 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudging What We Cannot Solve: A Consequence-Based Approach for Oracle-Free Evaluation of Research-Level Math
Feb 06, 2026Recent progress in reasoning models suggests that generating plausible attempts for research-level mathematics may be within reach, but verification remains a bottleneck, consuming scarce expert time. We hypothesize that a meaningful solution should contain enough method-level information that, when applied to a neighborhood of related questions, it should yield better downstream performance than incorrect solutions. Building on this idea, we propose \textbf{Consequence-Based Utility}, an oracle-free evaluator that scores each candidate by testing its value as an in-context exemplar in solving related yet verifiable questions. Our approach is evaluated on an original set of research-level math problems, each paired with one expert-written solution and nine LLM-generated solutions. Notably, Consequence-Based Utility consistently outperforms reward models, generative reward models, and LLM judges on ranking quality. Specifically, for GPT-OSS-120B, it improves Acc@1 from 67.2 to 76.3 and AUC from 71.4 to 79.6, with similarly large AUC gains on GPT-OSS-20B (69.0 to 79.2). Furthermore, compared to LLM-Judges, it also exhibits a larger solver-evaluator gap, maintaining a stronger correct-wrong separation even on instances where the underlying solver often fails to solve.
KAIO: A Collection of More Challenging Korean Questions
Sep 18, 2025With the advancement of mid/post-training techniques, LLMs are pushing their boundaries at an accelerated pace. Legacy benchmarks saturate quickly (e.g., broad suites like MMLU over the years, newer ones like GPQA-D even faster), which makes frontier progress hard to track. The problem is especially acute in Korean: widely used benchmarks are fewer, often translated or narrow in scope, and updated more slowly, so saturation and contamination arrive sooner. Accordingly, at this moment, there is no Korean benchmark capable of evaluating and ranking frontier models. To bridge this gap, we introduce KAIO, a Korean, math-centric benchmark that stresses long-chain reasoning. Unlike recent Korean suites that are at or near saturation, KAIO remains far from saturated: the best-performing model, GPT-5, attains 62.8, followed by Gemini-2.5-Pro (52.3). Open models such as Qwen3-235B and DeepSeek-R1 cluster falls below 30, demonstrating substantial headroom, enabling robust tracking of frontier progress in Korean. To reduce contamination, KAIO will remain private and be served via a held-out evaluator until the best publicly known model reaches at least 80% accuracy, after which we will release the set and iterate to a harder version.
Controlling Language Confusion in Multilingual LLMs
May 25, 2025Large language models often suffer from language confusion, a phenomenon where responses are partially or entirely generated in unintended languages. This can critically impact user experience in low-resource settings. We hypothesize that conventional supervised fine-tuning exacerbates this issue because the softmax objective focuses probability mass only on the single correct token but does not explicitly penalize cross-lingual mixing. Interestingly, by observing loss trajectories during the pretraining phase, we observe that models fail to learn to distinguish between monolingual and language-confused text. Additionally, we find that ORPO, which adds penalties for unwanted output styles to standard SFT, effectively suppresses language-confused generations even at high decoding temperatures without degrading overall model performance. Our findings suggest that incorporating appropriate penalty terms can mitigate language confusion in low-resource settings with limited data.
When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research
May 17, 2025Recent advances in large language models (LLMs) have fueled the vision of automated scientific discovery, often called AI Co-Scientists. To date, prior work casts these systems as generative co-authors responsible for crafting hypotheses, synthesizing code, or drafting manuscripts. In this work, we explore a complementary application: using LLMs as verifiers to automate the \textbf{academic verification of scientific manuscripts}. To that end, we introduce SPOT, a dataset of 83 published papers paired with 91 errors significant enough to prompt errata or retraction, cross-validated with actual authors and human annotators. Evaluating state-of-the-art LLMs on SPOT, we find that none surpasses 21.1\% recall or 6.1\% precision (o3 achieves the best scores, with all others near zero). Furthermore, confidence estimates are uniformly low, and across eight independent runs, models rarely rediscover the same errors, undermining their reliability. Finally, qualitative analysis with domain experts reveals that even the strongest models make mistakes resembling student-level misconceptions derived from misunderstandings. These findings highlight the substantial gap between current LLM capabilities and the requirements for dependable AI-assisted academic verification.
