 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticShop: Benchmarking Agentic Product Curation for Personalized Web Shopping
Feb 12, 2026The proliferation of e-commerce has made web shopping platforms key gateways for customers navigating the vast digital marketplace. Yet this rapid expansion has led to a noisy and fragmented information environment, increasing cognitive burden as shoppers explore and purchase products online. With promising potential to alleviate this challenge, agentic systems have garnered growing attention for automating user-side tasks in web shopping. Despite significant advancements, existing benchmarks fail to comprehensively evaluate how well agentic systems can curate products in open-web settings. Specifically, they have limited coverage of shopping scenarios, focusing only on simplified single-platform lookups rather than exploratory search. Moreover, they overlook personalization in evaluation, leaving unclear whether agents can adapt to diverse user preferences in realistic shopping contexts. To address this gap, we present AgenticShop, the first benchmark for evaluating agentic systems on personalized product curation in open-web environment. Crucially, our approach features realistic shopping scenarios, diverse user profiles, and a verifiable, checklist-driven personalization evaluation framework. Through extensive experiments, we demonstrate that current agentic systems remain largely insufficient, emphasizing the need for user-side systems that effectively curate tailored products across the modern web.
SAGEO Arena: A Realistic Environment for Evaluating Search-Augmented Generative Engine Optimization
Feb 12, 2026Search-Augmented Generative Engines (SAGE) have emerged as a new paradigm for information access, bridging web-scale retrieval with generative capabilities to deliver synthesized answers. This shift has fundamentally reshaped how web content gains exposure online, giving rise to Search-Augmented Generative Engine Optimization (SAGEO), the practice of optimizing web documents to improve their visibility in AI-generated responses. Despite growing interest, no evaluation environment currently supports comprehensive investigation of SAGEO. Specifically, existing benchmarks lack end-to-end visibility evaluation of optimization strategies, operating on pre-determined candidate documents that abstract away retrieval and reranking preceding generation. Moreover, existing benchmarks discard structural information (e.g., schema markup) present in real web documents, overlooking the rich signals that search systems actively leverage in practice. Motivated by these gaps, we introduce SAGEO Arena, a realistic and reproducible environment for stage-level SAGEO analysis. Our objective is to jointly target search-oriented optimization (SEO) and generation-centric optimization (GEO). To achieve this, we integrate a full generative search pipeline over a large-scale corpus of web documents with rich structural information. Our findings reveal that existing approaches remain largely impractical under realistic conditions and often degrade performance in retrieval and reranking. We also find that structural information helps mitigate these limitations, and that effective SAGEO requires tailoring optimization to each pipeline stage. Overall, our benchmark paves the way for realistic SAGEO evaluation and optimization beyond simplified settings.
ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
LLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025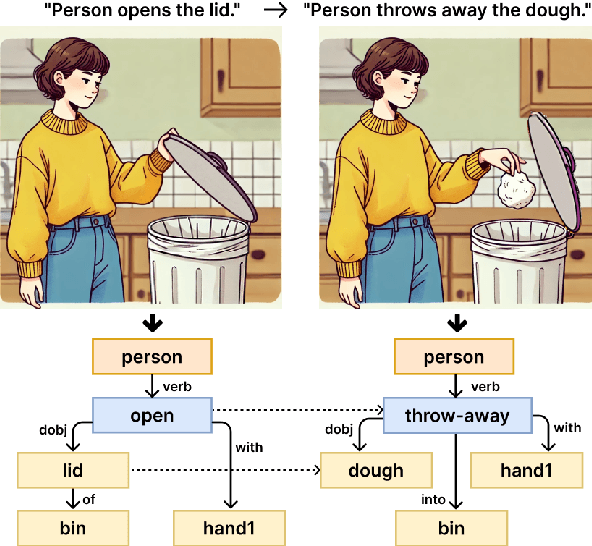

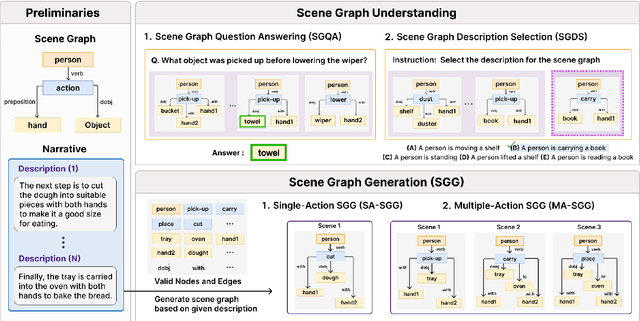

The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025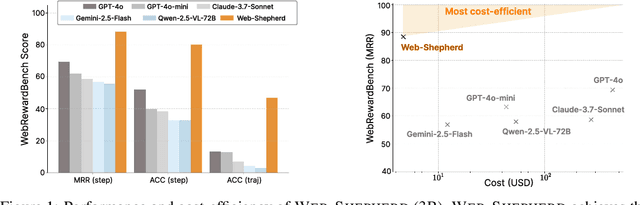


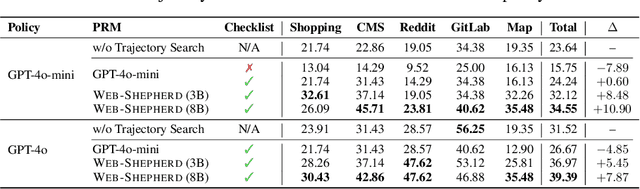
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Integration of TinyML and LargeML: A Survey of 6G and Beyond
May 20, 2025

