 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Object Detection with Instance Representation Learning
Sep 24, 2024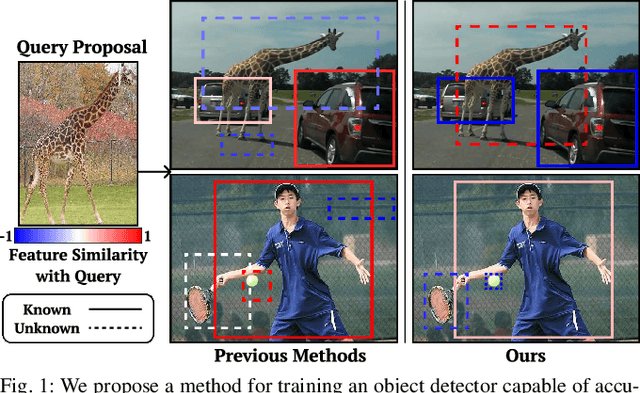
While humans naturally identify novel objects and understand their relationships, deep learning-based object detectors struggle to detect and relate objects that are not observed during training. To overcome this issue, Open World Object Detection(OWOD) has been introduced to enable models to detect unknown objects in open-world scenarios. However, OWOD methods fail to capture the fine-grained relationships between detected objects, which are crucial for comprehensive scene understanding and applications such as class discovery and tracking. In this paper, we propose a method to train an object detector that can both detect novel objects and extract semantically rich features in open-world conditions by leveraging the knowledge of Vision Foundation Models(VFM). We first utilize the semantic masks from the Segment Anything Model to supervise the box regression of unknown objects, ensuring accurate localization. By transferring the instance-wise similarities obtained from the VFM features to the detector's instance embeddings, our method then learns a semantically rich feature space of these embeddings. Extensive experiments show that our method learns a robust and generalizable feature space, outperforming other OWOD-based feature extraction methods. Additionally, we demonstrate that the enhanced feature from our model increases the detector's applicability to tasks such as open-world tracking.
Evidential Semantic Mapping in Off-road Environments with Uncertainty-aware Bayesian Kernel Inference
Mar 21, 2024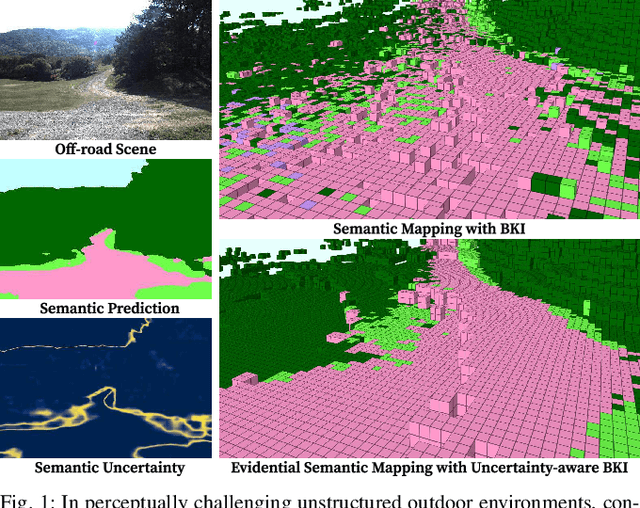
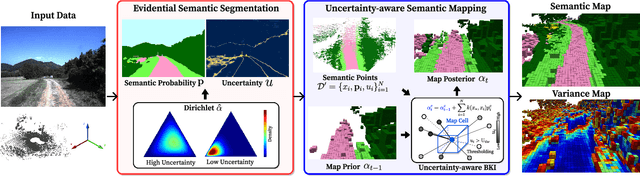
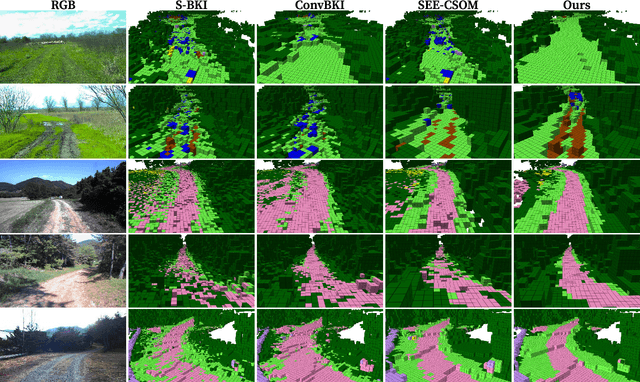

Robotic mapping with Bayesian Kernel Inference (BKI) has shown promise in creating semantic maps by effectively leveraging local spatial information. However, existing semantic mapping methods face challenges in constructing reliable maps in unstructured outdoor scenarios due to unreliable semantic predictions. To address this issue, we propose an evidential semantic mapping, which can