 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research
May 17, 2025Recent advances in large language models (LLMs) have fueled the vision of automated scientific discovery, often called AI Co-Scientists. To date, prior work casts these systems as generative co-authors responsible for crafting hypotheses, synthesizing code, or drafting manuscripts. In this work, we explore a complementary application: using LLMs as verifiers to automate the \textbf{academic verification of scientific manuscripts}. To that end, we introduce SPOT, a dataset of 83 published papers paired with 91 errors significant enough to prompt errata or retraction, cross-validated with actual authors and human annotators. Evaluating state-of-the-art LLMs on SPOT, we find that none surpasses 21.1\% recall or 6.1\% precision (o3 achieves the best scores, with all others near zero). Furthermore, confidence estimates are uniformly low, and across eight independent runs, models rarely rediscover the same errors, undermining their reliability. Finally, qualitative analysis with domain experts reveals that even the strongest models make mistakes resembling student-level misconceptions derived from misunderstandings. These findings highlight the substantial gap between current LLM capabilities and the requirements for dependable AI-assisted academic verification.
On the Robustness of Reward Models for Language Model Alignment
May 12, 2025The Bradley-Terry (BT) model is widely practiced in reward modeling for reinforcement learning with human feedback (RLHF). Despite its effectiveness, reward models (RMs) trained with BT model loss are prone to over-optimization, losing generalizability to unseen input distributions. In this paper, we study the cause of over-optimization in RM training and its downstream effects on the RLHF procedure, accentuating the importance of distributional robustness of RMs in unseen data. First, we show that the excessive dispersion of hidden state norms is the main source of over-optimization. Then, we propose batch-wise sum-to-zero regularization (BSR) to enforce zero-centered reward sum per batch, constraining the rewards with extreme magnitudes. We assess the impact of BSR in improving robustness in RMs through four scenarios of over-optimization, where BSR consistently manifests better robustness. Subsequently, we compare the plain BT model and BSR on RLHF training and empirically show that robust RMs better align the policy to the gold preference model. Finally, we apply BSR to high-quality data and models, which surpasses state-of-the-art RMs in the 8B scale by adding more than 5% in complex preference prediction tasks. By conducting RLOO training with 8B RMs, AlpacaEval 2.0 reduces generation length by 40% while adding a 7% increase in win rate, further highlighting that robustness in RMs induces robustness in RLHF training. We release the code, data, and models: https://github.com/LinkedIn-XFACT/RM-Robustness.
