 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBGuard: Constructing Hazard-Aware Guardrails for Safe Planning in Embodied Agents
May 29, 2026MLLM-powered embodied agents deployed in real-world environments encounter physical hazards. However, existing approaches lack explicit mechanisms for identifying hazards and reasoning about action-conditioned risks, leading agents to either miss risky interactions or over-identify risks. To address this, we propose EMBGuard, the first MLLM-based safety guardrail for embodied agents designed to decouple physical risk reasoning from agent policy. By evaluating a (visual observation, action) pair, EMBGuard identifies hazardous configurations and provides natural language explanations of potential risks. Alongside EMBGuard, we contribute EMBHazard, a training dataset of 15.1K action-conditioned pairs, and EMBGuardTest, a benchmark of 329 manually curated real-world scenarios spanning seven physical risk categories. Through compositional variation of hazards and actions, we generate diverse risky and benign scenarios that agents may encounter during planning. Despite its compact size (2B, 4B), EMBGuard achieves performance competitive with proprietary MLLMs (e.g., GPT-5.1, Gemini-2.5-Pro) while significantly reducing the false-positive rates that hinder real-time deployment. We make the code, data, and models publicly available at https://github.com/dongwxxkchoi/EMBGuard
Framing Matters: Addressing Framing Sensitivity in Decision-Making through Behaviorally-Grounded Value Alignment
May 27, 2026Large Language Models (LLMs) are increasingly deployed in high-stakes decision-making settings such as legal reasoning, where consistency under factually equivalent inputs is critical. However, we find that fact-preserved but differently framed inputs can significantly destabilize LLM decisions. To systematically investigate this problem, we introduce Fragile, a large-scale benchmark that isolates fact-preserving semantic framing across three controlled dimensions: value-tinted narration, temporal slice, and narrative vividness. Our experiments reveal a high susceptibility of LLMs to framing, with an average decision flip rate of 28.6%. We find that simple prior prompt-level and activation-level interventions not only fail to suppress framing sensitivity but actively amplify it. We therefore propose Valign, a representation-level method that explicitly targets these framing dimensions by anchoring decisions to a stable value prior, steering hidden states toward the model's value-consistent direction, and projecting out temporal-vividness-sensitive directions from the model's hidden states. Valign consistently reduces framing-induced decision flips, demonstrating that robust mitigation requires directly targeting the internal pathways in which framing operates.
PaP-NF: Probabilistic Long-Term Time Series Forecasting via Prefix-as-Prompt Reprogramming and Normalizing Flows
May 22, 2026Time series forecasting plays a central role in many real-world applications and has been extensively studied. Most existing approaches rely on deterministic models. However, real-world environments exhibit inherently uncertain and complex future behaviors, making single-point predictions insufficient. This highlights the need for probabilistic forecasting methods that can quantify and represent uncertainty. In this work, we propose PaP-NF, a probabilistic forecasting framework that aligns continuous time series representations with a frozen large language model (LLM) using a Prefix-as-Prompt mechanism, and conditions a normalizing flow decoder on the global context extracted by the LLM. The quality of the resulting predictive distributions is evaluated using the Continuous Ranked Probability Score (CRPS), a standard metric in probabilistic forecasting. Across a variety of long-term forecasting benchmarks, PaP-NF robustly captures multi-modal uncertainty while maintaining competitive point forecasting accuracy. The official implementation is available at: https://github.com/democracy04/PaP-NF
PAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Apr 13, 2026We are entering an era in which individuals and organizations increasingly deploy dedicated AI agents that interact and collaborate with other agents. However, the dynamics of multi-agent collaboration under privacy constraints remain poorly understood. In this work, we present $PAC\text{-}Bench$, a benchmark for systematic evaluation of multi-agent collaboration under privacy constraints. Experiments on $PAC\text{-}Bench$ show that privacy constraints substantially degrade collaboration performance and make outcomes depend more on the initiating agent than the partner. Further analysis reveals that this degradation is driven by recurring coordination breakdowns, including early-stage privacy violations, overly conservative abstraction, and privacy-induced hallucinations. Together, our findings identify privacy-aware multi-agent collaboration as a distinct and unresolved challenge that requires new coordination mechanisms beyond existing agent capabilities.