enhance reliability in perceptually challenging off-road environments. We integrate Evidential Deep Learning into the semantic segmentation network to obtain the uncertainty estimate of semantic prediction. Subsequently, this semantic uncertainty is incorporated into an uncertainty-aware BKI, tailored to prioritize more confident semantic predictions when accumulating semantic information. By adaptively handling semantic uncertainties, the proposed framework constructs robust representations of the surroundings even in previously unseen environments. Comprehensive experiments across various off-road datasets demonstrate that our framework enhances accuracy and robustness, consistently outperforming existing methods in scenes with high perceptual uncertainties.
DA-RAW: Domain Adaptive Object Detection for Real-World Adverse Weather Conditions
Sep 15, 2023
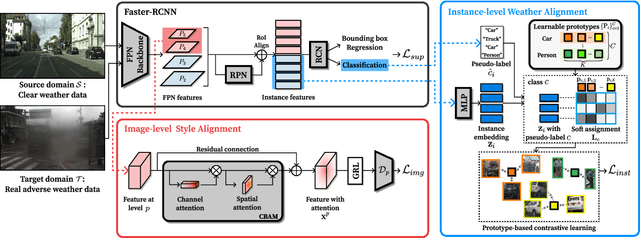

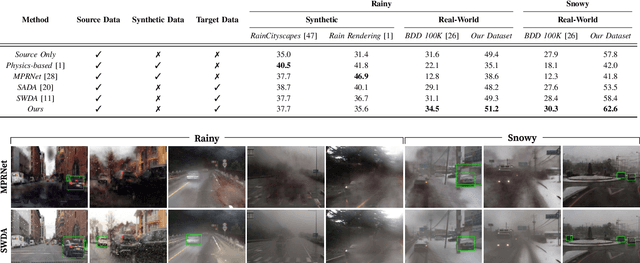
Despite the success of deep learning-based object detection methods in recent years, it is still challenging to make the object detector reliable in adverse weather conditions such as rain and snow. For the robust performance of object detectors, unsupervised domain adaptation has been utilized to adapt the detection network trained on clear weather images to adverse weather images. While previous methods do not explicitly address weather corruption during adaptation, the domain gap between clear and adverse weather can be decomposed into two factors with distinct characteristics: a style gap and a weather gap. In this paper, we present an unsupervised domain adaptation framework for object detection that can more effectively adapt to real-world environments with adverse weather conditions by addressing these two gaps separately. Our method resolves the style gap by concentrating on style-related information of high-level features using an attention module. Using self-supervised contrastive learning, our framework then reduces the weather gap and acquires instance features that are robust to weather corruption. Extensive experiments demonstrate that our method outperforms other methods for object detection in adverse weather conditions.