Online Difficulty Filtering for Reasoning Oriented Reinforcement Learning
Apr 04, 2025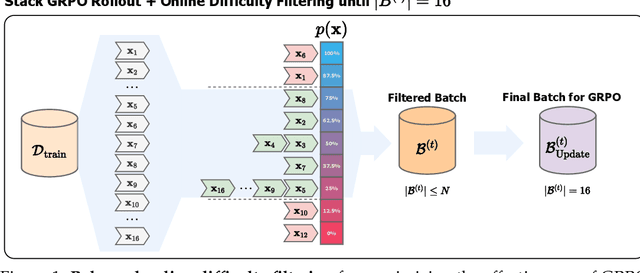
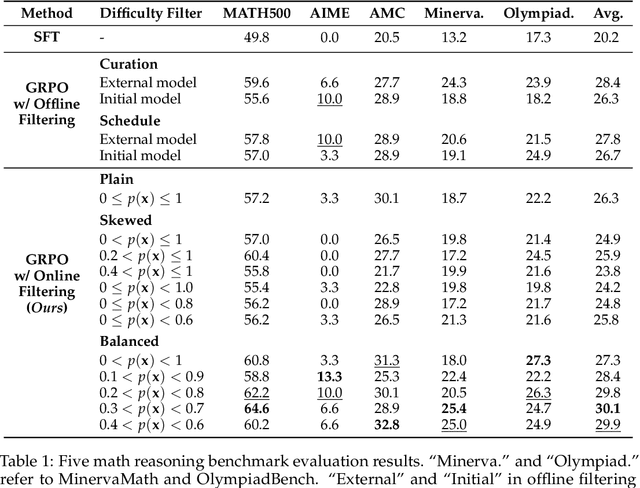
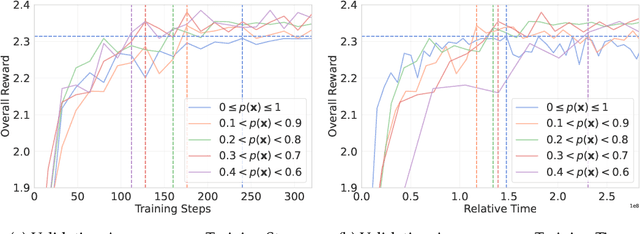
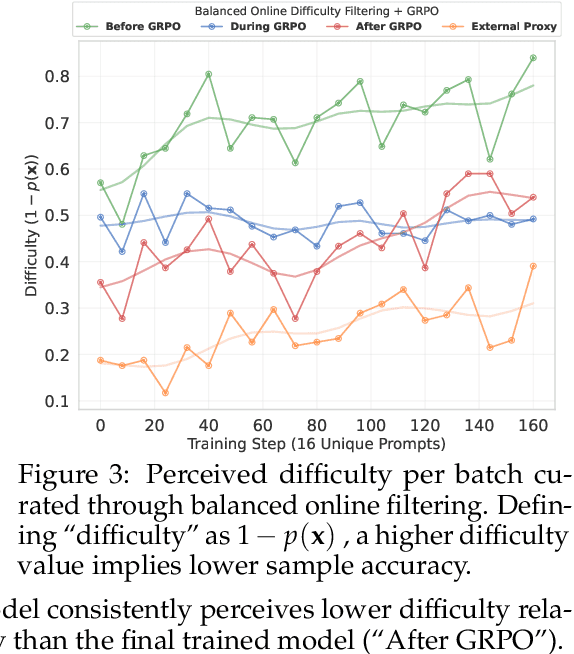
Reasoning-Oriented Reinforcement Learning (RORL) enhances the reasoning ability of Large Language Models (LLMs). However, due to the sparsity of rewards in RORL, effective training is highly dependent on the selection of problems of appropriate difficulty. Although curriculum learning attempts to address this by adjusting difficulty, it often relies on static schedules, and even recent online filtering methods lack theoretical grounding and a systematic understanding of their effectiveness. In this work, we theoretically and empirically show that curating the batch with the problems that the training model achieves intermediate accuracy on the fly can maximize the effectiveness of RORL training, namely balanced online difficulty filtering. We first derive that the lower bound of the KL divergence between the initial and the optimal policy can be expressed with the variance of the sampled accuracy. Building on those insights, we show that balanced filtering can maximize the lower bound, leading to better performance. Experimental results across five challenging math reasoning benchmarks show that balanced online filtering yields an additional 10% in AIME and 4% improvements in average over plain GRPO. Moreover, further analysis shows the gains in sample efficiency and training time efficiency, exceeding the maximum reward of plain GRPO within 60% training time and the volume of the training set.
Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning
Feb 24, 2025Scaling pre-training compute has proven effective for achieving mulitlinguality, but does the same hold for test-time scaling? In this work, we introduce MCLM, a multilingual math benchmark featuring competition-level problems in 55 languages. We test three test-time scaling methods-Outcome Reward Modeling (ORM), Process Reward Modeling (ORM), and Budget Forcing (BF)-on both Qwen2.5-1.5B Math and MR1-1.5B, a multilingual LLM we trained for extended reasoning. Our experiments show that using Qwen2.5-1.5B Math with ORM achieves a score of 35.8 on MCLM, while BF on MR1-1.5B attains 35.2. Although "thinking LLMs" have recently garnered significant attention, we find that their performance is comparable to traditional scaling methods like best-of-N once constrained to similar levels of inference FLOPs. Moreover, while BF yields a 20-point improvement on English AIME, it provides only a 1.94-point average gain across other languages-a pattern consistent across the other test-time scaling methods we studied-higlighting that test-time scaling may not generalize as effectively to multilingual tasks. To foster further research, we release MCLM, MR1-1.5B, and evaluation results.
