 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
FiVL: A Framework for Improved Vision-Language Alignment
Dec 19, 2024



Large Vision Language Models (LVLMs) have achieved significant progress in integrating visual and textual inputs for multimodal reasoning. However, a recurring challenge is ensuring these models utilize visual information as effectively as linguistic content when both modalities are necessary to formulate an accurate answer. We hypothesize that hallucinations arise due to the lack of effective visual grounding in current LVLMs. This issue extends to vision-language benchmarks, where it is difficult to make the image indispensable for accurate answer generation, particularly in vision question-answering tasks. In this work, we introduce FiVL, a novel method for constructing datasets designed to train LVLMs for enhanced visual grounding and to evaluate their effectiveness in achieving it. These datasets can be utilized for both training and assessing an LVLM's ability to use image content as substantive evidence rather than relying solely on linguistic priors, providing insights into the model's reliance on visual information. To demonstrate the utility of our dataset, we introduce an innovative training task that outperforms baselines alongside a validation method and application for explainability. The code is available at https://github.com/IntelLabs/fivl.
FastRM: An efficient and automatic explainability framework for multimodal generative models
Dec 02, 2024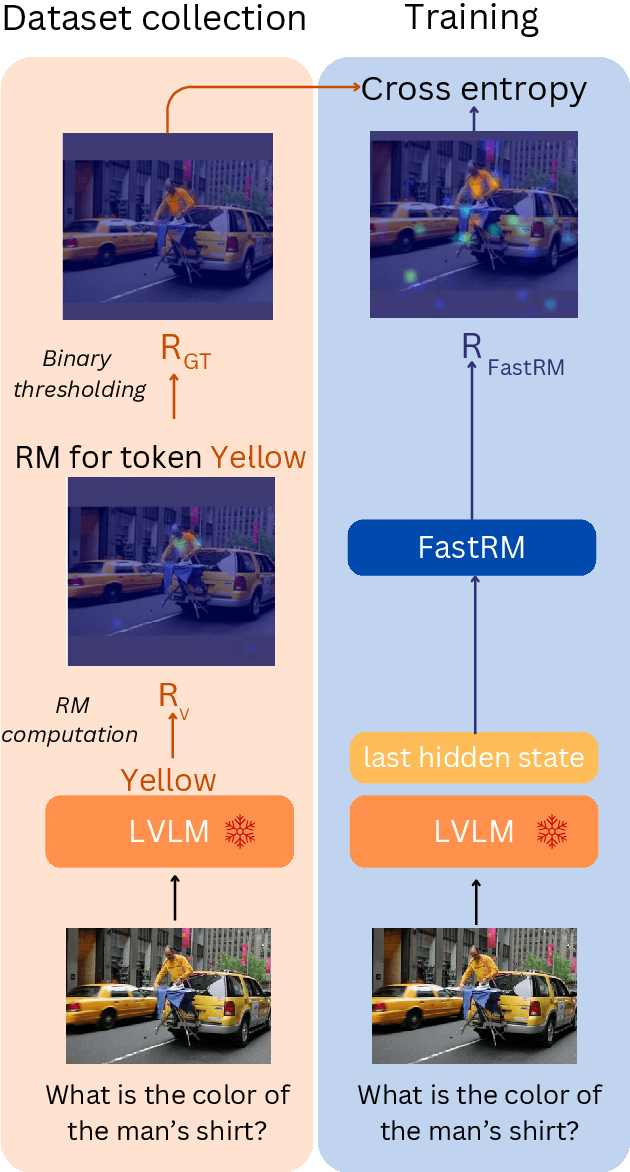
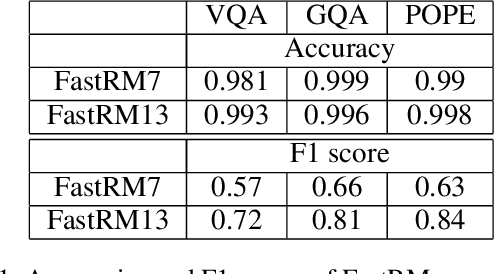
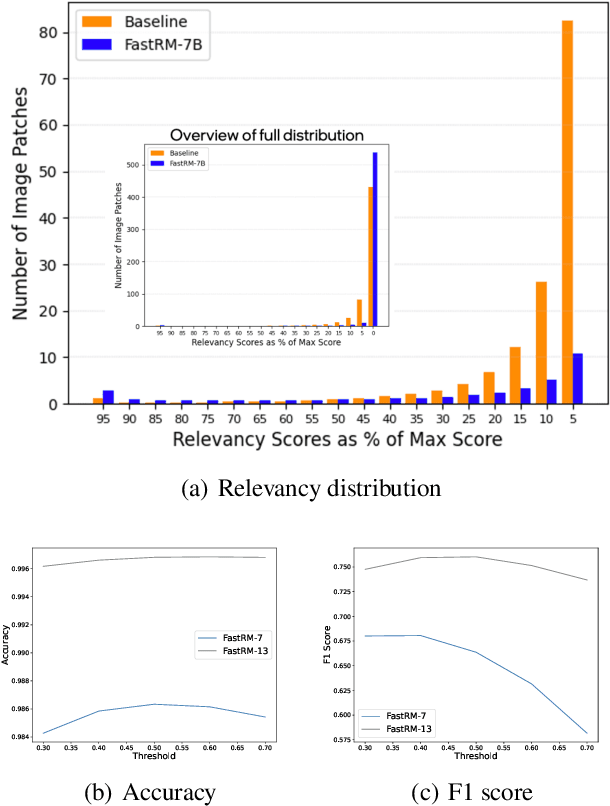
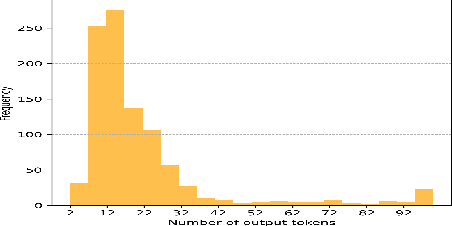
While Large Vision Language Models (LVLMs) have become masterly capable in reasoning over human prompts and visual inputs, they are still prone to producing responses that contain misinformation. Identifying incorrect responses that are not grounded in evidence has become a crucial task in building trustworthy AI. Explainability methods such as gradient-based relevancy maps on LVLM outputs can provide an insight on the decision process of models, however these methods are often computationally expensive and not suited for