 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025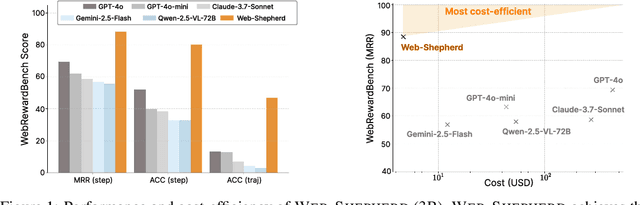


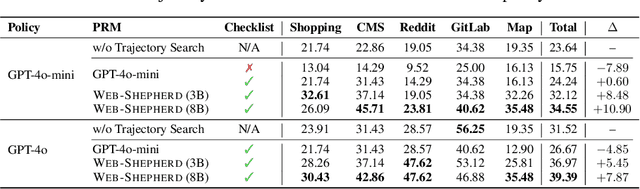
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Rethinking Reward Model Evaluation Through the Lens of Reward Overoptimization
May 19, 2025Reward models (RMs) play a crucial role in reinforcement learning from human feedback (RLHF), aligning model behavior with human preferences. However, existing benchmarks for reward models show a weak correlation with the performance of optimized policies, suggesting that they fail to accurately assess the true capabilities of RMs. To bridge this gap, we explore several evaluation designs through the lens of reward overoptimization\textemdash a phenomenon that captures both how well the reward model aligns with human preferences and the dynamics of the learning signal it provides to the policy. The results highlight three key findings on how to construct a reliable benchmark: (i) it is important to minimize differences between chosen and rejected responses beyond correctness, (ii) evaluating reward models requires multiple comparisons across a wide range of chosen and rejected responses, and (iii) given that reward models encounter responses with diverse representations, responses should be sourced from a variety of models. However, we also observe that a extremely high correlation with degree of overoptimization leads to comparatively lower correlation with certain downstream performance. Thus, when designing a benchmark, it is desirable to use the degree of overoptimization as a useful tool, rather than the end goal.
Evaluating Robustness of Reward Models for Mathematical Reasoning
Oct 02, 2024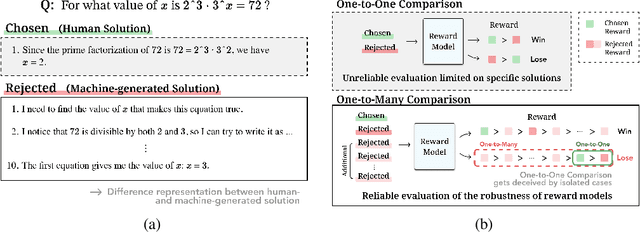
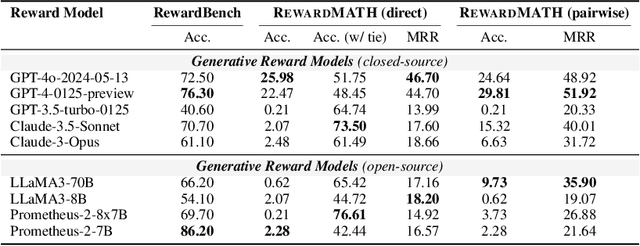
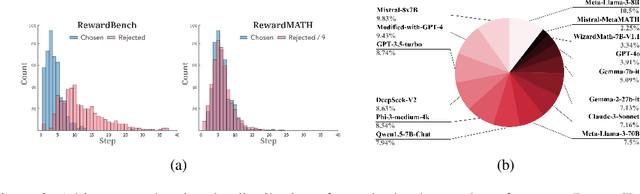
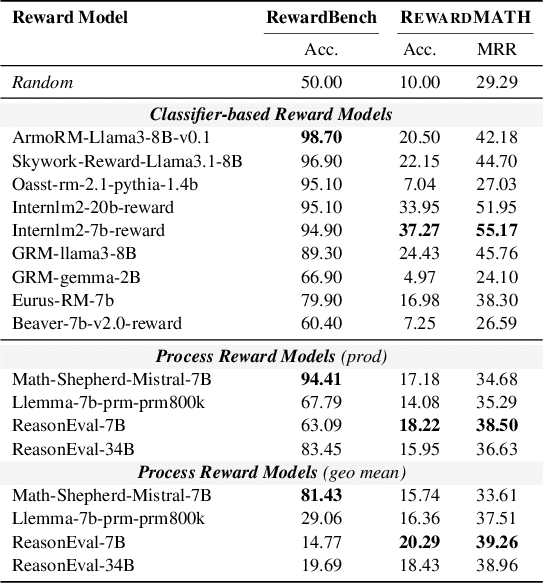
Reward models are key in reinforcement learning from human feedback (RLHF) systems, aligning the model behavior with human preferences. Particularly in the math domain, there have been plenty of studies using reward models to align policies for improving reasoning capabilities. Recently, as the importance of reward models has been emphasized, RewardBench is proposed to understand their behavior. However, we figure out that the math subset of RewardBench has different representations between chosen and rejected completions, and relies on a single comparison, which may lead to unreliable results as it only see an isolated case. Therefore, it fails to accurately present the robustness of reward models, leading to a misunderstanding of its performance and potentially resulting in reward hacking. In this work, we introduce a new design for reliable evaluation of reward models, and to validate this, we construct RewardMATH, a benchmark that effectively represents the robustness of reward models in mathematical reasoning tasks. We demonstrate that the scores on RewardMATH strongly correlate with the results of optimized policy and effectively estimate reward overoptimization, whereas the existing benchmark shows almost no correlation. The results underscore the potential of our design to enhance the reliability of evaluation, and represent the robustness of reward model. We make our code and data publicly available.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
Jul 03, 2024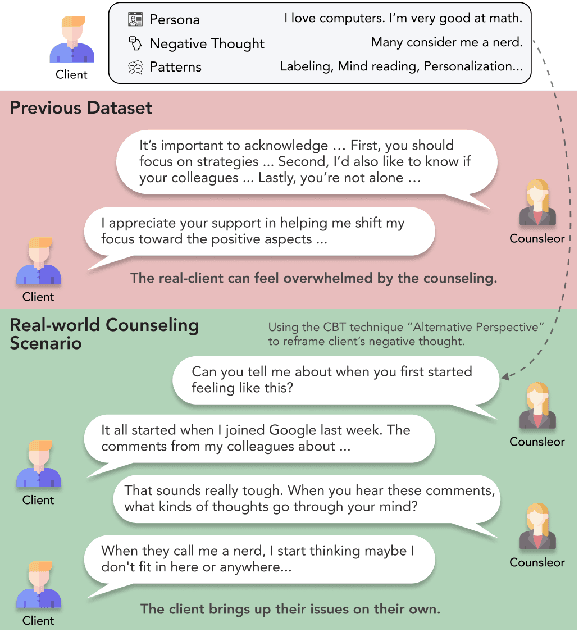



