 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRDexDB: A Large-Scale Dataset of Dexterous Human and Robotic Hand Grasps
Apr 16, 2026We present HRDexDB, a large-scale, multi-modal dataset of high-fidelity dexterous grasping sequences featuring both human and diverse robotic hands. Unlike existing datasets, HRDexDB provides a comprehensive collection of grasping trajectories across human hands and multiple robot hand embodiments, spanning 100 diverse objects. Leveraging state-of-the-art vision methods and a new dedicated multi-camera system, our HRDexDB offers high-precision spatiotemporal 3D ground-truth motion for both the agent and the manipulated object. To facilitate the study of physical interaction, HRDexDB includes high-resolution tactile signals, synchronized multi-view video, and egocentric video streams. The dataset comprises 1.4K grasping trials, encompassing both successes and failures, each enriched with visual, kinematic, and tactile modalities. By providing closely aligned captures of human dexterity and robotic execution on the same target objects under comparable grasping motions, HRDexDB serves as a foundational benchmark for multi-modal policy learning and cross-domain dexterous manipulation.
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
Apr 06, 2026We present Vanast, a unified framework that generates garment-transferred human animation videos directly from a single human image, garment images, and a pose guidance video. Conventional two-stage pipelines treat image-based virtual try-on and pose-driven animation as separate processes, which often results in identity drift, garment distortion, and front-back inconsistency. Our model addresses these issues by performing the entire process in a single unified step to achieve coherent synthesis. To enable this setting, we construct large-scale triplet supervision. Our data generation pipeline includes generating identity-preserving human images in alternative outfits that differ from garment catalog images, capturing full upper and lower garment triplets to overcome the single-garment-posed video pair limitation, and assembling diverse in-the-wild triplets without requiring garment catalog images. We further introduce a Dual Module architecture for video diffusion transformers to stabilize training, preserve pretrained generative quality, and improve garment accuracy, pose adherence, and identity preservation while supporting zero-shot garment interpolation. Together, these contributions allow Vanast to produce high-fidelity, identity-consistent animation across a wide range of garment types.
MotionCFG: Boosting Motion Dynamics via Stochastic Concept Perturbation
Mar 14, 2026Despite recent advances in Text-to-Video (T2V) synthesis, generating high-fidelity and dynamic motion remains a significant challenge. Existing methods primarily rely on Classifier-Free Guidance (CFG), often with explicit negative prompts (e.g. "static", "blurry"), to suppress undesired artifacts. However, such explicit negations frequently introduce unintended semantic bias and distort object integrity; a phenomenon we define as Content-Motion Drift. To address this, we propose MotionCFG, a framework that enhances motion dynamics by contrasting a target concept with its noise-perturbed counterparts. Specifically, by injecting Gaussian noise into the concept embeddings, MotionCFG creates localized negative anchors that encapsulate a broad complementary space of sub-optimal motion variations. Unlike explicit negations, this approach facilitates implicit hard negative mining without shifting the global semantic identity, allowing for a focused refinement of temporal details. Combined with a piecewise guidance schedule that confines intervention to the early denoising steps, MotionCFG consistently improves motion dynamics across state-of-the-art T2V frameworks with negligible computational overhead and minimal compromise in visual quality. Additionally, we demonstrate that this noise-induced contrastive mechanism is effective not only for sharpening motion trajectories but also for steering complex, non-linear concepts such as precise object numerosity, which are typically difficult to modulate via standard text-based guidance.
Dexterous World Models
Dec 19, 2025



Recent progress in 3D reconstruction has made it easy to create realistic digital twins from everyday environments. However, current digital twins remain largely static and are limited to navigation and view synthesis without embodied interactivity. To bridge this gap, we introduce Dexterous World Model (DWM), a scene-action-conditioned video diffusion framework that models how dexterous human actions induce dynamic changes in static 3D scenes. Given a static 3D scene rendering and an egocentric hand motion sequence, DWM generates temporally coherent videos depicting plausible human-scene interactions. Our approach conditions video generation on (1) static scene renderings following a specified camera trajectory to ensure spatial consistency, and (2) egocentric hand mesh renderings that encode both geometry and motion cues to model action-conditioned dynamics directly. To train DWM, we construct a hybrid interaction video dataset. Synthetic egocentric interactions provide fully aligned supervision for joint locomotion and manipulation learning, while fixed-camera real-world videos contribute diverse and realistic object dynamics. Experiments demonstrate that DWM enables realistic and physically plausible interactions, such as grasping, opening, and moving objects, while maintaining camera and scene consistency. This framework represents a first step toward video diffusion-based interactive digital twins and enables embodied simulation from egocentric actions.
