 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Latent Safety Filters for Avoiding Out-of-Distribution Failures
May 01, 2025Recent advances in generative world models have enabled classical safe control methods, such as Hamilton-Jacobi (HJ) reachability, to generalize to complex robotic systems operating directly from high-dimensional sensor observations. However, obtaining comprehensive coverage of all safety-critical scenarios during world model training is extremely challenging. As a result, latent safety filters built on top of these models may miss novel hazards and even fail to prevent known ones, overconfidently misclassifying risky out-of-distribution (OOD) situations as safe. To address this, we introduce an uncertainty-aware latent safety filter that proactively steers robots away from both known and unseen failures. Our key idea is to use the world model's epistemic uncertainty as a proxy for identifying unseen potential hazards. We propose a principled method to detect OOD world model predictions by calibrating an uncertainty threshold via conformal prediction. By performing reachability analysis in an augmented state space-spanning both the latent representation and the epistemic uncertainty-we synthesize a latent safety filter that can reliably safeguard arbitrary policies from both known and unseen safety hazards. In simulation and hardware experiments on vision-based control tasks with a Franka manipulator, we show that our uncertainty-aware safety filter preemptively detects potential unsafe scenarios and reliably proposes safe, in-distribution actions. Video results can be found on the project website at https://cmu-intentlab.github.io/UNISafe
Structured Extraction of Process Structure Properties Relationships in Materials Science
Apr 04, 2025
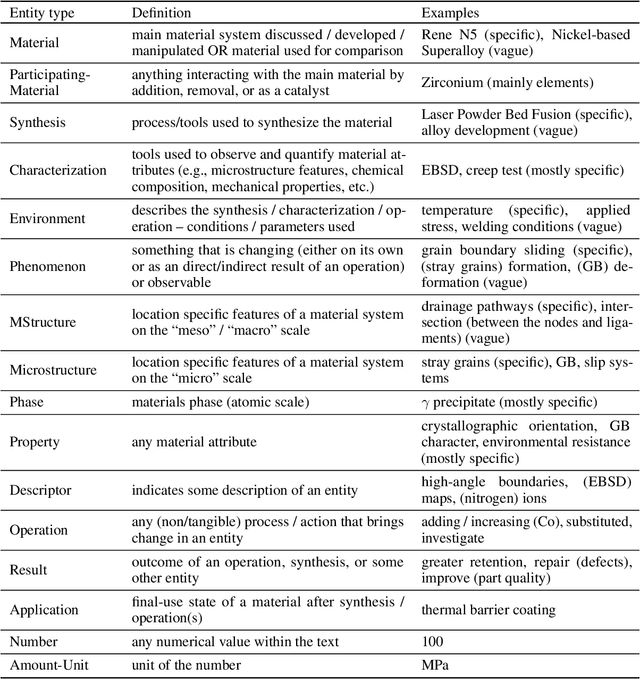
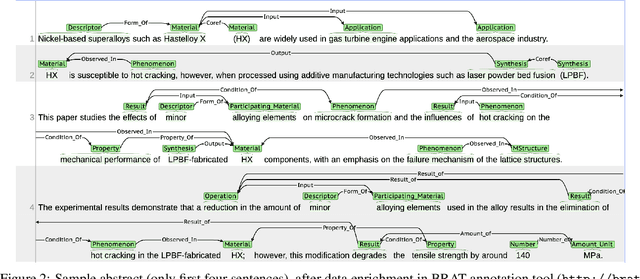
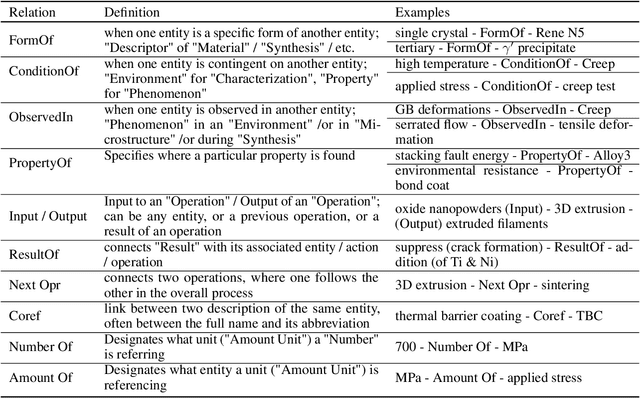
With the advent of large language models (LLMs), the vast unstructured text within millions of academic papers is increasingly accessible for materials discovery, although significant challenges remain. While LLMs offer promising few- and zero-shot learning capabilities, particularly valuable in the materials domain where expert annotations are scarce, general-purpose LLMs often fail to address key materials-specific queries without further adaptation. To bridge this gap, fine-tuning LLMs on human-labeled data is essential for effective structured knowledge extraction. In this study, we introduce a novel annotation schema designed to extract generic process-structure-properties relationships from scientific literature. We demonstrate the utility of this approach using a dataset of 128 abstracts, with annotations drawn from two distinct domains: high-temperature materials (Domain I) and uncertainty quantification in simulating materials microstructure (Domain II). Initially, we developed a conditional random field (CRF) model based on MatBERT, a domain-specific BERT variant, and evaluated its performance on Domain I. Subsequently, we compared this model with a fine-tuned LLM (GPT-4o from OpenAI) under identical conditions. Our results indicate that fine-tuning LLMs can significantly improve entity extraction performance over the BERT-CRF baseline on Domain I. However, when additional examples from Domain II were incorporated, the performance of the BERT-CRF model became comparable to that of the GPT-4o model. These findings underscore the potential of our schema for structured knowledge extraction and highlight the complementary strengths of both modeling approaches.
