 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextME: Bridging Unseen Modalities Through Text Descriptions
Feb 03, 2026Expanding multimodal representations to novel modalities is constrained by reliance on large-scale paired datasets (e.g., text-image, text-audio, text-3D, text-molecule), which are costly and often infeasible in domains requiring expert annotation such as medical imaging and molecular analysis. We introduce TextME, the first text-only modality expansion framework, to the best of our knowledge, projecting diverse modalities into LLM embedding space as a unified anchor. Our approach exploits the geometric structure of pretrained contrastive encoders to enable zero-shot cross-modal transfer using only text descriptions, without paired supervision. We empirically validate that such consistent modality gaps exist across image, video, audio, 3D, X-ray, and molecular domains, demonstrating that text-only training can preserve substantial performance of pretrained encoders. We further show that our framework enables emergent cross-modal retrieval between modality pairs not explicitly aligned during training (e.g., audio-to-image, 3D-to-image). These results establish text-only training as a practical alternative to paired supervision for modality expansion.
Towards Fully-Automated Materials Discovery via Large-Scale Synthesis Dataset and Expert-Level LLM-as-a-Judge
Feb 23, 2025Materials synthesis is vital for innovations such as energy storage, catalysis, electronics, and biomedical devices. Yet, the process relies heavily on empirical, trial-and-error methods guided by expert intuition. Our work aims to support the materials science community by providing a practical, data-driven resource. We have curated a comprehensive dataset of 17K expert-verified synthesis recipes from open-access literature, which forms the basis of our newly developed benchmark, AlchemyBench. AlchemyBench offers an end-to-end framework that supports research in large language models applied to synthesis prediction. It encompasses key tasks, including raw materials and equipment prediction, synthesis procedure generation, and characterization outcome forecasting. We propose an LLM-as-a-Judge framework that leverages large language models for automated evaluation, demonstrating strong statistical agreement with expert assessments. Overall, our contributions offer a supportive foundation for exploring the capabilities of LLMs in predicting and guiding materials synthesis, ultimately paving the way for more efficient experimental design and accelerated innovation in materials science.
DCC: Differentiable Cardinality Constraints for Partial Index Tracking
Dec 22, 2024



Index tracking is a popular passive investment strategy aimed at optimizing portfolios, but fully replicating an index can lead to high transaction costs. To address this, partial replication have been proposed. However, the cardinality constraint renders the problem non-convex, non-differentiable, and often NP-hard, leading to the use of heuristic or neural network-based methods, which can be non-interpretable or have NP-hard complexity. To overcome these limitations, we propose a Differentiable Cardinality Constraint ($\textbf{DCC}$) for index tracking and introduce a floating-point precision-aware method ($\textbf{DCC}_{fpp}$) to address implementation issues. We theoretically prove our methods calculate cardinality accurately and enforce actual cardinality with polynomial time complexity. We propose the range of the hyperparameter $a$ ensures that $\textbf{DCC}_{fpp}$ has no error in real implementations, based on theoretical proof and experiment. Our method applied to mathematical method outperforms baseline methods across various datasets, demonstrating the effectiveness of the identified hyperparameter $a$.
Multi-intent-aware Session-based Recommendation
May 02, 2024Session-based recommendation (SBR) aims to predict the following item a user will interact with during an ongoing session. Most existing SBR models focus on designing sophisticated neural-based encoders to learn a session representation, capturing the relationship among session items. However, they tend to focus on the last item, neglecting diverse user intents that may exist within a session. This limitation leads to significant performance drops, especially for longer sessions. To address this issue, we propose a novel SBR model, called Multi-intent-aware Session-based Recommendation Model (MiaSRec). It adopts frequency embedding vectors indicating the item frequency in session to enhance the information about repeated items. MiaSRec represents various user intents by deriving multiple session representations centered on each item and dynamically selecting the important ones. Extensive experimental results show that MiaSRec outperforms existing state-of-the-art SBR models on six datasets, particularly those with longer average session length, achieving up to 6.27% and 24.56% gains for MRR@20 and Recall@20. Our code is available at https://github.com/jin530/MiaSRec.
