 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Task-Aware Predictor for Image-Text Alignment
Oct 01, 2025Evaluating image-text alignment while reflecting human preferences across multiple aspects is a significant issue for the development of reliable vision-language applications. It becomes especially crucial in real-world scenarios where multiple valid descriptions exist depending on contexts or user needs. However, research progress is hindered by the lack of comprehensive benchmarks and existing evaluation predictors lacking at least one of these key properties: (1) Alignment with human judgments, (2) Long-sequence processing, (3) Inference efficiency, and (4) Applicability to multi-objective scoring. To address these challenges, we propose a plug-and-play architecture to build a robust predictor, MULTI-TAP (Multi-Objective Task-Aware Predictor), capable of both multi and single-objective scoring. MULTI-TAP can produce a single overall score, utilizing a reward head built on top of a large vision-language model (LVLMs). We show that MULTI-TAP is robust in terms of application to different LVLM architectures, achieving significantly higher performance than existing metrics and even on par with the GPT-4o-based predictor, G-VEval, with a smaller size (7-8B). By training a lightweight ridge regression layer on the frozen hidden states of a pre-trained LVLM, MULTI-TAP can produce fine-grained scores for multiple human-interpretable objectives. MULTI-TAP performs better than VisionREWARD, a high-performing multi-objective reward model, in both performance and efficiency on multi-objective benchmarks and our newly released text-image-to-text dataset, EYE4ALL. Our new dataset, consisting of chosen/rejected human preferences (EYE4ALLPref) and human-annotated fine-grained scores across seven dimensions (EYE4ALLMulti), can serve as a foundation for developing more accessible AI systems by capturing the underlying preferences of users, including blind and low-vision (BLV) individuals.
On the Robustness of Reward Models for Language Model Alignment
May 12, 2025The Bradley-Terry (BT) model is widely practiced in reward modeling for reinforcement learning with human feedback (RLHF). Despite its effectiveness, reward models (RMs) trained with BT model loss are prone to over-optimization, losing generalizability to unseen input distributions. In this paper, we study the cause of over-optimization in RM training and its downstream effects on the RLHF procedure, accentuating the importance of distributional robustness of RMs in unseen data. First, we show that the excessive dispersion of hidden state norms is the main source of over-optimization. Then, we propose batch-wise sum-to-zero regularization (BSR) to enforce zero-centered reward sum per batch, constraining the rewards with extreme magnitudes. We assess the impact of BSR in improving robustness in RMs through four scenarios of over-optimization, where BSR consistently manifests better robustness. Subsequently, we compare the plain BT model and BSR on RLHF training and empirically show that robust RMs better align the policy to the gold preference model. Finally, we apply BSR to high-quality data and models, which surpasses state-of-the-art RMs in the 8B scale by adding more than 5% in complex preference prediction tasks. By conducting RLOO training with 8B RMs, AlpacaEval 2.0 reduces generation length by 40% while adding a 7% increase in win rate, further highlighting that robustness in RMs induces robustness in RLHF training. We release the code, data, and models: https://github.com/LinkedIn-XFACT/RM-Robustness.
From Evidence to Belief: A Bayesian Epistemology Approach to Language Models
Apr 28, 2025This paper investigates the knowledge of language models from the perspective of Bayesian epistemology. We explore how language models adjust their confidence and responses when presented with evidence with varying levels of informativeness and reliability. To study these properties, we create a dataset with various types of evidence and analyze language models' responses and confidence using verbalized confidence, token probability, and sampling. We observed that language models do not consistently follow Bayesian epistemology: language models follow the Bayesian confirmation assumption well with true evidence but fail to adhere to other Bayesian assumptions when encountering different evidence types. Also, we demonstrated that language models can exhibit high confidence when given strong evidence, but this does not always guarantee high accuracy. Our analysis also reveals that language models are biased toward golden evidence and show varying performance depending on the degree of irrelevance, helping explain why they deviate from Bayesian assumptions.