AlphaPO -- Reward shape matters for LLM alignment
Jan 07, 2025Reinforcement Learning with Human Feedback (RLHF) and its variants have made huge strides toward the effective alignment of large language models (LLMs) to follow instructions and reflect human values. More recently, Direct Alignment Algorithms (DAAs) have emerged in which the reward modeling stage of RLHF is skipped by characterizing the reward directly as a function of the policy being learned. Examples include Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO). These methods often suffer from likelihood displacement, a phenomenon by which the probabilities of preferred responses are often reduced undesirably. In this paper, we argue that, for DAAs the reward (function) shape matters. We introduce AlphaPO, a new DAA method that leverages an $\alpha$-parameter to help change the shape of the reward function beyond the standard log reward. AlphaPO helps maintain fine-grained control over likelihood displacement and over-optimization. Compared to SimPO, one of the best performing DAAs, AlphaPO leads to about 7\% to 10\% relative improvement in alignment performance for the instruct versions of Mistral-7B and Llama3-8B. The analysis and results presented highlight the importance of the reward shape, and how one can systematically change it to affect training dynamics, as well as improve alignment performance.
Evaluating the Consistency of LLM Evaluators
Nov 30, 2024



Large language models (LLMs) have shown potential as general evaluators along with the evident benefits of speed and cost. While their correlation against human annotators has been widely studied, consistency as evaluators is still understudied, raising concerns about the reliability of LLM evaluators. In this paper, we conduct extensive studies on the two aspects of consistency in LLM evaluations, Self-Consistency (SC) and Inter-scale Consistency (IC), on different scoring scales and criterion granularity with open-source and proprietary models. Our comprehensive analysis demonstrates that strong proprietary models are not necessarily consistent evaluators, highlighting the importance of considering consistency in assessing the capability of LLM evaluators.
Cross-lingual Transfer of Reward Models in Multilingual Alignment
Oct 23, 2024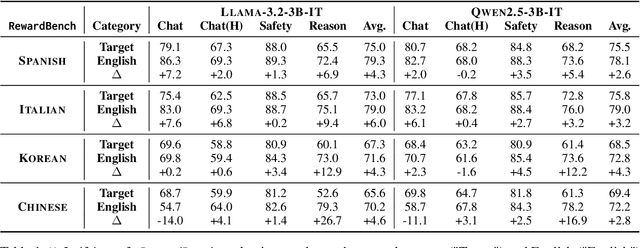
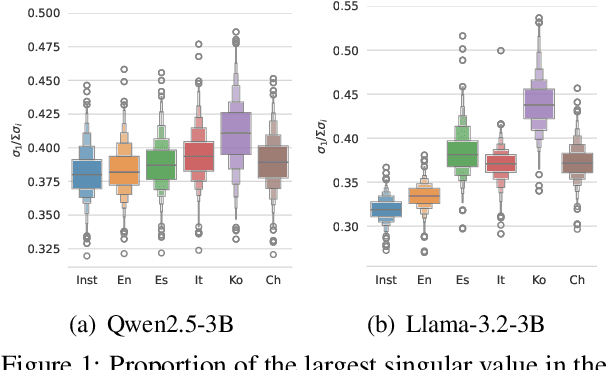
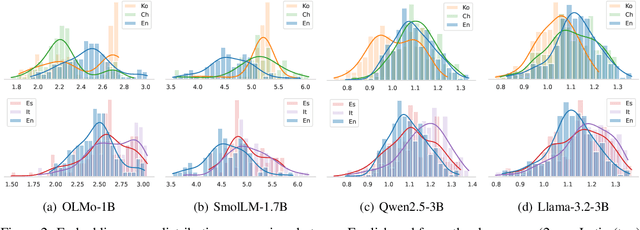

Reinforcement learning with human feedback (RLHF) is shown to largely benefit from precise reward models (RMs). However, recent studies in reward modeling schemes are skewed towards English, limiting the applicability of RLHF in multilingual alignments. In this work, we investigate the cross-lingual transfer of RMs trained in diverse languages, primarily from English. Our experimental results demonstrate the strong cross-lingual transfer of English RMs, exceeding target language RMs by 3~4% average increase in Multilingual RewardBench. Furthermore, we analyze the cross-lingual transfer of RMs through the representation shifts. Finally, we perform multilingual alignment to exemplify how cross-lingual transfer in RM propagates to enhanced multilingual instruction-following capability, along with extensive analyses on off-the-shelf RMs. We release the code, model, and data.