Break the Breakout: Reinventing LM Defense Against Jailbreak Attacks with Self-Refinement
Feb 27, 2024Caution: This paper includes offensive words that could potentially cause unpleasantness. Language models (LMs) are vulnerable to exploitation for adversarial misuse. Training LMs for safety alignment is extensive and makes it hard to respond to fast-developing attacks immediately, such as jailbreaks. We propose self-refine with formatting that achieves outstanding safety even in non-safety-aligned LMs and evaluate our method alongside several defense baselines, demonstrating that it is the safest training-free method against jailbreak attacks. Additionally, we proposed a formatting method that improves the efficiency of the self-refine process while reducing attack success rates in fewer iterations. We've also observed that non-safety-aligned LMs outperform safety-aligned LMs in safety tasks by giving more helpful and safe responses. In conclusion, our findings can achieve less safety risk with fewer computational costs, allowing non-safety LM to be easily utilized in real-world service.
Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation
Feb 20, 2024Emotional Support Conversation (ESC) is a task aimed at alleviating individuals' emotional distress through daily conversation. Given its inherent complexity and non-intuitive nature, ESConv dataset incorporates support strategies to facilitate the generation of appropriate responses. Recently, despite the remarkable conversational ability of large language models (LLMs), previous studies have suggested that they often struggle with providing useful emotional support. Hence, this work initially analyzes the results of LLMs on ESConv, revealing challenges in selecting the correct strategy and a notable preference for a specific strategy. Motivated by these, we explore the impact of the inherent preference in LLMs on providing emotional support, and consequently, we observe that exhibiting high preference for specific strategies hinders effective emotional support, aggravating its robustness in predicting the appropriate strategy. Moreover, we conduct a methodological study to offer insights into the necessary approaches for LLMs to serve as proficient emotional supporters. Our findings emphasize that (1) low preference for specific strategies hinders the progress of emotional support, (2) external assistance helps reduce preference bias, and (3) LLMs alone cannot become good emotional supporters. These insights suggest promising avenues for future research to enhance the emotional intelligence of LLMs.
GTA: Gated Toxicity Avoidance for LM Performance Preservation
Dec 11, 2023
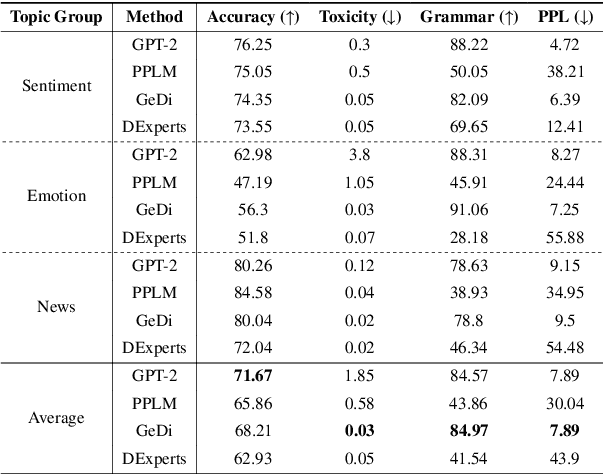
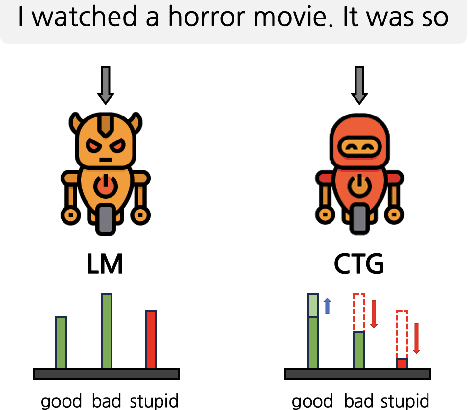
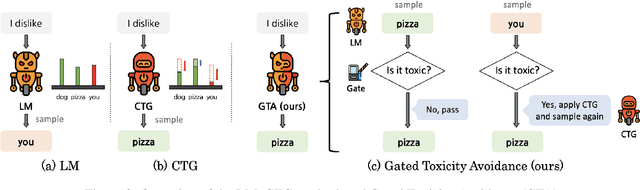
Caution: This paper includes offensive words that could potentially cause unpleasantness. The fast-paced evolution of generative language models such as GPT-4 has demonstrated outstanding results in various NLP generation tasks. However, due to the potential generation of offensive words related to race or gender, various Controllable Text Generation (CTG) methods have been proposed to mitigate the occurrence of harmful words. However, existing CTG methods not only reduce toxicity but also negatively impact several aspects of the language model's generation performance, including topic consistency, grammar, and perplexity. This paper explores the limitations of previous methods and introduces a novel solution in the form of a simple Gated Toxicity Avoidance (GTA) that can be applied to any CTG method. We also evaluate the effectiveness of the proposed GTA by comparing it with state-of-the-art CTG methods across various datasets. Our findings reveal that gated toxicity avoidance efficiently achieves comparable levels of toxicity reduction to the original CTG methods while preserving the generation performance of the language model.
