 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVorTEX: Various overlap ratio for Target speech EXtraction
Mar 17, 2026Target speech extraction (TSE) aims to recover a target speaker's voice from a mixture. While recent text-prompted approaches have shown promise, most approaches assume fully overlapped mixtures, limiting insight into behavior across realistic overlap ratios. We introduce VorTEX (Various overlap ratio for Target speech EXtraction), a text-prompted TSE architecture with a Decoupled Adaptive Multi-branch (DAM) Fusion block that separates primary extraction from auxiliary regularization pathways. To enable controlled analysis, we construct PORTE, a two-speaker dataset spanning overlap ratios from 0% to 100%. We further propose Suppression Ratio on Energy (SuRE), a diagnostic metric that detects suppression behavior not captured by conventional measures. Experiments show that existing models exhibit suppression or residual interference under overlap, whereas VorTEX achieves the highest separation fidelity across 20-100% overlap (e.g., 5.50 dB at 20% and 2.04 dB at 100%) while maintaining zero SuRE, indicating robust extraction without suppression-driven artifacts.
Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
Jan 31, 2026While LLM-as-a-Judge is widely used in automated evaluation, existing validation practices primarily operate at the level of observed outputs, offering limited insight into whether LLM judges themselves function as stable and reliable measurement instruments. To address this limitation, we introduce a two-phase diagnostic framework for assessing reliability of LLM-as-a-Judge, grounded in Item Response Theory (IRT). The framework adopts Graded Response Model (GRM) of IRT and formalizes reliability along two complementary dimensions: (1) intrinsic consistency, defined as the stability of measurement behavior under prompt variations, and (2) human alignment, capturing correspondence with human quality assessments. We empirically examine diverse LLM judges with this framework, and show that leveraging IRT-GRM yields interpretable signals for diagnosing judgments systematically. These signals provide practical guidance for verifying reliablity of LLM-as-a-Judge and identifying potential causes of unreliability.
Belief in Authority: Impact of Authority in Multi-Agent Evaluation Framework
Jan 08, 2026Multi-agent systems utilizing large language models often assign authoritative roles to improve performance, yet the impact of authority bias on agent interactions remains underexplored. We present the first systematic analysis of role-based authority bias in free-form multi-agent evaluation using ChatEval. Applying French and Raven's power-based theory, we classify authoritative roles into legitimate, referent, and expert types and analyze their influence across 12-turn conversations. Experiments with GPT-4o and DeepSeek R1 reveal that Expert and Referent power roles exert stronger influence than Legitimate power roles. Crucially, authority bias emerges not through active conformity by general agents, but through authoritative roles consistently maintaining their positions while general agents demonstrate flexibility. Furthermore, authority influence requires clear position statements, as neutral responses fail to generate bias. These findings provide key insights for designing multi-agent frameworks with asymmetric interaction patterns.
A Stereotype Content Analysis on Color-related Social Bias in Large Vision Language Models
May 27, 2025As large vision language models(LVLMs) rapidly advance, concerns about their potential to learn and generate social biases and stereotypes are increasing. Previous studies on LVLM's stereotypes face two primary limitations: metrics that overlooked the importance of content words, and datasets that overlooked the effect of color. To address these limitations, this study introduces new evaluation metrics based on the Stereotype Content Model (SCM). We also propose BASIC, a benchmark for assessing gender, race, and color stereotypes. Using SCM metrics and BASIC, we conduct a study with eight LVLMs to discover stereotypes. As a result, we found three findings. (1) The SCM-based evaluation is effective in capturing stereotypes. (2) LVLMs exhibit color stereotypes in the output along with gender and race ones. (3) Interaction between model architecture and parameter sizes seems to affect stereotypes. We release BASIC publicly on [anonymized for review].
PHISH in MESH: Korean Adversarial Phonetic Substitution and Phonetic-Semantic Feature Integration Defense
May 27, 2025As malicious users increasingly employ phonetic substitution to evade hate speech detection, researchers have investigated such strategies. However, two key challenges remain. First, existing studies have overlooked the Korean language, despite its vulnerability to phonetic perturbations due to its phonographic nature. Second, prior work has primarily focused on constructing datasets rather than developing architectural defenses. To address these challenges, we propose (1) PHonetic-Informed Substitution for Hangul (PHISH) that exploits the phonological characteristics of the Korean writing system, and (2) Mixed Encoding of Semantic-pHonetic features (MESH) that enhances the detector's robustness by incorporating phonetic information at the architectural level. Our experimental results demonstrate the effectiveness of our proposed methods on both perturbed and unperturbed datasets, suggesting that they not only improve detection performance but also reflect realistic adversarial behaviors employed by malicious users.
DART: An AIGT Detector using AMR of Rephrased Text
Dec 16, 2024As large language models (LLMs) generate more human-like texts, concerns about the side effects of AI-generated texts (AIGT) have grown. So, researchers have developed methods for detecting AIGT. However, two challenges remain. First, the performance on detecting black-box LLMs is low, because existing models have focused on syntactic features. Second, most AIGT detectors have been tested on a single-candidate setting, which assumes that we know the origin of an AIGT and may deviate from the real-world scenario. To resolve these challenges, we propose DART, which consists of four steps: rephrasing, semantic parsing, scoring, and multiclass classification. We conducted several experiments to test the performance of DART by following previous work. The experimental result shows that DART can discriminate multiple black-box LLMs without using syntactic features and knowing the origin of AIGT.
Leveraging Large Language Models for Active Merchant Non-player Characters
Dec 15, 2024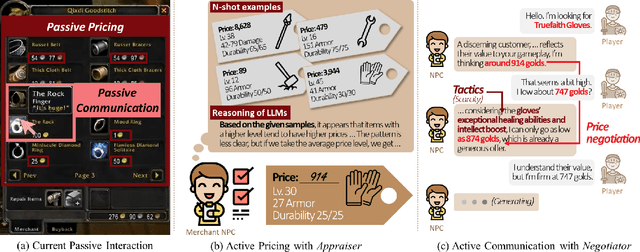
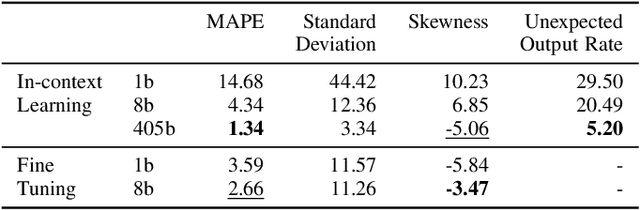