on-the-fly validation of outputs. In this work, we propose FastRM, an effective way for predicting the explainable Relevancy Maps of LVLM models. Experimental results show that employing FastRM leads to a 99.8% reduction in compute time for relevancy map generation and an 44.4% reduction in memory footprint for the evaluated LVLM, making explainable AI more efficient and practical, thereby facilitating its deployment in real-world applications.
Distill-SynthKG: Distilling Knowledge Graph Synthesis Workflow for Improved Coverage and Efficiency
Oct 22, 2024



Knowledge graphs (KGs) generated by large language models (LLMs) are becoming increasingly valuable for Retrieval-Augmented Generation (RAG) applications that require knowledge-intensive reasoning. However, existing KG extraction methods predominantly rely on prompt-based approaches, which are inefficient for processing large-scale corpora. These approaches often suffer from information loss, particularly with long documents, due to the lack of specialized design for KG construction. Additionally, there is a gap in evaluation datasets and methodologies for ontology-free KG construction. To overcome these limitations, we propose SynthKG, a multi-step, document-level ontology-free KG synthesis workflow based on LLMs. By fine-tuning a smaller LLM on the synthesized document-KG pairs, we streamline the multi-step process into a single-step KG generation approach called Distill-SynthKG, substantially reducing the number of LLM inference calls. Furthermore, we re-purpose existing question-answering datasets to establish KG evaluation datasets and introduce new evaluation metrics. Using KGs produced by Distill-SynthKG, we also design a novel graph-based retrieval framework for RAG. Experimental results demonstrate that Distill-SynthKG not only surpasses all baseline models in KG quality -- including models up to eight times larger -- but also consistently excels in retrieval and question-answering tasks. Our proposed graph retrieval framework also outperforms all KG-retrieval methods across multiple benchmark datasets. We release the SynthKG dataset and Distill-SynthKG model publicly to support further research and development.
