomously writes code, submits experiments, absorbs feedback, applies and combines known techniques inside each environment, and improves public starting recipes.
Privatar: Scalable Privacy-preserving Multi-user VR via Secure Offloading
Apr 19, 2026Multi-user virtual reality enables immersive interaction. However, rendering avatars for numerous participants on each headset incurs prohibitive computational overhead, limiting scalability. We introduce a framework, Privatar, to offload avatar reconstruction from headset to untrusted devices within the same local network while safeguarding attacks against adversaries capable of intercepting offloaded data. Privatar's key insight is that domain-specific knowledge of avatar reconstruction enables provably private offloading at minimal cost. (1) System level. We observe avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop, and propose Horizontal Partitioning (HP) to keep high-energy frequency components on-device and offloads only low-energy components. HP offloads local computation while reducing information leakage to low-energy subsets only. (2) Privacy level. For individually offloaded, multi-dimensional signals without aggregation, worst-case local Differential Privacy requires prohibitive noise, ruining utility. We observe users' expression statistical distribution are slowly changing over time and trackable online, and hence propose Distribution-Aware Minimal Perturbation. DAMP minimizes noise based on each user's expression distribution to significantly reduce its effects on utility, retaining formal privacy guarantee. Combined, HP provides empirical privacy against expression identification attacks. DAMP further augments it to offer a formal guarantee against arbitrary adversaries. On a Meta Quest Pro, Privatar supports 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, providing a better throughout-loss Pareto frontier over quantization, sparsity and local construction baselines. Privatar provides both provable privacy guarantee and stays robust against both empirical and NN-based attacks.
NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
Benchmark Test-Time Scaling of General LLM Agents
Feb 22, 2026LLM agents are increasingly expected to function as general-purpose systems capable of resolving open-ended user requests. While existing benchmarks focus on domain-aware environments for developing specialized agents, evaluating general-purpose agents requires more realistic settings that challenge them to operate across multiple skills and tools within a unified environment. We introduce General AgentBench, a benchmark that provides such a unified framework for evaluating general LLM agents across search, coding, reasoning, and tool-use domains. Using General AgentBench, we systematically study test-time scaling behaviors under sequential scaling (iterative interaction) and parallel scaling (sampling multiple trajectories). Evaluation of ten leading LLM agents reveals a substantial performance degradation when moving from domain-specific evaluations to this general-agent setting. Moreover, we find that neither scaling methodology yields effective performance improvements in practice, due to two fundamental limitations: context ceiling in sequential scaling and verification gap in parallel scaling. Code is publicly available at https://github.com/cxcscmu/General-AgentBench.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
InstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
StoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
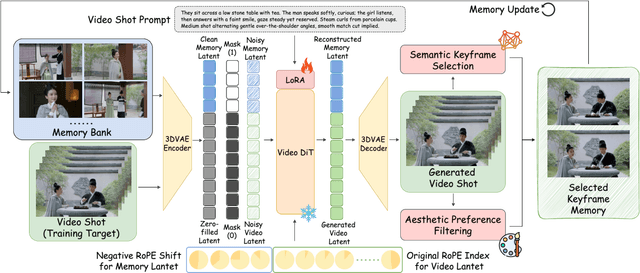

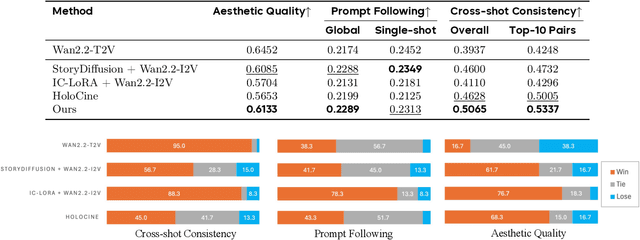
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
OckBench: Measuring the Efficiency of LLM Reasoning
Nov 07, 2025Large language models such as GPT-4, Claude 3, and the Gemini series have improved automated reasoning and code generation. However, existing benchmarks mainly focus on accuracy and output quality, and they ignore an important factor: decoding token efficiency. In real systems, generating 10,000 tokens versus 100,000 tokens leads to large differences in latency, cost, and energy. In this work, we introduce OckBench, a model-agnostic and hardware-agnostic benchmark that evaluates both accuracy and token count for reasoning and coding tasks. Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption, revealing that efficiency variance is a neglected but significant axis of differentiation. We further demonstrate Pareto frontiers over the accuracy-efficiency plane and argue for an evaluation paradigm shift: we should no longer treat tokens as "free" to multiply. OckBench provides a unified platform for measuring, comparing, and guiding research in token-efficient reasoning. Our benchmarks are available at https://ockbench.github.io/ .