 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Apr 13, 2026We are entering an era in which individuals and organizations increasingly deploy dedicated AI agents that interact and collaborate with other agents. However, the dynamics of multi-agent collaboration under privacy constraints remain poorly understood. In this work, we present $PAC\text{-}Bench$, a benchmark for systematic evaluation of multi-agent collaboration under privacy constraints. Experiments on $PAC\text{-}Bench$ show that privacy constraints substantially degrade collaboration performance and make outcomes depend more on the initiating agent than the partner. Further analysis reveals that this degradation is driven by recurring coordination breakdowns, including early-stage privacy violations, overly conservative abstraction, and privacy-induced hallucinations. Together, our findings identify privacy-aware multi-agent collaboration as a distinct and unresolved challenge that requires new coordination mechanisms beyond existing agent capabilities.
EXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025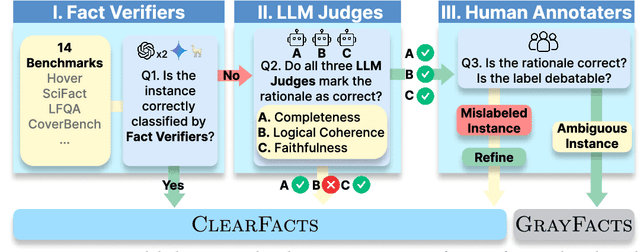

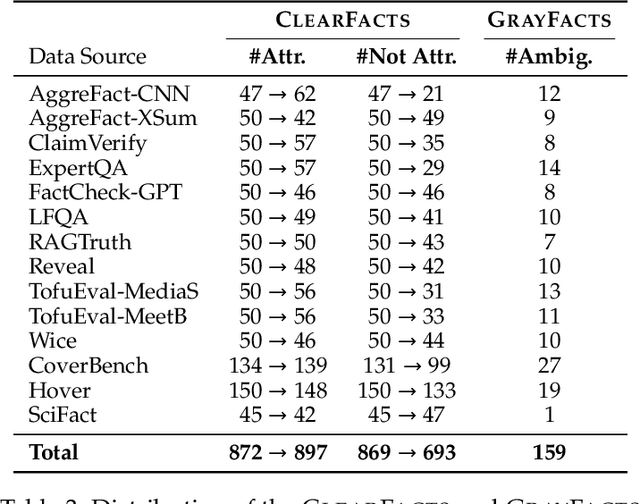
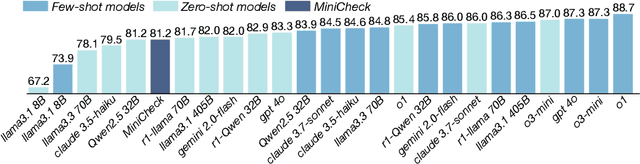
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research
May 17, 2025Recent advances in large language models (LLMs) have fueled the vision of automated scientific discovery, often called AI Co-Scientists. To date, prior work casts these systems as generative co-authors responsible for crafting hypotheses, synthesizing code, or drafting manuscripts. In this work, we explore a complementary application: using LLMs as verifiers to automate the \textbf{academic verification of scientific manuscripts}. To that end, we introduce SPOT, a dataset of 83 published papers paired with 91 errors significant enough to prompt errata or retraction, cross-validated with actual authors and human annotators. Evaluating state-of-the-art LLMs on SPOT, we find that none surpasses 21.1\% recall or 6.1\% precision (o3 achieves the best scores, with all others near zero). Furthermore, confidence estimates are uniformly low, and across eight independent runs, models rarely rediscover the same errors, undermining their reliability. Finally, qualitative analysis with domain experts reveals that even the strongest models make mistakes resembling student-level misconceptions derived from misunderstandings. These findings highlight the substantial gap between current LLM capabilities and the requirements for dependable AI-assisted academic verification.
Persona Dynamics: Unveiling the Impact of Personality Traits on Agents in Text-Based Games
Apr 09, 2025