Collage: Decomposable Rapid Prototyping for Information Extraction on Scientific PDFs
Oct 30, 2024



Recent years in NLP have seen the continued development of domain-specific information extraction tools for scientific documents, alongside the release of increasingly multimodal pretrained transformer models. While the opportunity for scientists outside of NLP to evaluate and apply such systems to their own domains has never been clearer, these models are difficult to compare: they accept different input formats, are often black-box and give little insight into processing failures, and rarely handle PDF documents, the most common format of scientific publication. In this work, we present Collage, a tool designed for rapid prototyping, visualization, and evaluation of different information extraction models on scientific PDFs. Collage allows the use and evaluation of any HuggingFace token classifier, several LLMs, and multiple other task-specific models out of the box, and provides extensible software interfaces to accelerate experimentation with new models. Further, we enable both developers and users of NLP-based tools to inspect, debug, and better understand modeling pipelines by providing granular views of intermediate states of processing. We demonstrate our system in the context of information extraction to assist with literature review in materials science.
Open-World Object Detection with Instance Representation Learning
Sep 24, 2024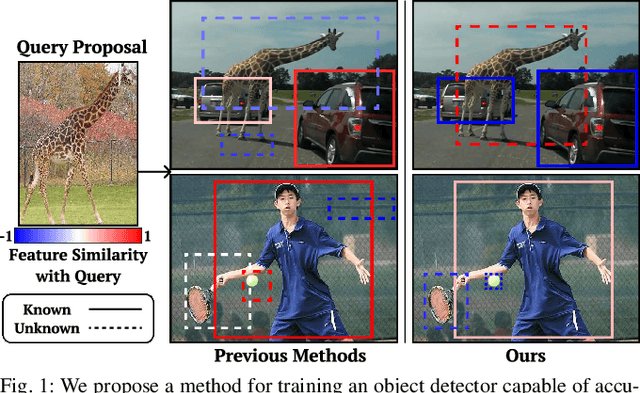
While humans naturally identify novel objects and understand their relationships, deep learning-based object detectors struggle to detect and relate objects that are not observed during training. To overcome this issue, Open World Object Detection(OWOD) has been introduced to enable models to detect unknown objects in open-world scenarios. However, OWOD methods fail to capture the fine-grained relationships between detected objects, which are crucial for comprehensive scene understanding and applications such as class discovery and tracking. In this paper, we propose a method to train an object detector that can both detect novel objects and extract semantically rich features in open-world conditions by leveraging the knowledge of Vision Foundation Models(VFM). We first utilize the semantic masks from the Segment Anything Model to supervise the box regression of unknown objects, ensuring accurate localization. By transferring the instance-wise similarities obtained from the VFM features to the detector's instance embeddings, our method then learns a semantically rich feature space of these embeddings. Extensive experiments show that our method learns a robust and generalizable feature space, outperforming other OWOD-based feature extraction methods. Additionally, we demonstrate that the enhanced feature from our model increases the detector's applicability to tasks such as open-world tracking.