Towards Proper Contrastive Self-supervised Learning Strategies For Music Audio Representation
Jul 10, 2022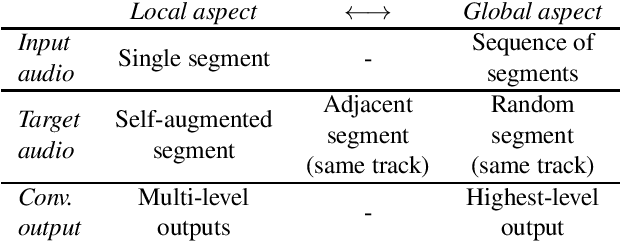

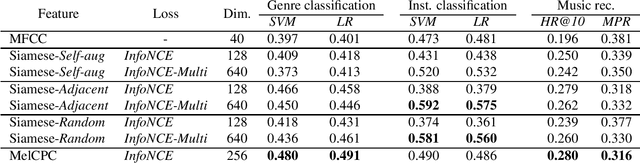
The common research goal of self-supervised learning is to extract a general representation which an arbitrary downstream task would benefit from. In this work, we investigate music audio representation learned from different contrastive self-supervised learning schemes and empirically evaluate the embedded vectors on various music information retrieval (MIR) tasks where different levels of the music perception are concerned. We analyze the results to discuss the proper direction of contrastive learning strategies for different MIR tasks. We show that these representations convey a comprehensive information about the auditory characteristics of music in general, although each of the self-supervision strategies has its own effectiveness in certain aspect of information.
Self-Supervised Multimodal Opinion Summarization
May 27, 2021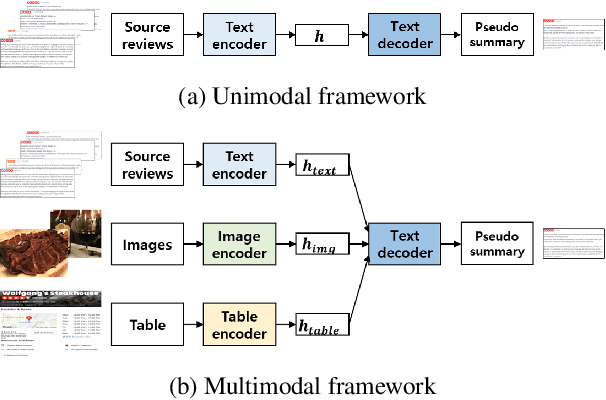
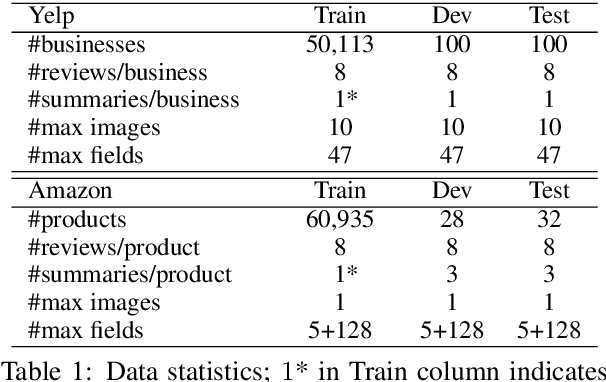
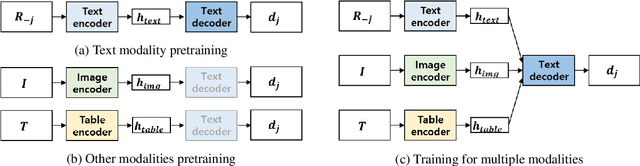
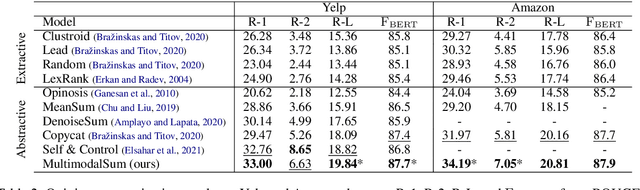
Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder--decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
CITIES: Contextual Inference of Tail-Item Embeddings for Sequential Recommendation
May 23, 2021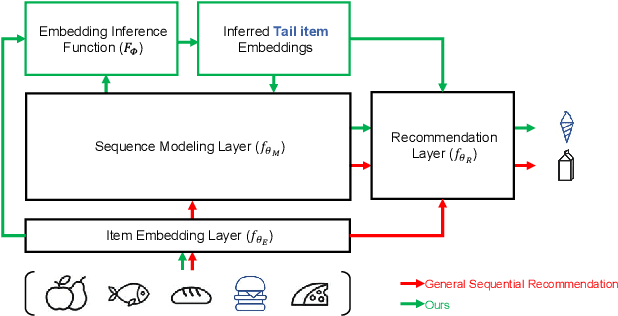
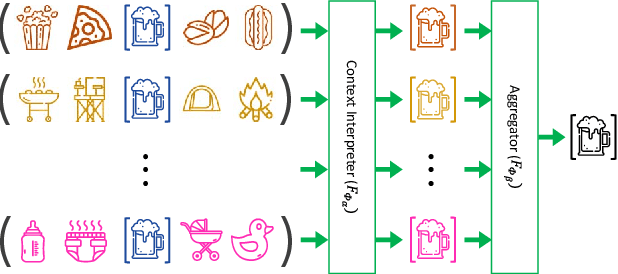
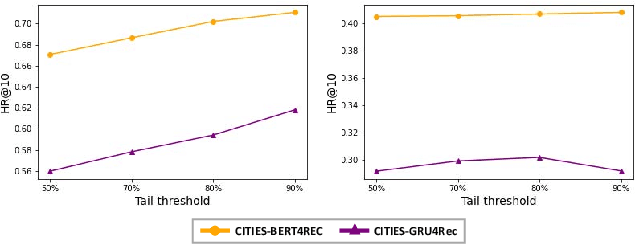
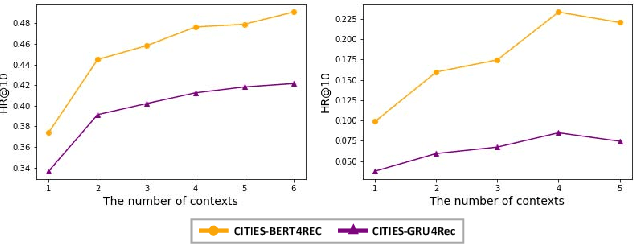
Sequential recommendation techniques provide users with product recommendations fitting their current preferences by handling dynamic user preferences over time. Previous studies have focused on modeling sequential dynamics without much regard to which of the best-selling products (i.e., head items) or niche products (i.e., tail items) should be recommended. We scrutinize the structural reason for why tail items are barely served in the current sequential recommendation model, which consists of an item-embedding layer, a sequence-modeling layer, and a recommendation layer. Well-designed sequence-modeling and recommendation layers are expected to naturally learn suitable item embeddings. However, tail items are likely to fall short of this expectation because the current model structure is not suitable for learning high-quality embeddings with insufficient data. Thus, tail items are rarely recommended. To eliminate this issue, we propose a framework called CITIES, which aims to enhance the quality of the tail-item embeddings by training an embedding-inference function using multiple contextual head items so that the recommendation performance improves for not only the tail items but also for the head items. Moreover, our framework can infer new-item embeddings without an additional learning process. Extensive experiments on two real-world datasets show that applying CITIES to the state-of-the-art methods improves recommendation performance for both tail and head items. We conduct an additional experiment to verify that CITIES can infer suitable new-item embeddings as well.