Probing and Mitigating Intersectional Social Biases in Vision-Language Models with Counterfactual Examples
Nov 30, 2023While vision-language models (VLMs) have achieved remarkable performance improvements recently, there is growing evidence that these models also posses harmful biases with respect to social attributes such as gender and race. Prior studies have primarily focused on probing such bias attributes individually while ignoring biases associated with intersections between social attributes. This could be due to the difficulty of collecting an exhaustive set of image-text pairs for various combinations of social attributes. To address this challenge, we employ text-to-image diffusion models to produce counterfactual examples for probing intserctional social biases at scale. Our approach utilizes Stable Diffusion with cross attention control to produce sets of counterfactual image-text pairs that are highly similar in their depiction of a subject (e.g., a given occupation) while differing only in their depiction of intersectional social attributes (e.g., race & gender). Through our over-generate-then-filter methodology, we produce SocialCounterfactuals, a high-quality dataset containing over 171k image-text pairs for probing intersectional biases related to gender, race, and physical characteristics. We conduct extensive experiments to demonstrate the usefulness of our generated dataset for probing and mitigating intersectional social biases in state-of-the-art VLMs.
Semi-Structured Chain-of-Thought: Integrating Multiple Sources of Knowledge for Improved Language Model Reasoning
Nov 14, 2023



An important open question pertaining to the use of large language models for knowledge-intensive tasks is how to effectively integrate knowledge from three sources: the model's parametric memory, external structured knowledge, and external unstructured knowledge. Most existing prompting methods either rely solely on one or two of these sources, or require repeatedly invoking large language models to generate similar or identical content. In this work, we overcome these limitations by introducing a novel semi-structured prompting approach that seamlessly integrates the model's parametric memory with unstructured knowledge from text documents and structured knowledge from knowledge graphs. Experimental results on open-domain multi-hop question answering datasets demonstrate that our prompting method significantly surpasses existing techniques, even exceeding those which require fine-tuning.
Probing Intersectional Biases in Vision-Language Models with Counterfactual Examples
Oct 04, 2023

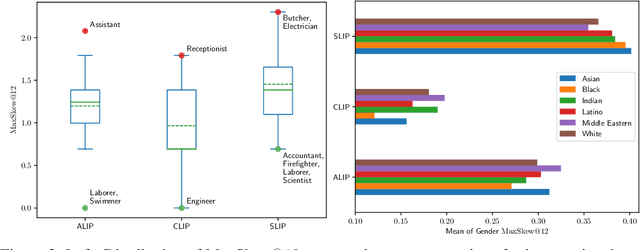

While vision-language models (VLMs) have achieved remarkable performance improvements recently, there is growing evidence that these models also posses harmful biases with respect to social attributes such as gender and race. Prior studies have primarily focused on probing such bias attributes individually while ignoring biases associated with intersections between social attributes. This could be due to the difficulty of collecting an exhaustive set of image-text pairs for various combinations of social attributes from existing datasets. To address this challenge, we employ text-to-image diffusion models to produce counterfactual examples for probing intserctional social biases at scale. Our approach utilizes Stable Diffusion with cross attention control to produce sets of counterfactual image-text pairs that are highly similar in their depiction of a subject (e.g., a given occupation) while differing only in their depiction of intersectional social attributes (e.g., race & gender). We conduct extensive experiments using our generated dataset which reveal the intersectional social biases present in state-of-the-art VLMs.