Uncertainty-aware Semantic Mapping in Off-road Environments with Dempster-Shafer Theory of Evidence
May 10, 2024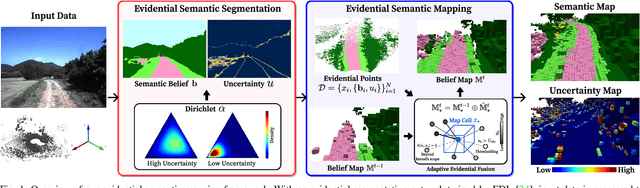
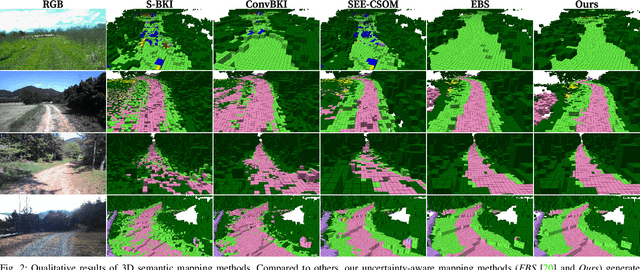
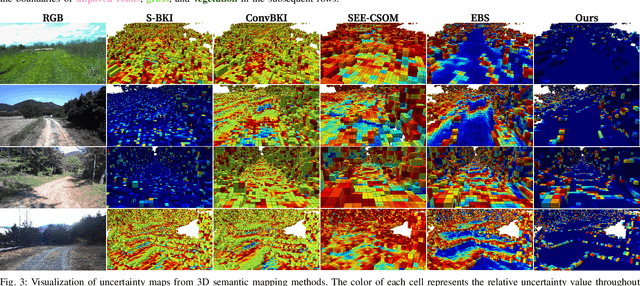
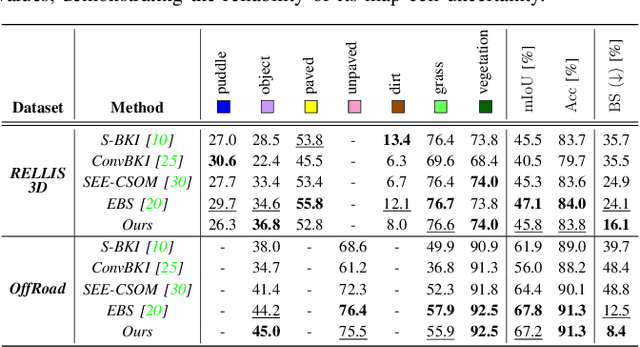
Semantic mapping with Bayesian Kernel Inference (BKI) has shown promise in providing a richer understanding of environments by effectively leveraging local spatial information. However, existing methods face challenges in constructing accurate semantic maps or reliable uncertainty maps in perceptually challenging environments due to unreliable semantic predictions. To address this issue, we propose an evidential semantic mapping framework, which integrates the evidential reasoning of Dempster-Shafer Theory of Evidence (DST) into the entire mapping pipeline by adopting Evidential Deep Learning (EDL) and Dempster's rule of combination. Additionally, the extended belief is devised to incorporate local spatial information based on their uncertainty during the mapping process. Comprehensive experiments across various off-road datasets demonstrate that our framework enhances the reliability of uncertainty maps, consistently outperforming existing methods in scenes with high perceptual uncertainties while showing semantic accuracy comparable to the best-performing semantic mapping techniques.