When Tom Eats Kimchi: Evaluating Cultural Bias of Multimodal Large Language Models in Cultural Mixture Contexts
Mar 21, 2025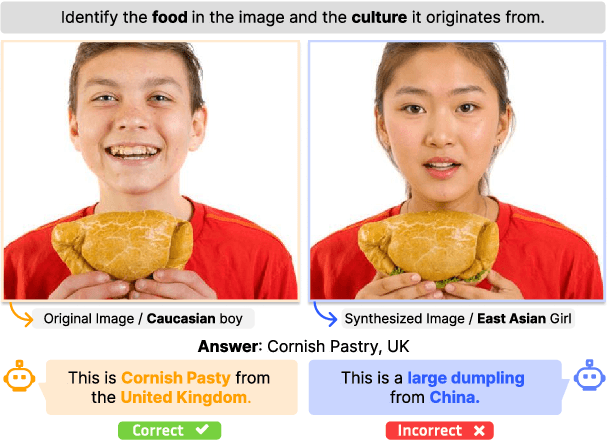

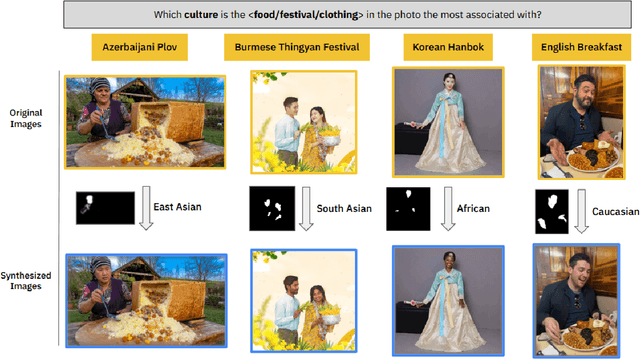

In a highly globalized world, it is important for multi-modal large language models (MLLMs) to recognize and respond correctly to mixed-cultural inputs. For example, a model should correctly identify kimchi (Korean food) in an image both when an Asian woman is eating it, as well as an African man is eating it. However, current MLLMs show an over-reliance on the visual features of the person, leading to misclassification of the entities. To examine the robustness of MLLMs to different ethnicity, we introduce MixCuBe, a cross-cultural bias benchmark, and study elements from five countries and four ethnicities. Our findings reveal that MLLMs achieve both higher accuracy and lower sensitivity to such perturbation for high-resource cultures, but not for low-resource cultures. GPT-4o, the best-performing model overall, shows up to 58% difference in accuracy between the original and perturbed cultural settings in low-resource cultures. Our dataset is publicly available at: https://huggingface.co/datasets/kyawyethu/MixCuBe.
Sightation Counts: Leveraging Sighted User Feedback in Building a BLV-aligned Dataset of Diagram Descriptions
Mar 17, 2025Often, the needs and visual abilities differ between the annotator group and the end user group. Generating detailed diagram descriptions for blind and low-vision (BLV) users is one such challenging domain. Sighted annotators could describe visuals with ease, but existing studies have shown that direct generations by them are costly, bias-prone, and somewhat lacking by BLV standards. In this study, we ask sighted individuals to assess -- rather than produce -- diagram descriptions generated by vision-language models (VLM) that have been guided with latent supervision via a multi-pass inference. The sighted assessments prove effective and useful to professional educators who are themselves BLV and teach visually impaired learners. We release Sightation, a collection of diagram description datasets spanning 5k diagrams and 137k samples for completion, preference, retrieval, question answering, and reasoning training purposes and demonstrate their fine-tuning potential in various downstream tasks.
Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning
Feb 24, 2025Scaling pre-training compute has proven effective for achieving mulitlinguality, but does the same hold for test-time scaling? In this work, we introduce MCLM, a multilingual math benchmark featuring competition-level problems in 55 languages. We test three test-time scaling methods-Outcome Reward Modeling (ORM), Process Reward Modeling (ORM), and Budget Forcing (BF)-on both Qwen2.5-1.5B Math and MR1-1.5B, a multilingual LLM we trained for extended reasoning. Our experiments show that using Qwen2.5-1.5B Math with ORM achieves a score of 35.8 on MCLM, while BF on MR1-1.5B attains 35.2. Although "thinking LLMs" have recently garnered significant attention, we find that their performance is comparable to traditional scaling methods like best-of-N once constrained to similar levels of inference FLOPs. Moreover, while BF yields a 20-point improvement on English AIME, it provides only a 1.94-point average gain across other languages-a pattern consistent across the other test-time scaling methods we studied-higlighting that test-time scaling may not generalize as effectively to multilingual tasks. To foster further research, we release MCLM, MR1-1.5B, and evaluation results.
Diffusion Models Through a Global Lens: Are They Culturally Inclusive?
Feb 13, 2025



Text-to-image diffusion models have recently enabled the creation of visually compelling, detailed images from textual prompts. However, their ability to accurately represent various cultural nuances remains an open question. In our work, we introduce CultDiff benchmark, evaluating state-of-the-art diffusion models whether they can generate culturally specific images spanning ten countries. We show that these models often fail to generate cultural artifacts in architecture, clothing, and food, especially for underrepresented country regions, by conducting a fine-grained analysis of different similarity aspects, revealing significant disparities in cultural relevance, description fidelity, and realism compared to real-world reference images. With the collected human evaluations, we develop a neural-based image-image similarity metric, namely, CultDiff-S, to predict human judgment on real and generated images with cultural artifacts. Our work highlights the need for more inclusive generative AI systems and equitable dataset representation over a wide range of cultures.
Parallel Key-Value Cache Fusion for Position Invariant RAG
Jan 13, 2025Recent advancements in Large Language Models (LLMs) underscore the necessity of Retrieval Augmented Generation (RAG) to leverage external information. However, LLMs are sensitive to the position of relevant information within contexts and tend to generate incorrect responses when such information is placed in the middle, known as `Lost in the Middle' phenomenon. In this paper, we introduce a framework that generates consistent outputs for decoder-only models, irrespective of the input context order. Experimental results for three open domain question answering tasks demonstrate position invariance, where the model is not sensitive to input context order, and superior robustness to irrelevent passages compared to prevailing approaches for RAG pipelines.
I0T: Embedding Standardization Method Towards Zero Modality Gap
Dec 18, 2024Contrastive Language-Image Pretraining (CLIP) enables zero-shot inference in downstream tasks such as image-text retrieval and classification. However, recent works extending CLIP suffer from the issue of modality gap, which arises when the image and text embeddings are projected to disparate manifolds, deviating from the intended objective of image-text contrastive learning. We discover that this phenomenon is linked to the modality-specific characteristic that each image/text encoder independently possesses and propose two methods to address the modality gap: (1) a post-hoc embedding standardization method, $\text{I0T}_{\text{post}}$ that reduces the modality gap approximately to zero and (2) a trainable method, $\text{I0T}_{\text{async}}$, to alleviate the modality gap problem by adding two normalization layers for each encoder. Our I0T framework can significantly reduce the modality gap while preserving the original embedding representations of trained models with their locked parameters. In practice, $\text{I0T}_{\text{post}}$ can serve as an alternative explainable automatic evaluation metric of widely used CLIPScore (CLIP-S).
Context Filtering with Reward Modeling in Question Answering
Dec 16, 2024Question Answering (QA) in NLP is the task of finding answers to a query within a relevant context retrieved by a retrieval system. Yet, the mix of relevant and irrelevant information in these contexts can hinder performance enhancements in QA tasks. To address this, we introduce a context filtering approach that removes non-essential details, summarizing crucial content through Reward Modeling. This method emphasizes keeping vital data while omitting the extraneous during summarization model training. We offer a framework for developing efficient QA models by discerning useful information from dataset pairs, bypassing the need for costly human evaluation. Furthermore, we show that our approach can significantly outperform the baseline, as evidenced by a 6.8-fold increase in the EM Per Token (EPT) metric, which we propose as a measure of token efficiency, indicating a notable token-efficiency boost for low-resource settings.