Stable Language Model Pre-training by Reducing Embedding Variability
Sep 12, 2024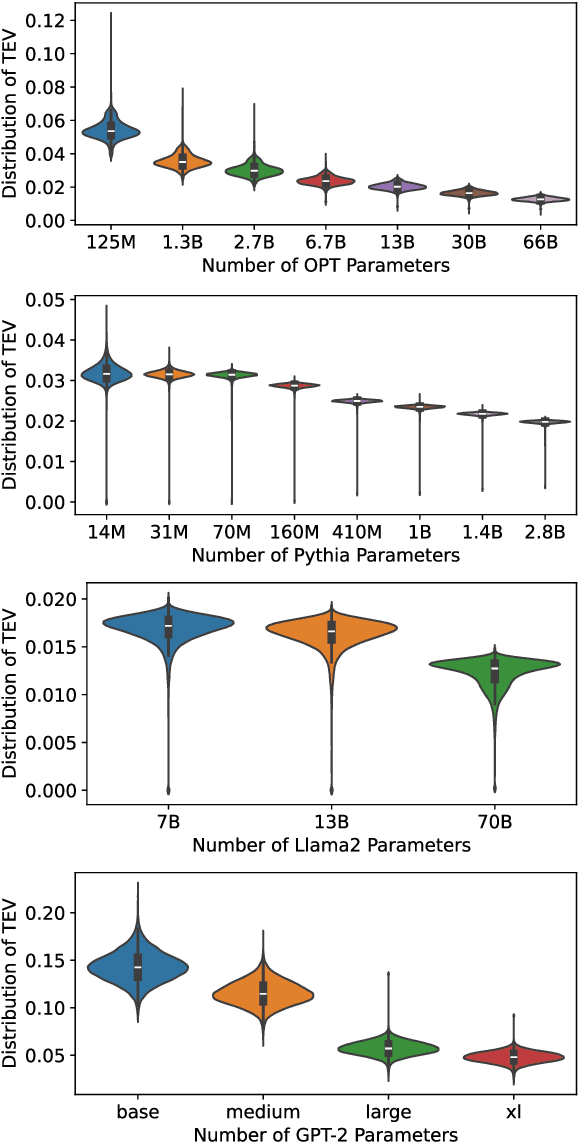
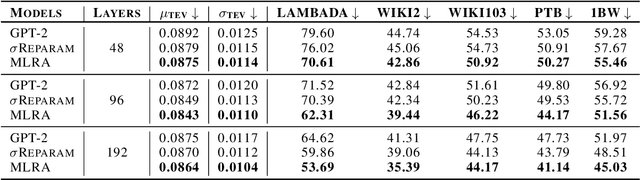
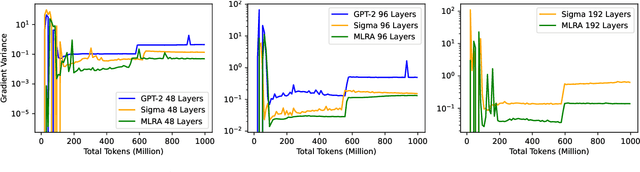
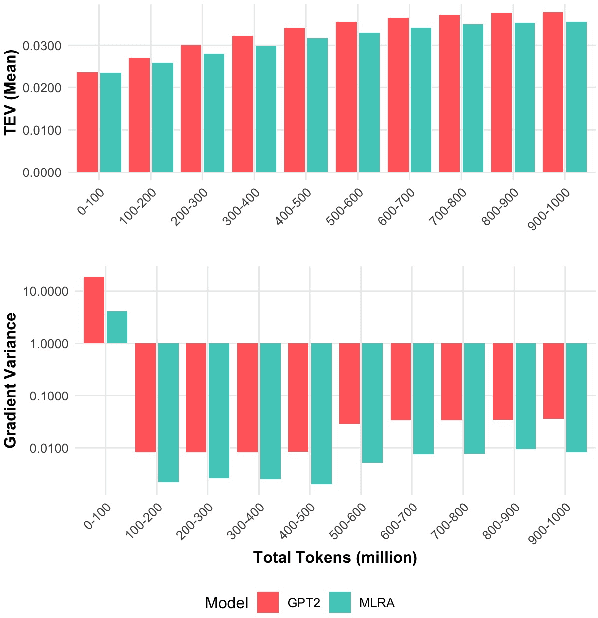
Stable pre-training is essential for achieving better-performing language models. However, tracking pre-training stability by calculating gradient variance at every step is impractical due to the significant computational costs. We explore Token Embedding Variability (TEV) as a simple and efficient proxy for assessing pre-training stability in language models with pre-layer normalization, given that shallower layers are more prone to gradient explosion (section 2.2). Moreover, we propose Multi-head Low-Rank Attention (MLRA) as an architecture to alleviate such instability by limiting the exponential growth of output embedding variance, thereby preventing the gradient explosion (section 3.2). Empirical results on GPT-2 with MLRA demonstrate increased stability and lower perplexity, particularly in deeper models.