COCO-Counterfactuals: Automatically Constructed Counterfactual Examples for Image-Text Pairs
Sep 23, 2023Counterfactual examples have proven to be valuable in the field of natural language processing (NLP) for both evaluating and improving the robustness of language models to spurious correlations in datasets. Despite their demonstrated utility for NLP, multimodal counterfactual examples have been relatively unexplored due to the difficulty of creating paired image-text data with minimal counterfactual changes. To address this challenge, we introduce a scalable framework for automatic generation of counterfactual examples using text-to-image diffusion models. We use our framework to create COCO-Counterfactuals, a multimodal counterfactual dataset of paired image and text captions based on the MS-COCO dataset. We validate the quality of COCO-Counterfactuals through human evaluations and show that existing multimodal models are challenged by our counterfactual image-text pairs. Additionally, we demonstrate the usefulness of COCO-Counterfactuals for improving out-of-domain generalization of multimodal vision-language models via training data augmentation.
Solving Distributed Constraint Optimization Problems Using Logic Programming
May 10, 2017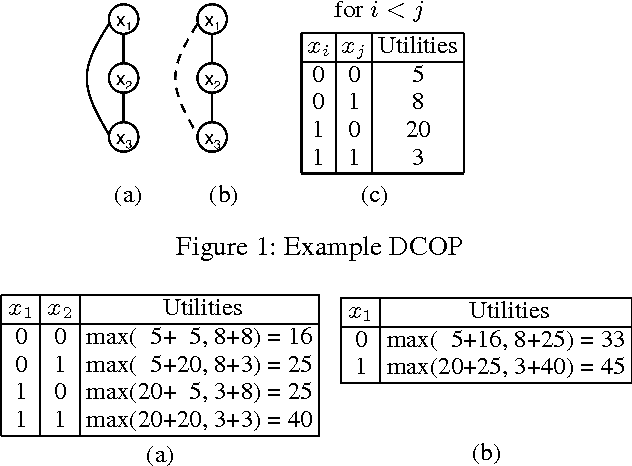
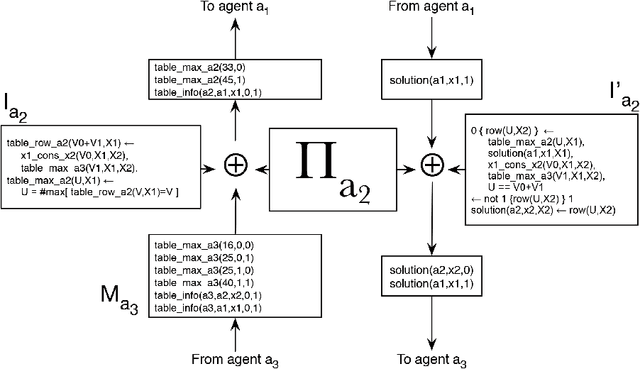
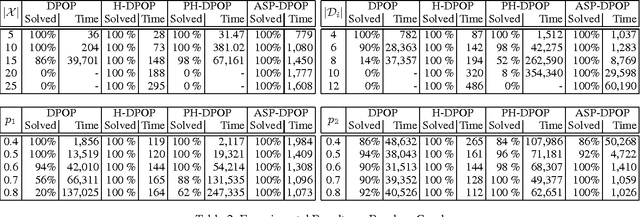
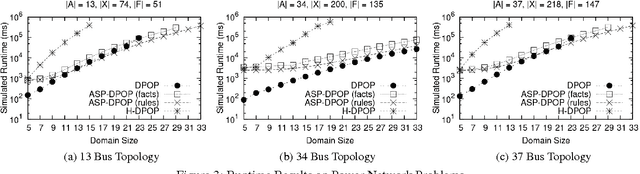
This paper explores the use of Answer Set Programming (ASP) in solving Distributed Constraint Optimization Problems (DCOPs). The paper provides the following novel contributions: (1) It shows how one can formulate DCOPs as logic programs; (2) It introduces ASP-DPOP, the first DCOP algorithm that is based on logic programming; (3) It experimentally shows that ASP-DPOP can be up to two orders of magnitude faster than DPOP (its imperative programming counterpart) as well as solve some problems that DPOP fails to solve, due to memory limitations; and (4) It demonstrates the applicability of ASP in a wide array of multi-agent problems currently modeled as DCOPs. Under consideration in Theory and Practice of Logic Programming (TPLP).