Evidential Semantic Mapping in Off-road Environments with Uncertainty-aware Bayesian Kernel Inference
Mar 21, 2024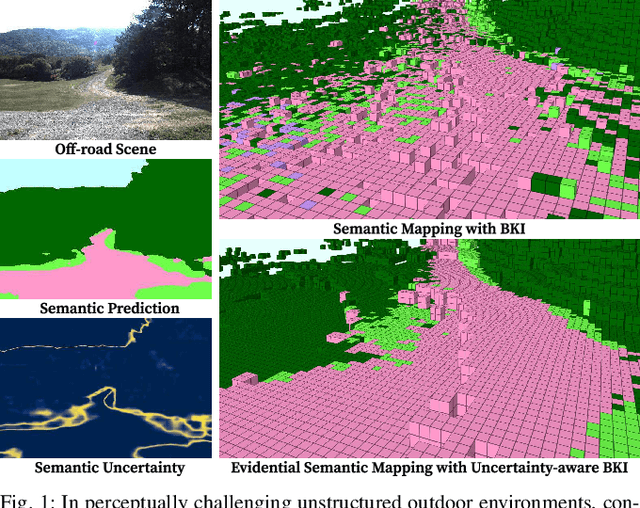
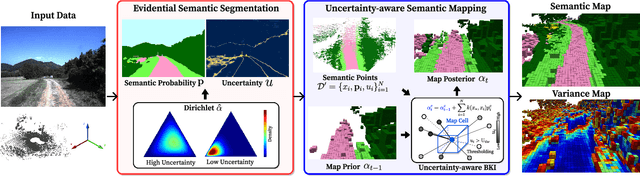
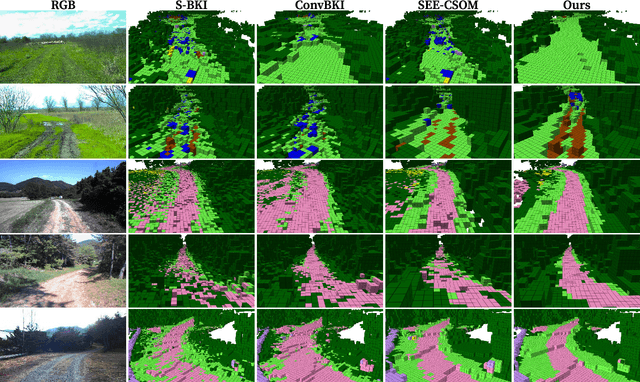

Robotic mapping with Bayesian Kernel Inference (BKI) has shown promise in creating semantic maps by effectively leveraging local spatial information. However, existing semantic mapping methods face challenges in constructing reliable maps in unstructured outdoor scenarios due to unreliable semantic predictions. To address this issue, we propose an evidential semantic mapping, which can enhance reliability in perceptually challenging off-road environments. We integrate Evidential Deep Learning into the semantic segmentation network to obtain the uncertainty estimate of semantic prediction. Subsequently, this semantic uncertainty is incorporated into an uncertainty-aware BKI, tailored to prioritize more confident semantic predictions when accumulating semantic information. By adaptively handling semantic uncertainties, the proposed framework constructs robust representations of the surroundings even in previously unseen environments. Comprehensive experiments across various off-road datasets demonstrate that our framework enhances accuracy and robustness, consistently outperforming existing methods in scenes with high perceptual uncertainties.