We highlight two significant issues leading to the passivity of current merchant non-player characters (NPCs): pricing and communication. While immersive interactions have been a focus, negotiations between merchant NPCs and players on item prices have not received sufficient attention. First, we define passive pricing as the limited ability of merchants to modify predefined item prices. Second, passive communication means that merchants can only interact with players in a scripted manner. To tackle these issues and create an active merchant NPC, we propose a merchant framework based on large language models (LLMs), called MART, which consists of an appraiser module and a negotiator module. We conducted two experiments to guide game developers in selecting appropriate implementations by comparing different training methods and LLM sizes. Our findings indicate that finetuning methods, such as supervised finetuning (SFT) and knowledge distillation (KD), are effective in using smaller LLMs to implement active merchant NPCs. Additionally, we found three irregular cases arising from the responses of LLMs. We expect our findings to guide developers in using LLMs for developing active merchant NPCs.
Does chat change LLM's mind? Impact of Conversation on Psychological States of LLMs
Dec 01, 2024



The recent growth of large language models (LLMs) has enabled more authentic, human-centered interactions through multi-agent systems. However, investigation into how conversations affect the psychological states of LLMs is limited, despite the impact of these states on the usability of LLM-based systems. In this study, we explored whether psychological states change during multi-agent interactions, focusing on the effects of conversation depth, topic, and speaker. We experimentally investigated the behavior of 10 LLMs in open-domain conversations. We employed 14 questionnaires and a topic-analysis method to examine the behavior of LLMs across four aspects: personality, interpersonal relationships, motivation, and emotion. The results revealed distinct psychological trends influenced by conversation depth and topic, with significant variations observed between different LLM families and parameter sizes.
Microscopic Analysis on LLM players via Social Deduction Game
Aug 19, 2024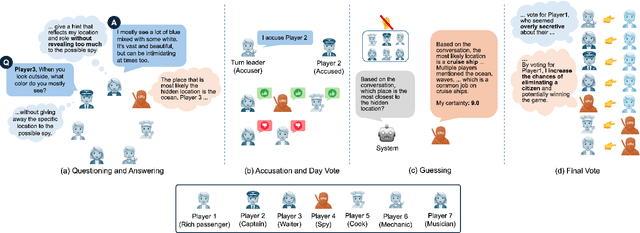



Recent studies have begun developing autonomous game players for social deduction games using large language models (LLMs). When building LLM players, fine-grained evaluations are crucial for addressing weaknesses in game-playing abilities. However, existing studies have often overlooked such assessments. Specifically, we point out two issues with the evaluation methods employed. First, game-playing abilities have typically been assessed through game-level outcomes rather than specific event-level skills; Second, error analyses have lacked structured methodologies. To address these issues, we propose an approach utilizing a variant of the SpyFall game, named SpyGame. We conducted an experiment with four LLMs, analyzing their gameplay behavior in SpyGame both quantitatively and qualitatively. For the quantitative analysis, we introduced eight metrics to resolve the first issue, revealing that these metrics are more effective than existing ones for evaluating the two critical skills: intent identification and camouflage. In the qualitative analysis, we performed thematic analysis to resolve the second issue. This analysis identifies four major categories that affect gameplay of LLMs. Additionally, we demonstrate how these categories complement and support the findings from the quantitative analysis.