 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
Fine-Grained Perturbation Guidance via Attention Head Selection
Jun 12, 2025Recent guidance methods in diffusion models steer reverse sampling by perturbing the model to construct an implicit weak model and guide generation away from it. Among these approaches, attention perturbation has demonstrated strong empirical performance in unconditional scenarios where classifier-free guidance is not applicable. However, existing attention perturbation methods lack principled approaches for determining where perturbations should be applied, particularly in Diffusion Transformer (DiT) architectures where quality-relevant computations are distributed across layers. In this paper, we investigate the granularity of attention perturbations, ranging from the layer level down to individual attention heads, and discover that specific heads govern distinct visual concepts such as structure, style, and texture quality. Building on this insight, we propose "HeadHunter", a systematic framework for iteratively selecting attention heads that align with user-centric objectives, enabling fine-grained control over generation quality and visual attributes. In addition, we introduce SoftPAG, which linearly interpolates each selected head's attention map toward an identity matrix, providing a continuous knob to tune perturbation strength and suppress artifacts. Our approach not only mitigates the oversmoothing issues of existing layer-level perturbation but also enables targeted manipulation of specific visual styles through compositional head selection. We validate our method on modern large-scale DiT-based text-to-image models including Stable Diffusion 3 and FLUX.1, demonstrating superior performance in both general quality enhancement and style-specific guidance. Our work provides the first head-level analysis of attention perturbation in diffusion models, uncovering interpretable specialization within attention layers and enabling practical design of effective perturbation strategies.
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
May 15, 2025



This paper does not describe a new method; instead, it provides a thorough exploration of an important yet understudied design space related to recent advances in text-to-image synthesis -- specifically, the deep fusion of large language models (LLMs) and diffusion transformers (DiTs) for multi-modal generation. Previous studies mainly focused on overall system performance rather than detailed comparisons with alternative methods, and key design details and training recipes were often left undisclosed. These gaps create uncertainty about the real potential of this approach. To fill these gaps, we conduct an empirical study on text-to-image generation, performing controlled comparisons with established baselines, analyzing important design choices, and providing a clear, reproducible recipe for training at scale. We hope this work offers meaningful data points and practical guidelines for future research in multi-modal generation.
From Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
Apr 22, 2025Recent text-to-image diffusion models achieve impressive visual quality through extensive scaling of training data and model parameters, yet they often struggle with complex scenes and fine-grained details. Inspired by the self-reflection capabilities emergent in large language models, we propose ReflectionFlow, an inference-time framework enabling diffusion models to iteratively reflect upon and refine their outputs. ReflectionFlow introduces three complementary inference-time scaling axes: (1) noise-level scaling to optimize latent initialization; (2) prompt-level scaling for precise semantic guidance; and most notably, (3) reflection-level scaling, which explicitly provides actionable reflections to iteratively assess and correct previous generations. To facilitate reflection-level scaling, we construct GenRef, a large-scale dataset comprising 1 million triplets, each containing a reflection, a flawed image, and an enhanced image. Leveraging this dataset, we efficiently perform reflection tuning on state-of-the-art diffusion transformer, FLUX.1-dev, by jointly modeling multimodal inputs within a unified framework. Experimental results show that ReflectionFlow significantly outperforms naive noise-level scaling methods, offering a scalable and compute-efficient solution toward higher-quality image synthesis on challenging tasks.
FiVL: A Framework for Improved Vision-Language Alignment
Dec 19, 2024



Large Vision Language Models (LVLMs) have achieved significant progress in integrating visual and textual inputs for multimodal reasoning. However, a recurring challenge is ensuring these models utilize visual information as effectively as linguistic content when both modalities are necessary to formulate an accurate answer. We hypothesize that hallucinations arise due to the lack of effective visual grounding in current LVLMs. This issue extends to vision-language benchmarks, where it is difficult to make the image indispensable for accurate answer generation, particularly in vision question-answering tasks. In this work, we introduce FiVL, a novel method for constructing datasets designed to train LVLMs for enhanced visual grounding and to evaluate their effectiveness in achieving it. These datasets can be utilized for both training and assessing an LVLM's ability to use image content as substantive evidence rather than relying solely on linguistic priors, providing insights into the model's reliance on visual information. To demonstrate the utility of our dataset, we introduce an innovative training task that outperforms baselines alongside a validation method and application for explainability. The code is available at https://github.com/IntelLabs/fivl.
A Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
FastRM: An efficient and automatic explainability framework for multimodal generative models
Dec 02, 2024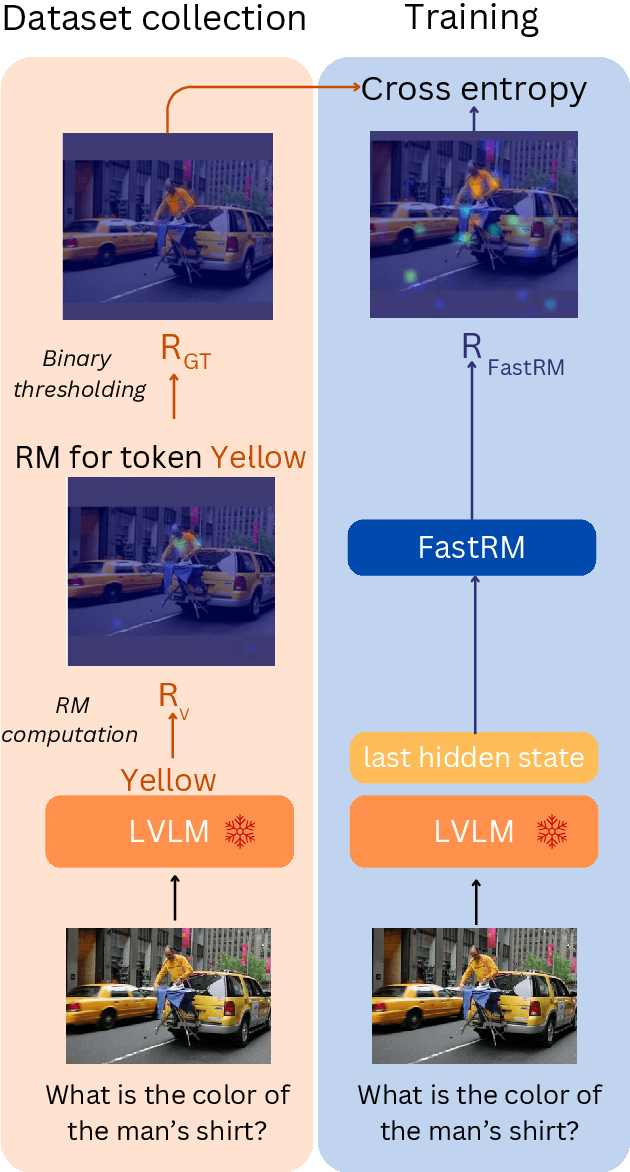
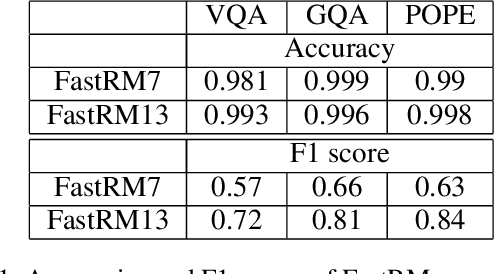
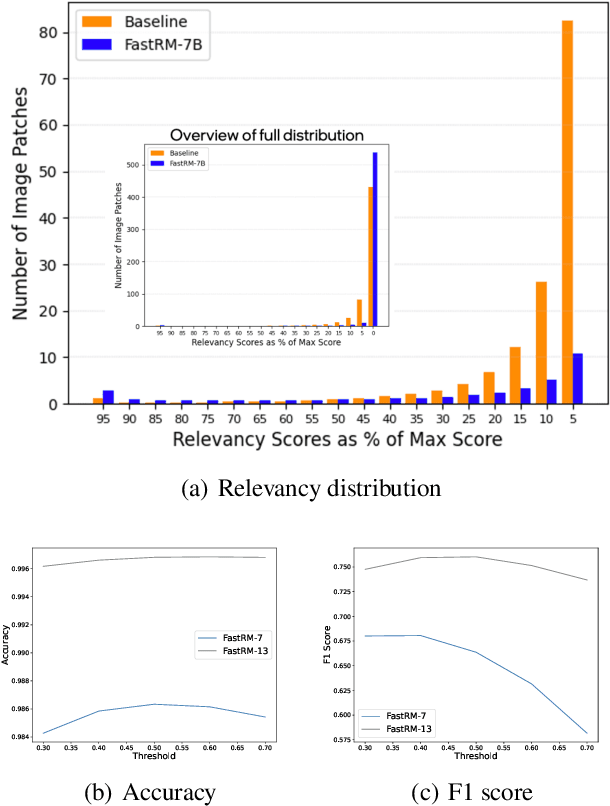
While Large Vision Language Models (LVLMs) have become masterly capable in reasoning over human prompts and visual inputs, they are still prone to producing responses that contain misinformation. Identifying incorrect responses that are not grounded in evidence has become a crucial task in building trustworthy AI. Explainability methods such as gradient-based relevancy maps on LVLM outputs can provide an insight on the decision process of models, however these methods are often computationally expensive and not suited for on-the-fly validation of outputs. In this work, we propose FastRM, an effective way for predicting the explainable Relevancy Maps of LVLM models. Experimental results show that employing FastRM leads to a 99.8% reduction in compute time for relevancy map generation and an 44.4% reduction in memory footprint for the evaluated LVLM, making explainable AI more efficient and practical, thereby facilitating its deployment in real-world applications.
LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs
Aug 24, 2024The widespread adoption of cloud-based proprietary large language models (LLMs) has introduced significant challenges, including operational dependencies, privacy concerns, and the necessity of continuous internet connectivity. In this work, we introduce an LLMOps pipeline, "LlamaDuo", for the seamless migration of knowledge and abilities from service-oriented LLMs to smaller, locally manageable models. This pipeline is crucial for ensuring service continuity in the presence of operational failures, strict privacy policies, or offline requirements. Our LlamaDuo involves fine-tuning a small language model against the service LLM using a synthetic dataset generated by the latter. If the performance of the fine-tuned model falls short of expectations, it is enhanced by further fine-tuning with additional similar data created by the service LLM. This iterative process guarantees that the smaller model can eventually match or even surpass the service LLM's capabilities in specific downstream tasks, offering a practical and scalable solution for managing AI deployments in constrained environments. Extensive experiments with leading edge LLMs are conducted to demonstrate the effectiveness, adaptability, and affordability of LlamaDuo across various downstream tasks. Our pipeline implementation is available at https://github.com/deep-diver/llamaduo.
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jun 10, 2024Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this "reference mismatch" is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
Getting it Right: Improving Spatial Consistency in Text-to-Image Models
Apr 01, 2024One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.