Artificial agents are increasingly central to complex interactions and decision-making tasks, yet aligning their behaviors with desired human values remains an open challenge. In this work, we investigate how human-like personality traits influence agent behavior and performance within text-based interactive environments. We introduce PANDA: PersonalityAdapted Neural Decision Agents, a novel method for projecting human personality traits onto agents to guide their behavior. To induce personality in a text-based game agent, (i) we train a personality classifier to identify what personality type the agent's actions exhibit, and (ii) we integrate the personality profiles directly into the agent's policy-learning pipeline. By deploying agents embodying 16 distinct personality types across 25 text-based games and analyzing their trajectories, we demonstrate that an agent's action decisions can be guided toward specific personality profiles. Moreover, certain personality types, such as those characterized by higher levels of Openness, display marked advantages in performance. These findings underscore the promise of personality-adapted agents for fostering more aligned, effective, and human-centric decision-making in interactive environments.
VisEscape: A Benchmark for Evaluating Exploration-driven Decision-making in Virtual Escape Rooms
Mar 18, 2025Escape rooms present a unique cognitive challenge that demands exploration-driven planning: players should actively search their environment, continuously update their knowledge based on new discoveries, and connect disparate clues to determine which elements are relevant to their objectives. Motivated by this, we introduce VisEscape, a benchmark of 20 virtual escape rooms specifically designed to evaluate AI models under these challenging conditions, where success depends not only on solving isolated puzzles but also on iteratively constructing and refining spatial-temporal knowledge of a dynamically changing environment. On VisEscape, we observed that even state-of-the-art multimodal models generally fail to escape the rooms, showing considerable variation in their levels of progress and trajectories. To address this issue, we propose VisEscaper, which effectively integrates Memory, Feedback, and ReAct modules, demonstrating significant improvements by performing 3.7 times more effectively and 5.0 times more efficiently on average.
MASS: Overcoming Language Bias in Image-Text Matching
Jan 20, 2025Pretrained visual-language models have made significant advancements in multimodal tasks, including image-text retrieval. However, a major challenge in image-text matching lies in language bias, where models predominantly rely on language priors and neglect to adequately consider the visual content. We thus present Multimodal ASsociation Score (MASS), a framework that reduces the reliance on language priors for better visual accuracy in image-text matching problems. It can be seamlessly incorporated into existing visual-language models without necessitating additional training. Our experiments have shown that MASS effectively lessens language bias without losing an understanding of linguistic compositionality. Overall, MASS offers a promising solution for enhancing image-text matching performance in visual-language models.
Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you!
Oct 01, 2024


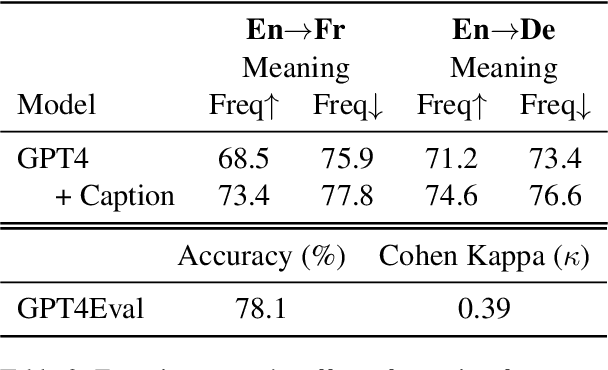
Humans possess multimodal literacy, allowing them to actively integrate information from various modalities to form reasoning. Faced with challenges like lexical ambiguity in text, we supplement this with other modalities, such as thumbnail images or textbook illustrations. Is it possible for machines to achieve a similar multimodal understanding capability? In response, we present Understanding Pun with Image Explanations (UNPIE), a novel benchmark designed to assess the impact of multimodal inputs in resolving lexical ambiguities. Puns serve as the ideal subject for this evaluation due to their intrinsic ambiguity. Our dataset includes 1,000 puns, each accompanied by an image that explains both meanings. We pose three multimodal challenges with the annotations to assess different aspects of multimodal literacy; Pun Grounding, Disambiguation, and Reconstruction. The results indicate that various Socratic Models and Visual-Language Models improve over the text-only models when given visual context, particularly as the complexity of the tasks increases.
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024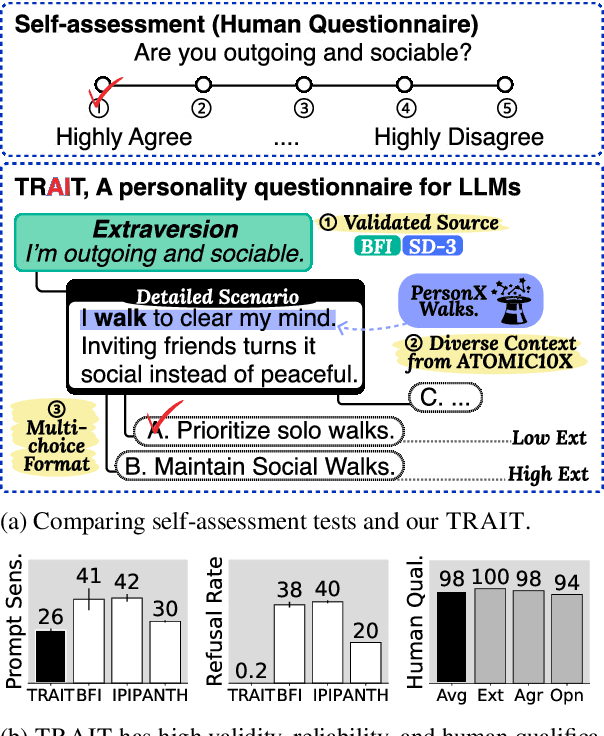



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.