Recently, the demand for psychological counseling has significantly increased as more individuals express concerns about their mental health. This surge has accelerated efforts to improve the accessibility of counseling by using large language models (LLMs) as counselors. To ensure client privacy, training open-source LLMs faces a key challenge: the absence of realistic counseling datasets. To address this, we introduce Cactus, a multi-turn dialogue dataset that emulates real-life interactions using the goal-oriented and structured approach of Cognitive Behavioral Therapy (CBT). We create a diverse and realistic dataset by designing clients with varied, specific personas, and having counselors systematically apply CBT techniques in their interactions. To assess the quality of our data, we benchmark against established psychological criteria used to evaluate real counseling sessions, ensuring alignment with expert evaluations. Experimental results demonstrate that Camel, a model trained with Cactus, outperforms other models in counseling skills, highlighting its effectiveness and potential as a counseling agent. We make our data, model, and code publicly available.
Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation
Feb 20, 2024Emotional Support Conversation (ESC) is a task aimed at alleviating individuals' emotional distress through daily conversation. Given its inherent complexity and non-intuitive nature, ESConv dataset incorporates support strategies to facilitate the generation of appropriate responses. Recently, despite the remarkable conversational ability of large language models (LLMs), previous studies have suggested that they often struggle with providing useful emotional support. Hence, this work initially analyzes the results of LLMs on ESConv, revealing challenges in selecting the correct strategy and a notable preference for a specific strategy. Motivated by these, we explore the impact of the inherent preference in LLMs on providing emotional support, and consequently, we observe that exhibiting high preference for specific strategies hinders effective emotional support, aggravating its robustness in predicting the appropriate strategy. Moreover, we conduct a methodological study to offer insights into the necessary approaches for LLMs to serve as proficient emotional supporters. Our findings emphasize that (1) low preference for specific strategies hinders the progress of emotional support, (2) external assistance helps reduce preference bias, and (3) LLMs alone cannot become good emotional supporters. These insights suggest promising avenues for future research to enhance the emotional intelligence of LLMs.
Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
Dec 12, 2023Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a ``reasoning-aware'' diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback
Nov 13, 2023
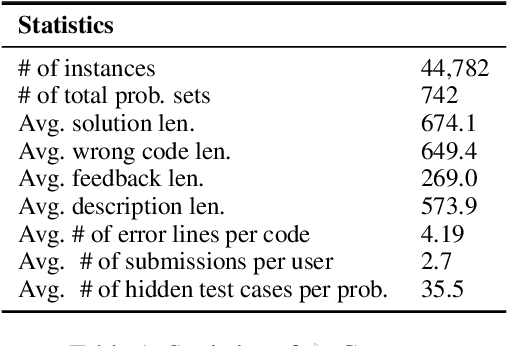


Code editing is an essential step towards reliable program synthesis to automatically correct critical errors generated from code LLMs. Recent studies have demonstrated that closed-source LLMs (i.e., ChatGPT and GPT-4) are capable of generating corrective feedback to edit erroneous inputs. However, it remains challenging for open-source code LLMs to generate feedback for code editing, since these models tend to adhere to the superficial formats of feedback and provide feedback with misleading information. Hence, the focus of our work is to leverage open-source code LLMs to generate helpful feedback with correct guidance for code editing. To this end, we present Coffee, a collected dataset specifically designed for code fixing with feedback. Using this dataset, we construct CoffeePots, a framework for COde Fixing with FEEdback via Preference-Optimized Tuning and Selection. The proposed framework aims to automatically generate helpful feedback for code editing while minimizing the potential risk of superficial feedback. The combination of Coffee and CoffeePots marks a significant advancement, achieving state-of-the-art performance on HumanEvalFix benchmark. Codes and model checkpoints are publicly available at https://github.com/Lune-Blue/COFFEE.