 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Scalable Web Agent Learning via Recreated Websites
Mar 11, 2026Training autonomous web agents is fundamentally limited by the environments they learn from: real-world websites are unsafe to explore, hard to reset, and rarely provide verifiable feedback. We propose VeriEnv, a framework that treats language models as environment creators, automatically cloning real-world websites into fully executable, verifiable synthetic environments. By exposing controlled internal access via a Python SDK, VeriEnv enables agents to self-generate tasks with deterministic, programmatically verifiable rewards, eliminating reliance on heuristic or LLM-based judges. This design decouples agent learning from unsafe real-world interaction while enabling scalable self-evolution through environment expansion. Through experiments on web agent benchmarks, we show that agents trained with VeriEnv generalize to unseen websites, achieve site-specific mastery through self-evolving training, and benefit from scaling the number of training environments. Code and resources will be released at https://github.com/kyle8581/VeriEnv upon acceptance.
ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025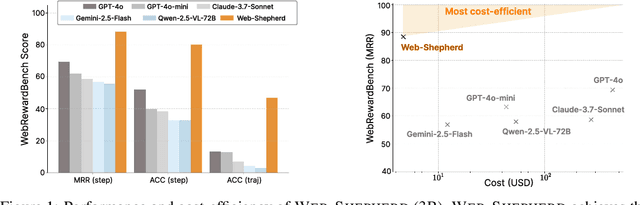


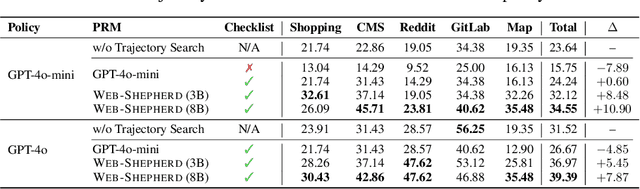
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Rethinking Reward Model Evaluation Through the Lens of Reward Overoptimization
May 19, 2025Reward models (RMs) play a crucial role in reinforcement learning from human feedback (RLHF), aligning model behavior with human preferences. However, existing benchmarks for reward models show a weak correlation with the performance of optimized policies, suggesting that they fail to accurately assess the true capabilities of RMs. To bridge this gap, we explore several evaluation designs through the lens of reward overoptimization\textemdash a phenomenon that captures both how well the reward model aligns with human preferences and the dynamics of the learning signal it provides to the policy. The results highlight three key findings on how to construct a reliable benchmark: (i) it is important to minimize differences between chosen and rejected responses beyond correctness, (ii) evaluating reward models requires multiple comparisons across a wide range of chosen and rejected responses, and (iii) given that reward models encounter responses with diverse representations, responses should be sourced from a variety of models. However, we also observe that a extremely high correlation with degree of overoptimization leads to comparatively lower correlation with certain downstream performance. Thus, when designing a benchmark, it is desirable to use the degree of overoptimization as a useful tool, rather than the end goal.
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
Oct 17, 2024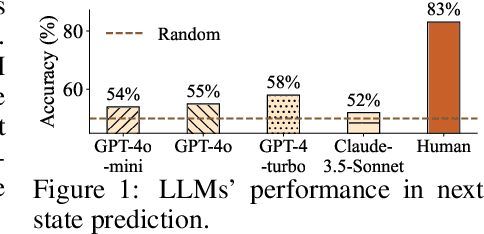
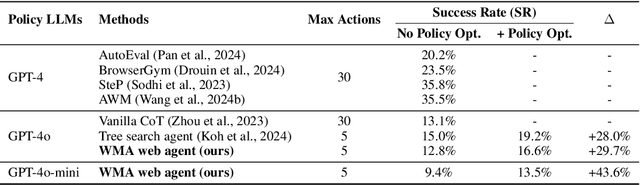
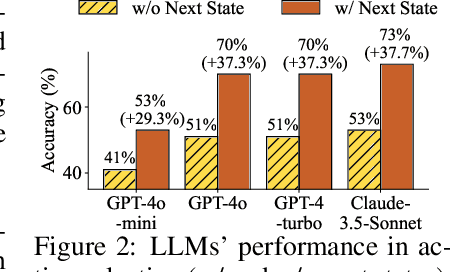

Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket. By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the "world model". Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4o, Claude-3.5-Sonnet, etc.). Then, we present a World-model-augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps. Experiments on WebArena and Mind2Web show that our world models improve agents' policy selection without training and demonstrate our agents' cost- and time-efficiency compared to recent tree-search-based agents.
Evaluating Robustness of Reward Models for Mathematical Reasoning
Oct 02, 2024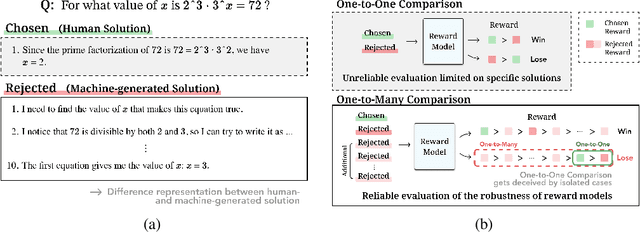
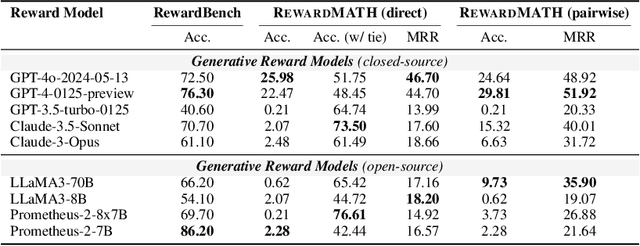
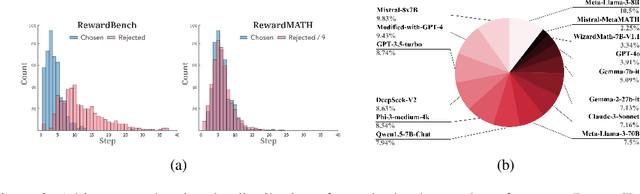
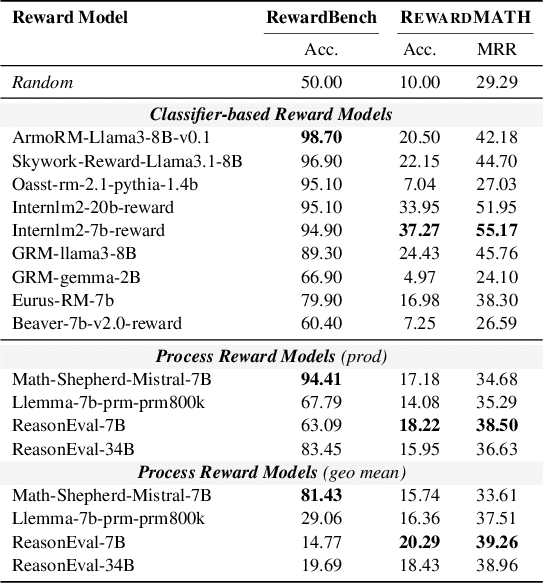
Reward models are key in reinforcement learning from human feedback (RLHF) systems, aligning the model behavior with human preferences. Particularly in the math domain, there have been plenty of studies using reward models to align policies for improving reasoning capabilities. Recently, as the importance of reward models has been emphasized, RewardBench is proposed to understand their behavior. However, we figure out that the math subset of RewardBench has different representations between chosen and rejected completions, and relies on a single comparison, which may lead to unreliable results as it only see an isolated case. Therefore, it fails to accurately present the robustness of reward models, leading to a misunderstanding of its performance and potentially resulting in reward hacking. In this work, we introduce a new design for reliable evaluation of reward models, and to validate this, we construct RewardMATH, a benchmark that effectively represents the robustness of reward models in mathematical reasoning tasks. We demonstrate that the scores on RewardMATH strongly correlate with the results of optimized policy and effectively estimate reward overoptimization, whereas the existing benchmark shows almost no correlation. The results underscore the potential of our design to enhance the reliability of evaluation, and represent the robustness of reward model. We make our code and data publicly available.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024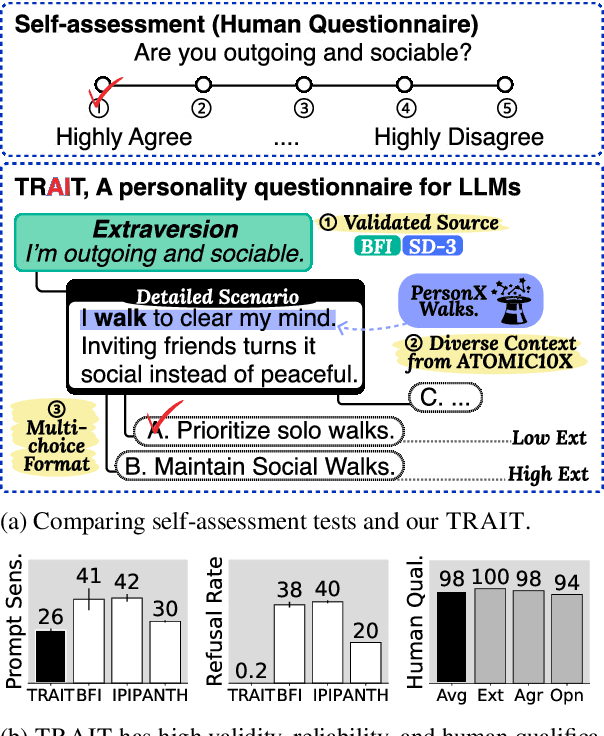



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Apr 03, 2024



Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.