On the Robustness of Reward Models for Language Model Alignment
May 12, 2025The Bradley-Terry (BT) model is widely practiced in reward modeling for reinforcement learning with human feedback (RLHF). Despite its effectiveness, reward models (RMs) trained with BT model loss are prone to over-optimization, losing generalizability to unseen input distributions. In this paper, we study the cause of over-optimization in RM training and its downstream effects on the RLHF procedure, accentuating the importance of distributional robustness of RMs in unseen data. First, we show that the excessive dispersion of hidden state norms is the main source of over-optimization. Then, we propose batch-wise sum-to-zero regularization (BSR) to enforce zero-centered reward sum per batch, constraining the rewards with extreme magnitudes. We assess the impact of BSR in improving robustness in RMs through four scenarios of over-optimization, where BSR consistently manifests better robustness. Subsequently, we compare the plain BT model and BSR on RLHF training and empirically show that robust RMs better align the policy to the gold preference model. Finally, we apply BSR to high-quality data and models, which surpasses state-of-the-art RMs in the 8B scale by adding more than 5% in complex preference prediction tasks. By conducting RLOO training with 8B RMs, AlpacaEval 2.0 reduces generation length by 40% while adding a 7% increase in win rate, further highlighting that robustness in RMs induces robustness in RLHF training. We release the code, data, and models: https://github.com/LinkedIn-XFACT/RM-Robustness.
HRET: A Self-Evolving LLM Evaluation Toolkit for Korean
Apr 01, 2025Recent advancements in Korean large language models (LLMs) have spurred numerous benchmarks and evaluation methodologies, yet the lack of a standardized evaluation framework has led to inconsistent results and limited comparability. To address this, we introduce HRET Haerae Evaluation Toolkit, an open-source, self-evolving evaluation framework tailored specifically for Korean LLMs. HRET unifies diverse evaluation methods, including logit-based scoring, exact-match, language-inconsistency penalization, and LLM-as-a-Judge assessments. Its modular, registry-based architecture integrates major benchmarks (HAE-RAE Bench, KMMLU, KUDGE, HRM8K) and multiple inference backends (vLLM, HuggingFace, OpenAI-compatible endpoints). With automated pipelines for continuous evolution, HRET provides a robust foundation for reproducible, fair, and transparent Korean NLP research.
Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning
Feb 24, 2025Scaling pre-training compute has proven effective for achieving mulitlinguality, but does the same hold for test-time scaling? In this work, we introduce MCLM, a multilingual math benchmark featuring competition-level problems in 55 languages. We test three test-time scaling methods-Outcome Reward Modeling (ORM), Process Reward Modeling (ORM), and Budget Forcing (BF)-on both Qwen2.5-1.5B Math and MR1-1.5B, a multilingual LLM we trained for extended reasoning. Our experiments show that using Qwen2.5-1.5B Math with ORM achieves a score of 35.8 on MCLM, while BF on MR1-1.5B attains 35.2. Although "thinking LLMs" have recently garnered significant attention, we find that their performance is comparable to traditional scaling methods like best-of-N once constrained to similar levels of inference FLOPs. Moreover, while BF yields a 20-point improvement on English AIME, it provides only a 1.94-point average gain across other languages-a pattern consistent across the other test-time scaling methods we studied-higlighting that test-time scaling may not generalize as effectively to multilingual tasks. To foster further research, we release MCLM, MR1-1.5B, and evaluation results.