CONDESION-BENCH: Conditional Decision-Making of Large Language Models in Compositional Action Space
Apr 10, 2026Large language models have been widely explored as decision-support tools in high-stakes domains due to their contextual understanding and reasoning capabilities. However, existing decision-making benchmarks rely on two simplifying assumptions: actions are selected from a finite set of pre-defined candidates, and explicit conditions restricting action feasibility are not incorporated into the decision-making process. These assumptions fail to capture the compositional structure of real-world actions and the explicit conditions that constrain their validity. To address these limitations, we introduce CONDESION-BENCH, a benchmark designed to evaluate conditional decision-making in compositional action space. In CONDESION-BENCH, actions are defined as allocations to decision variables and are restricted by explicit conditions at the variable, contextual, and allocation levels. By employing oracle-based evaluation of both decision quality and condition adherence, we provide a more rigorous assessment of LLMs as decision-support tools.
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
A Stereotype Content Analysis on Color-related Social Bias in Large Vision Language Models
May 27, 2025As large vision language models(LVLMs) rapidly advance, concerns about their potential to learn and generate social biases and stereotypes are increasing. Previous studies on LVLM's stereotypes face two primary limitations: metrics that overlooked the importance of content words, and datasets that overlooked the effect of color. To address these limitations, this study introduces new evaluation metrics based on the Stereotype Content Model (SCM). We also propose BASIC, a benchmark for assessing gender, race, and color stereotypes. Using SCM metrics and BASIC, we conduct a study with eight LVLMs to discover stereotypes. As a result, we found three findings. (1) The SCM-based evaluation is effective in capturing stereotypes. (2) LVLMs exhibit color stereotypes in the output along with gender and race ones. (3) Interaction between model architecture and parameter sizes seems to affect stereotypes. We release BASIC publicly on [anonymized for review].
PHISH in MESH: Korean Adversarial Phonetic Substitution and Phonetic-Semantic Feature Integration Defense
May 27, 2025As malicious users increasingly employ phonetic substitution to evade hate speech detection, researchers have investigated such strategies. However, two key challenges remain. First, existing studies have overlooked the Korean language, despite its vulnerability to phonetic perturbations due to its phonographic nature. Second, prior work has primarily focused on constructing datasets rather than developing architectural defenses. To address these challenges, we propose (1) PHonetic-Informed Substitution for Hangul (PHISH) that exploits the phonological characteristics of the Korean writing system, and (2) Mixed Encoding of Semantic-pHonetic features (MESH) that enhances the detector's robustness by incorporating phonetic information at the architectural level. Our experimental results demonstrate the effectiveness of our proposed methods on both perturbed and unperturbed datasets, suggesting that they not only improve detection performance but also reflect realistic adversarial behaviors employed by malicious users.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025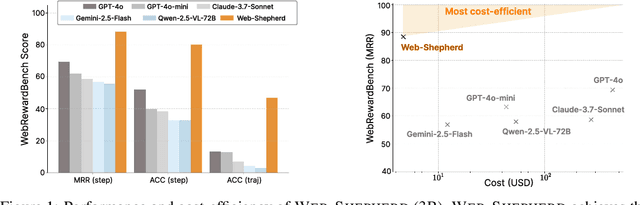


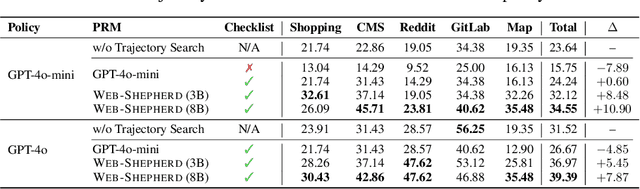
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.