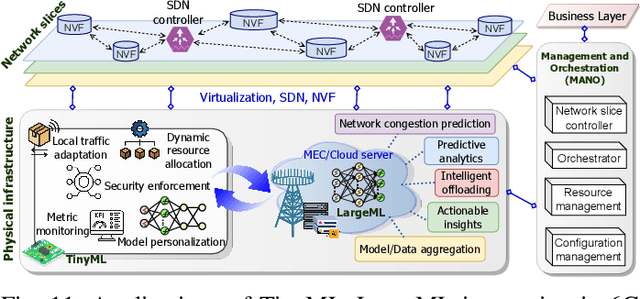
The transition from 5G networks to 6G highlights a significant demand for machine learning (ML). Deep learning models, in particular, have seen wide application in mobile networking and communications to support advanced services in emerging wireless environments, such as smart healthcare, smart grids, autonomous vehicles, aerial platforms, digital twins, and the metaverse. The rapid expansion of Internet-of-Things (IoT) devices, many with limited computational capabilities, has accelerated the development of tiny machine learning (TinyML) and resource-efficient ML approaches for cost-effective services. However, the deployment of large-scale machine learning (LargeML) solutions require major computing resources and complex management strategies to support extensive IoT services and ML-generated content applications. Consequently, the integration of TinyML and LargeML is projected as a promising approach for future seamless connectivity and efficient resource management. Although the integration of TinyML and LargeML shows abundant potential, several challenges persist, including performance optimization, practical deployment strategies, effective resource management, and security considerations. In this survey, we review and analyze the latest research aimed at enabling the integration of TinyML and LargeML models for the realization of smart services and applications in future 6G networks and beyond. The paper concludes by outlining critical challenges and identifying future research directions for the holistic integration of TinyML and LargeML in next-generation wireless networks.
Rethinking Reward Model Evaluation Through the Lens of Reward Overoptimization
May 19, 2025Reward models (RMs) play a crucial role in reinforcement learning from human feedback (RLHF), aligning model behavior with human preferences. However, existing benchmarks for reward models show a weak correlation with the performance of optimized policies, suggesting that they fail to accurately assess the true capabilities of RMs. To bridge this gap, we explore several evaluation designs through the lens of reward overoptimization\textemdash a phenomenon that captures both how well the reward model aligns with human preferences and the dynamics of the learning signal it provides to the policy. The results highlight three key findings on how to construct a reliable benchmark: (i) it is important to minimize differences between chosen and rejected responses beyond correctness, (ii) evaluating reward models requires multiple comparisons across a wide range of chosen and rejected responses, and (iii) given that reward models encounter responses with diverse representations, responses should be sourced from a variety of models. However, we also observe that a extremely high correlation with degree of overoptimization leads to comparatively lower correlation with certain downstream performance. Thus, when designing a benchmark, it is desirable to use the degree of overoptimization as a useful tool, rather than the end goal.
MISO: Multiresolution Submap Optimization for Efficient Globally Consistent Neural Implicit Reconstruction
Apr 27, 2025



Neural implicit representations have had a significant impact on simultaneous localization and mapping (SLAM) by enabling robots to build continuous, differentiable, and high-fidelity 3D maps from sensor data. However, as the scale and complexity of the environment increase, neural SLAM approaches face renewed challenges in the back-end optimization process to keep up with runtime requirements and maintain global consistency. We introduce MISO, a hierarchical optimization approach that leverages multiresolution submaps to achieve efficient and scalable neural implicit reconstruction. For local SLAM within each submap, we develop a hierarchical optimization scheme with learned initialization that substantially reduces the time needed to optimize the implicit submap features. To correct estimation drift globally, we develop a hierarchical method to align and fuse the multiresolution submaps, leading to substantial acceleration by avoiding the need to decode the full scene geometry. MISO significantly improves computational efficiency and estimation accuracy of neural signed distance function (SDF) SLAM on large-scale real-world benchmarks.
Stop Playing the Guessing Game! Target-free User Simulation for Evaluating Conversational Recommender Systems
Nov 25, 2024Recent approaches in Conversational Recommender Systems (CRSs) have tried to simulate real-world users engaging in conversations with CRSs to create more realistic testing environments that reflect the complexity of human-agent dialogue. Despite the significant advancements, reliably evaluating the capability of CRSs to elicit user preferences still faces a significant challenge. Existing evaluation metrics often rely on target-biased user simulators that assume users have predefined preferences, leading to interactions that devolve into simplistic guessing game. These simulators typically guide the CRS toward specific target items based on fixed attributes, limiting the dynamic exploration of user preferences and struggling to capture the evolving nature of real-user interactions. Additionally, current evaluation metrics are predominantly focused on single-turn recall of target items, neglecting the intermediate processes of preference elicitation. To address this, we introduce PEPPER, a novel CRS evaluation protocol with target-free user simulators constructed from real-user interaction histories and reviews. PEPPER enables realistic user-CRS dialogues without falling into simplistic guessing games, allowing users to gradually discover their preferences through enriched interactions, thereby providing a more accurate and reliable assessment of the CRS's ability to elicit personal preferences. Furthermore, PEPPER presents detailed measures for comprehensively evaluating the preference elicitation capabilities of CRSs, encompassing both quantitative and qualitative measures that capture four distinct aspects of the preference elicitation process. Through extensive experiments, we demonstrate the validity of PEPPER as a simulation environment and conduct a thorough analysis of how effectively existing CRSs perform in preference elicitation and recommendation.