Decoding the Poetic Language of Emotion in Korean Modern Poetry: Insights from a Human-Labeled Dataset and AI Modeling
Sep 04, 2025This study introduces KPoEM (Korean Poetry Emotion Mapping) , a novel dataset for computational emotion analysis in modern Korean poetry. Despite remarkable progress in text-based emotion classification using large language models, poetry-particularly Korean poetry-remains underexplored due to its figurative language and cultural specificity. We built a multi-label emotion dataset of 7,662 entries, including 7,007 line-level entries from 483 poems and 615 work-level entries, annotated with 44 fine-grained emotion categories from five influential Korean poets. A state-of-the-art Korean language model fine-tuned on this dataset significantly outperformed previous models, achieving 0.60 F1-micro compared to 0.34 from models trained on general corpora. The KPoEM model, trained through sequential fine-tuning-first on general corpora and then on the KPoEM dataset-demonstrates not only an enhanced ability to identify temporally and culturally specific emotional expressions, but also a strong capacity to preserve the core sentiments of modern Korean poetry. This study bridges computational methods and literary analysis, presenting new possibilities for the quantitative exploration of poetic emotions through structured data that faithfully retains the emotional and cultural nuances of Korean literature.
Durian: Dual Reference-guided Portrait Animation with Attribute Transfer
Sep 04, 2025We present Durian, the first method for generating portrait animation videos with facial attribute transfer from a given reference image to a target portrait in a zero-shot manner. To enable high-fidelity and spatially consistent attribute transfer across frames, we introduce dual reference networks that inject spatial features from both the portrait and attribute images into the denoising process of a diffusion model. We train the model using a self-reconstruction formulation, where two frames are sampled from the same portrait video: one is treated as the attribute reference and the other as the target portrait, and the remaining frames are reconstructed conditioned on these inputs and their corresponding masks. To support the transfer of attributes with varying spatial extent, we propose a mask expansion strategy using keypoint-conditioned image generation for training. In addition, we further augment the attribute and portrait images with spatial and appearance-level transformations to improve robustness to positional misalignment between them. These strategies allow the model to effectively generalize across diverse attributes and in-the-wild reference combinations, despite being trained without explicit triplet supervision. Durian achieves state-of-the-art performance on portrait animation with attribute transfer, and notably, its dual reference design enables multi-attribute composition in a single generation pass without additional training.
PHISH in MESH: Korean Adversarial Phonetic Substitution and Phonetic-Semantic Feature Integration Defense
May 27, 2025As malicious users increasingly employ phonetic substitution to evade hate speech detection, researchers have investigated such strategies. However, two key challenges remain. First, existing studies have overlooked the Korean language, despite its vulnerability to phonetic perturbations due to its phonographic nature. Second, prior work has primarily focused on constructing datasets rather than developing architectural defenses. To address these challenges, we propose (1) PHonetic-Informed Substitution for Hangul (PHISH) that exploits the phonological characteristics of the Korean writing system, and (2) Mixed Encoding of Semantic-pHonetic features (MESH) that enhances the detector's robustness by incorporating phonetic information at the architectural level. Our experimental results demonstrate the effectiveness of our proposed methods on both perturbed and unperturbed datasets, suggesting that they not only improve detection performance but also reflect realistic adversarial behaviors employed by malicious users.