Multi-Step Reasoning in Korean and the Emergent Mirage
Jan 10, 2025We introduce HRMCR (HAE-RAE Multi-Step Commonsense Reasoning), a benchmark designed to evaluate large language models' ability to perform multi-step reasoning in culturally specific contexts, focusing on Korean. The questions are automatically generated via templates and algorithms, requiring LLMs to integrate Korean cultural knowledge into sequential reasoning steps. Consistent with prior observations on emergent abilities, our experiments reveal that models trained on fewer than \(2 \cdot 10^{25}\) training FLOPs struggle to solve any questions, showing near-zero performance. Beyond this threshold, performance improves sharply. State-of-the-art models (e.g., O1) still score under 50\%, underscoring the difficulty of our tasks. Notably, stepwise analysis suggests the observed emergent behavior may stem from compounding errors across multiple steps rather than reflecting a genuinely new capability. We publicly release the benchmark and commit to regularly updating the dataset to prevent contamination.
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap
Jan 05, 2025



Large language models (LLMs) demonstrate exceptional performance on complex reasoning tasks. However, despite their strong reasoning capabilities in high-resource languages (e.g., English and Chinese), a significant performance gap persists in other languages. To investigate this gap in Korean, we introduce HRM8K, a benchmark comprising 8,011 English-Korean parallel bilingual math problems. Through systematic analysis of model behaviors, we identify a key finding: these performance disparities stem primarily from difficulties in comprehending non-English inputs, rather than limitations in reasoning capabilities. Based on these findings, we propose UST (Understand, Solve, and Translate), a method that strategically uses English as an anchor for reasoning and solution generation. By fine-tuning the model on 130k synthetically generated data points, UST achieves a 10.91% improvement on the HRM8K benchmark and reduces the multilingual performance gap from 11.6% to 0.7%. Additionally, we show that improvements from UST generalize effectively to different Korean domains, demonstrating that capabilities acquired from machine-verifiable content can be generalized to other areas. We publicly release the benchmark, training dataset, and models.
Improving Fine-grained Visual Understanding in VLMs through Text-Only Training
Dec 17, 2024


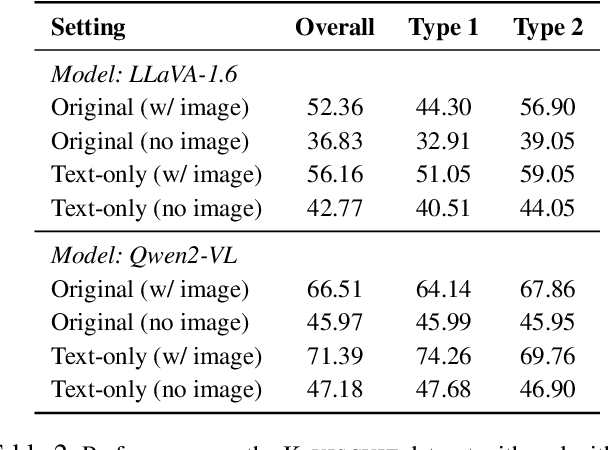
Visual-Language Models (VLMs) have become a powerful tool for bridging the gap between visual and linguistic understanding. However, the conventional learning approaches for VLMs often suffer from limitations, such as the high resource requirements of collecting and training image-text paired data. Recent research has suggested that language understanding plays a crucial role in the performance of VLMs, potentially indicating that text-only training could be a viable approach. In this work, we investigate the feasibility of enhancing fine-grained visual understanding in VLMs through text-only training. Inspired by how humans develop visual concept understanding, where rich textual descriptions can guide visual recognition, we hypothesize that VLMs can also benefit from leveraging text-based representations to improve their visual recognition abilities. We conduct comprehensive experiments on two distinct domains: fine-grained species classification and cultural visual understanding tasks. Our findings demonstrate that text-only training can be comparable to conventional image-text training while significantly reducing computational costs. This suggests a more efficient and cost-effective pathway for advancing VLM capabilities, particularly valuable in resource-constrained environments.