ScaTE: A Scalable Framework for Self-Supervised Traversability Estimation in Unstructured Environments
Sep 14, 2022

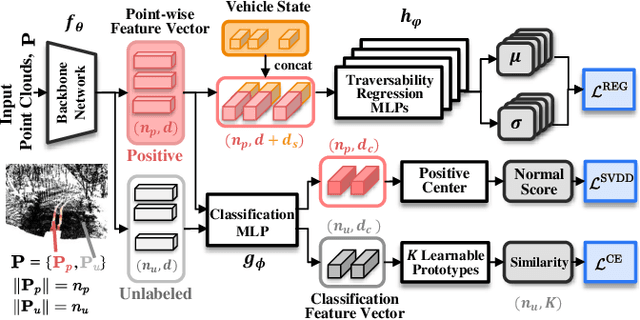

For the safe and successful navigation of autonomous vehicles in unstructured environments, the traversability of terrain should vary based on the driving capabilities of the vehicles. Actual driving experience can be utilized in a self-supervised fashion to learn vehicle-specific traversability. However, existing methods for learning self-supervised traversability are not highly scalable for learning the traversability of various vehicles. In this work, we introduce a scalable framework for learning self-supervised traversability, which can learn the traversability directly from vehicle-terrain interaction without any human supervision. We train a neural network that predicts the proprioceptive experience that a vehicle would undergo from 3D point clouds. Using a novel PU learning method, the network simultaneously identifies non-traversable regions where estimations can be overconfident. With driving data of various vehicles gathered from simulation and the real world, we show that our framework is capable of learning the self-supervised traversability of various vehicles. By integrating our framework with a model predictive controller, we demonstrate that estimated traversability results in effective navigation that enables distinct maneuvers based on the driving characteristics of the vehicles. In addition, experimental results validate the ability of our method to identify and avoid non-traversable regions.
SLiDE: Self-supervised LiDAR De-snowing through Reconstruction Difficulty
Aug 08, 2022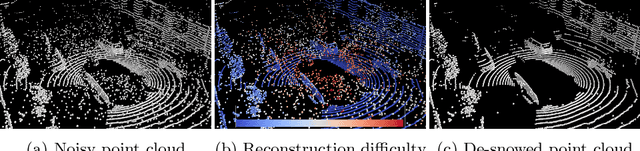
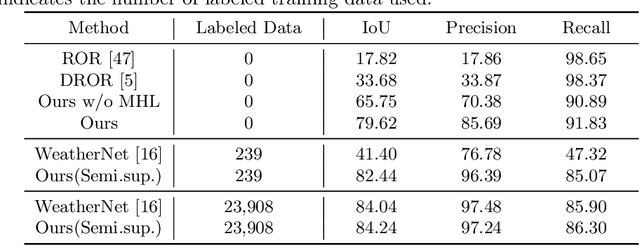
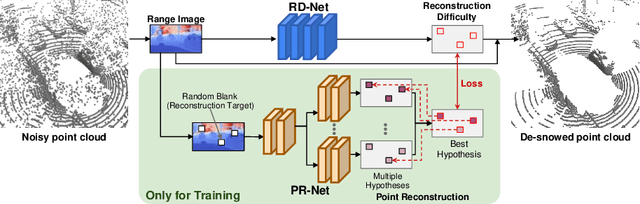
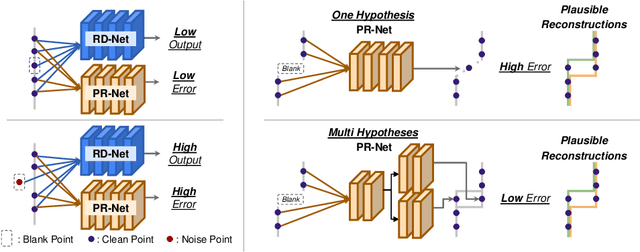
LiDAR is widely used to capture accurate 3D outdoor scene structures. However, LiDAR produces many undesirable noise points in snowy weather, which hamper analyzing meaningful 3D scene structures. Semantic segmentation with snow labels would be a straightforward solution for removing them, but it requires laborious point-wise annotation. To address this problem, we propose a novel self-supervised learning framework for snow points removal in LiDAR point clouds. Our method exploits the structural characteristic of the noise points: low spatial correlation with their neighbors. Our method consists of two deep neural networks: Point Reconstruction Network (PR-Net) reconstructs each point from its neighbors; Reconstruction Difficulty Network (RD-Net) predicts point-wise difficulty of the reconstruction by PR-Net, which we call reconstruction difficulty. With simple post-processing, our method effectively detects snow points without any label. Our method achieves the state-of-the-art performance among label-free approaches and is comparable to the fully-supervised method. Moreover, we demonstrate that our method can be exploited as a pretext task to improve label-efficiency of supervised training of de-snowing.