DART: An AIGT Detector using AMR of Rephrased Text
Dec 16, 2024As large language models (LLMs) generate more human-like texts, concerns about the side effects of AI-generated texts (AIGT) have grown. So, researchers have developed methods for detecting AIGT. However, two challenges remain. First, the performance on detecting black-box LLMs is low, because existing models have focused on syntactic features. Second, most AIGT detectors have been tested on a single-candidate setting, which assumes that we know the origin of an AIGT and may deviate from the real-world scenario. To resolve these challenges, we propose DART, which consists of four steps: rephrasing, semantic parsing, scoring, and multiclass classification. We conducted several experiments to test the performance of DART by following previous work. The experimental result shows that DART can discriminate multiple black-box LLMs without using syntactic features and knowing the origin of AIGT.
Leveraging Large Language Models for Active Merchant Non-player Characters
Dec 15, 2024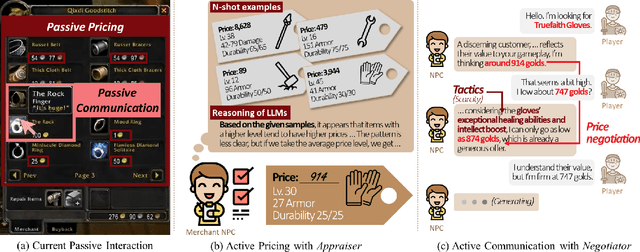
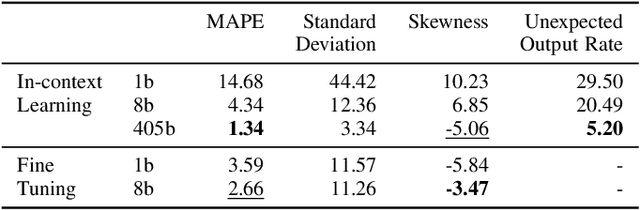


We highlight two significant issues leading to the passivity of current merchant non-player characters (NPCs): pricing and communication. While immersive interactions have been a focus, negotiations between merchant NPCs and players on item prices have not received sufficient attention. First, we define passive pricing as the limited ability of merchants to modify predefined item prices. Second, passive communication means that merchants can only interact with players in a scripted manner. To tackle these issues and create an active merchant NPC, we propose a merchant framework based on large language models (LLMs), called MART, which consists of an appraiser module and a negotiator module. We conducted two experiments to guide game developers in selecting appropriate implementations by comparing different training methods and LLM sizes. Our findings indicate that finetuning methods, such as supervised finetuning (SFT) and knowledge distillation (KD), are effective in using smaller LLMs to implement active merchant NPCs. Additionally, we found three irregular cases arising from the responses of LLMs. We expect our findings to guide developers in using LLMs for developing active merchant NPCs.
Microscopic Analysis on LLM players via Social Deduction Game
Aug 19, 2024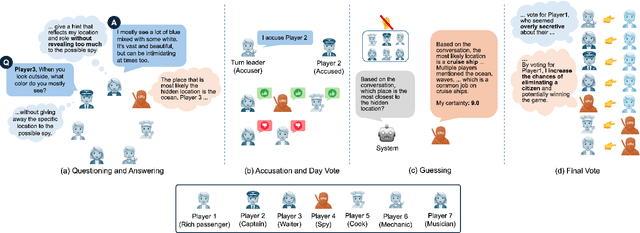



Recent studies have begun developing autonomous game players for social deduction games using large language models (LLMs). When building LLM players, fine-grained evaluations are crucial for addressing weaknesses in game-playing abilities. However, existing studies have often overlooked such assessments. Specifically, we point out two issues with the evaluation methods employed. First, game-playing abilities have typically been assessed through game-level outcomes rather than specific event-level skills; Second, error analyses have lacked structured methodologies. To address these issues, we propose an approach utilizing a variant of the SpyFall game, named SpyGame. We conducted an experiment with four LLMs, analyzing their gameplay behavior in SpyGame both quantitatively and qualitatively. For the quantitative analysis, we introduced eight metrics to resolve the first issue, revealing that these metrics are more effective than existing ones for evaluating the two critical skills: intent identification and camouflage. In the qualitative analysis, we performed thematic analysis to resolve the second issue. This analysis identifies four major categories that affect gameplay of LLMs. Additionally, we demonstrate how these categories complement and support the findings from the quantitative analysis.