 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Active Merchant Non-player Characters
Dec 15, 2024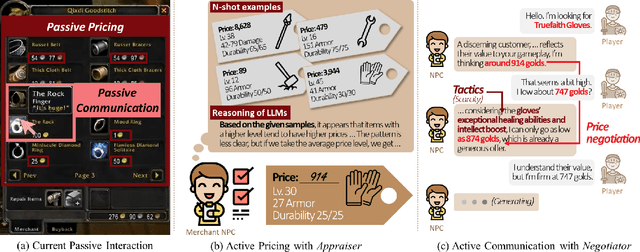
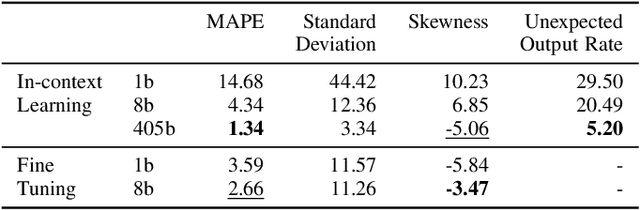


We highlight two significant issues leading to the passivity of current merchant non-player characters (NPCs): pricing and communication. While immersive interactions have been a focus, negotiations between merchant NPCs and players on item prices have not received sufficient attention. First, we define passive pricing as the limited ability of merchants to modify predefined item prices. Second, passive communication means that merchants can only interact with players in a scripted manner. To tackle these issues and create an active merchant NPC, we propose a merchant framework based on large language models (LLMs), called MART, which consists of an appraiser module and a negotiator module. We conducted two experiments to guide game developers in selecting appropriate implementations by comparing different training methods and LLM sizes. Our findings indicate that finetuning methods, such as supervised finetuning (SFT) and knowledge distillation (KD), are effective in using smaller LLMs to implement active merchant NPCs. Additionally, we found three irregular cases arising from the responses of LLMs. We expect our findings to guide developers in using LLMs for developing active merchant NPCs.
Microscopic Analysis on LLM players via Social Deduction Game
Aug 19, 2024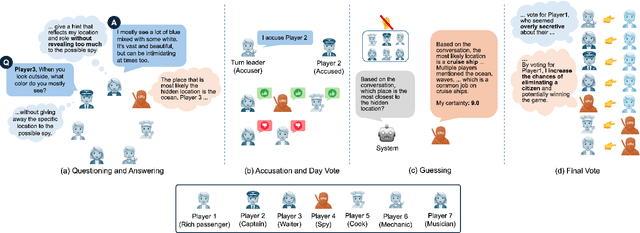



Recent studies have begun developing autonomous game players for social deduction games using large language models (LLMs). When building LLM players, fine-grained evaluations are crucial for addressing weaknesses in game-playing abilities. However, existing studies have often overlooked such assessments. Specifically, we point out two issues with the evaluation methods employed. First, game-playing abilities have typically been assessed through game-level outcomes rather than specific event-level skills; Second, error analyses have lacked structured methodologies. To address these issues, we propose an approach utilizing a variant of the SpyFall game, named SpyGame. We conducted an experiment with four LLMs, analyzing their gameplay behavior in SpyGame both quantitatively and qualitatively. For the quantitative analysis, we introduced eight metrics to resolve the first issue, revealing that these metrics are more effective than existing ones for evaluating the two critical skills: intent identification and camouflage. In the qualitative analysis, we performed thematic analysis to resolve the second issue. This analysis identifies four major categories that affect gameplay of LLMs. Additionally, we demonstrate how these categories complement and support the findings from the quantitative analysis.