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jun 10, 2024Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this "reference mismatch" is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
ORPO: Monolithic Preference Optimization without Reference Model
Mar 14, 2024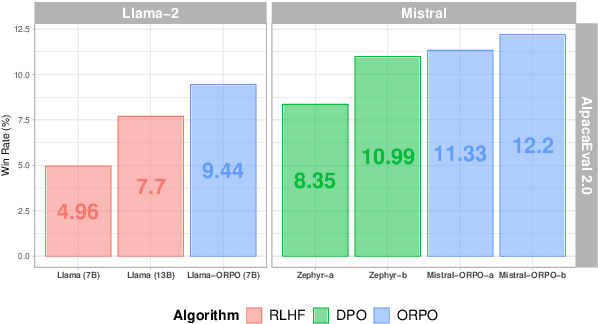
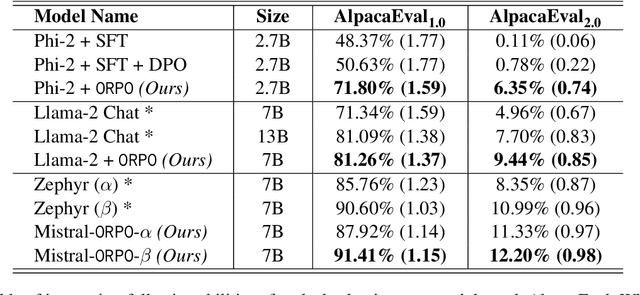
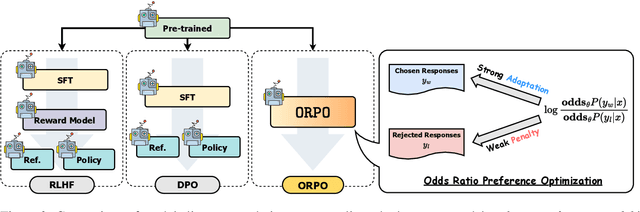
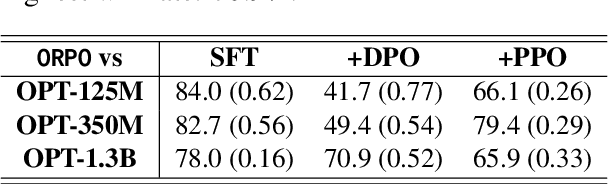
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context of preference alignment, emphasizing that a minor penalty for the disfavored generation style is sufficient for preference-aligned SFT. Building on this foundation, we introduce a straightforward and innovative reference model-free monolithic odds ratio preference optimization algorithm, ORPO, eliminating the necessity for an additional preference alignment phase. We demonstrate, both empirically and theoretically, that the odds ratio is a sensible choice for contrasting favored and disfavored styles during SFT across the diverse sizes from 125M to 7B. Specifically, fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO on the UltraFeedback alone surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to 12.20% on $\text{AlpacaEval}_{2.0}$ (Figure 1), 66.19% on IFEval (instruction-level loose, Table 6), and 7.32 in MT-Bench (Figure 12). We release code and model checkpoints for Mistral-ORPO-$\alpha$ (7B) and Mistral-ORPO-$\beta$ (7B).