 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Language Model Pre-training by Reducing Embedding Variability
Paper and Code
Sep 12, 2024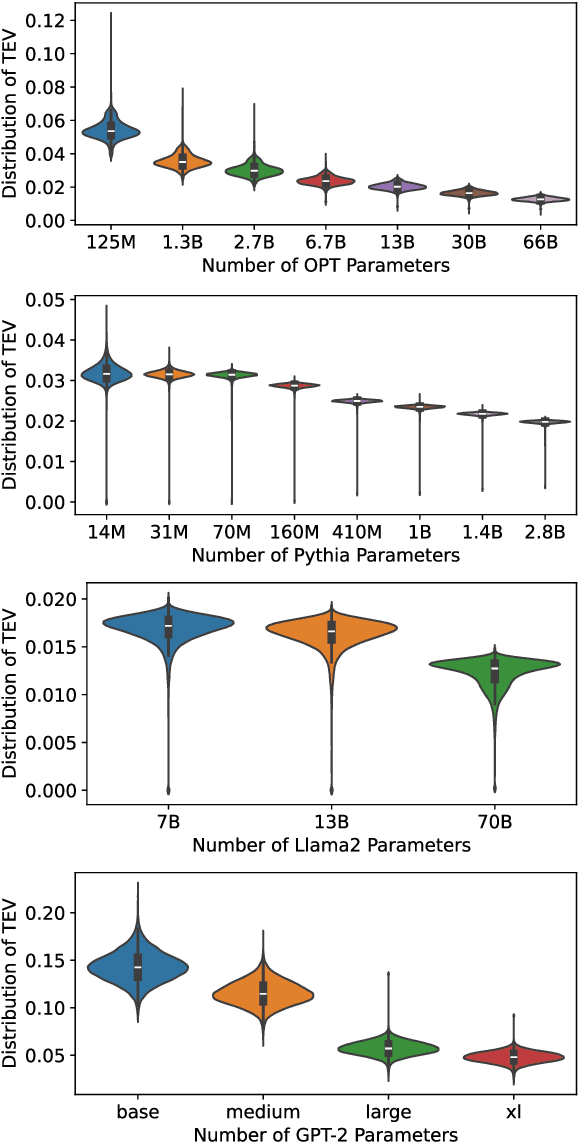
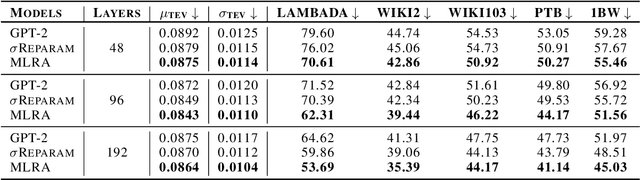
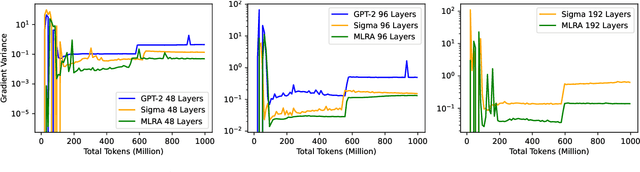
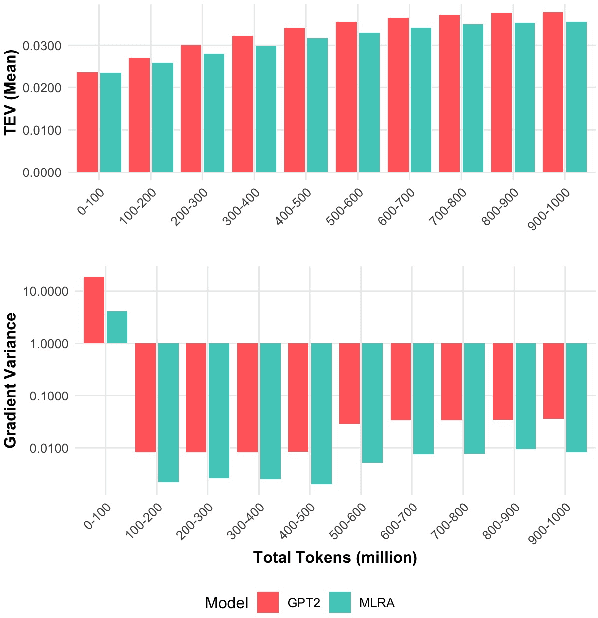
Stable pre-training is essential for achieving better-performing language models. However, tracking pre-training stability by calculating gradient variance at every step is impractical due to the significant computational costs. We explore Token Embedding Variability (TEV) as a simple and efficient proxy for assessing pre-training stability in language models with pre-layer normalization, given that shallower layers are more prone to gradient explosion (section 2.2). Moreover, we propose Multi-head Low-Rank Attention (MLRA) as an architecture to alleviate such instability by limiting the exponential growth of output embedding variance, thereby preventing the gradient explosion (section 3.2). Empirical results on GPT-2 with MLRA demonstrate increased stability and lower perplexity, particularly in deeper models.