Logic and Constraint Logic Programming for Distributed Constraint Optimization
May 14, 2014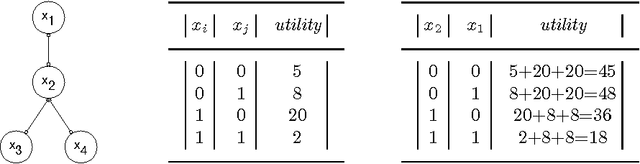
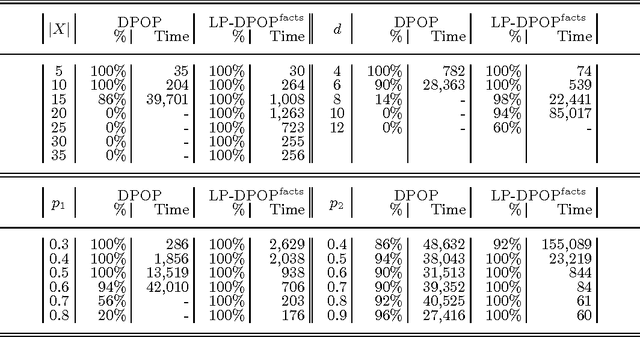
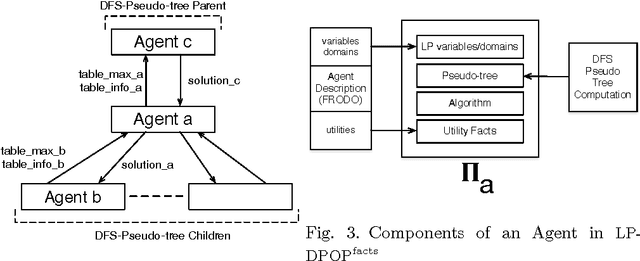
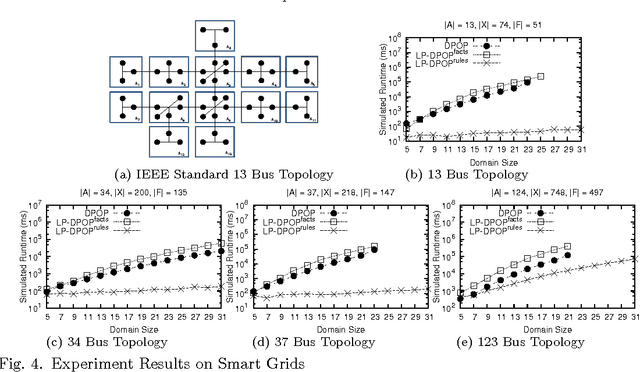
The field of Distributed Constraint Optimization Problems (DCOPs) has gained momentum, thanks to its suitability in capturing complex problems (e.g., multi-agent coordination and resource allocation problems) that are naturally distributed and cannot be realistically addressed in a centralized manner. The state of the art in solving DCOPs relies on the use of ad-hoc infrastructures and ad-hoc constraint solving procedures. This paper investigates an infrastructure for solving DCOPs that is completely built on logic programming technologies. In particular, the paper explores the use of a general constraint solver (a constraint logic programming system in this context) to handle the agent-level constraint solving. The preliminary experiments show that logic programming provides benefits over a state-of-the-art DCOP system, in terms of performance and scalability, opening the doors to the use of more advanced technology (e.g., search strategies and complex constraints) for solving DCOPs.