UFO: Uncertainty-aware LiDAR-image Fusion for Off-road Semantic Terrain Map Estimation
Mar 05, 2024

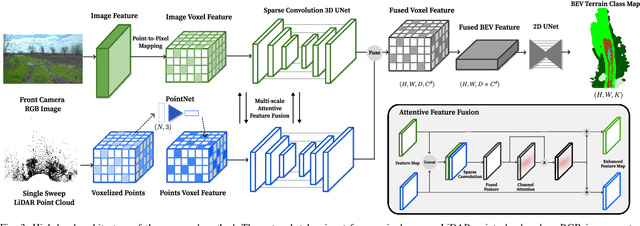

Autonomous off-road navigation requires an accurate semantic understanding of the environment, often converted into a bird's-eye view (BEV) representation for various downstream tasks. While learning-based methods have shown success in generating local semantic terrain maps directly from sensor data, their efficacy in off-road environments is hindered by challenges in accurately representing uncertain terrain features. This paper presents a learning-based fusion method for generating dense terrain classification maps in BEV. By performing LiDAR-image fusion at multiple scales, our approach enhances the accuracy of semantic maps generated from an RGB image and a single-sweep LiDAR scan. Utilizing uncertainty-aware pseudo-labels further enhances the network's ability to learn reliably in off-road environments without requiring precise 3D annotations. By conducting thorough experiments using off-road driving datasets, we demonstrate that our method can improve accuracy in off-road terrains, validating its efficacy in facilitating reliable and safe autonomous navigation in challenging off-road settings.
In Search of a Data Transformation That Accelerates Neural Field Training
Nov 28, 2023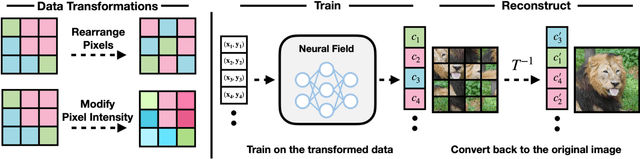
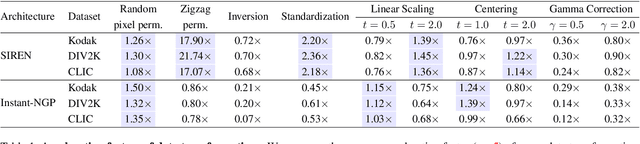
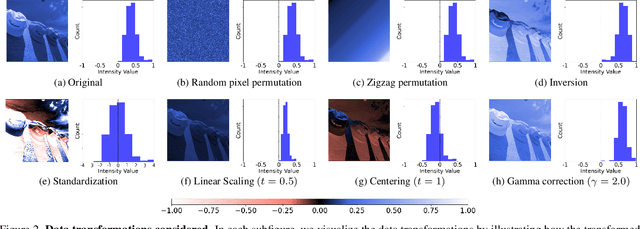
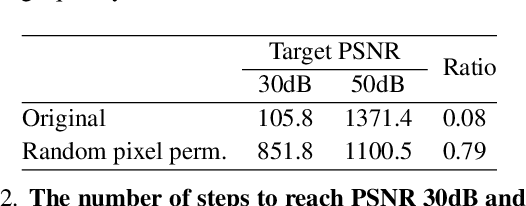
Neural field is an emerging paradigm in data representation that trains a neural network to approximate the given signal. A key obstacle that prevents its widespread adoption is the encoding speed-generating neural fields requires an overfitting of a neural network, which can take a significant number of SGD steps to reach the desired fidelity level. In this paper, we delve into the impacts of data transformations on the speed of neural field training, specifically focusing on how permuting pixel locations affect the convergence speed of SGD. Counterintuitively, we find that randomly permuting the pixel locations can considerably accelerate the training. To explain this phenomenon, we examine the neural field training through the lens of PSNR curves, loss landscapes, and error patterns. Our analyses suggest that the random pixel permutations remove the easy-to-fit patterns, which facilitate easy optimization in the early stage but hinder capturing fine details of the signal.
DA-RAW: Domain Adaptive Object Detection for Real-World Adverse Weather Conditions
Sep 15, 2023
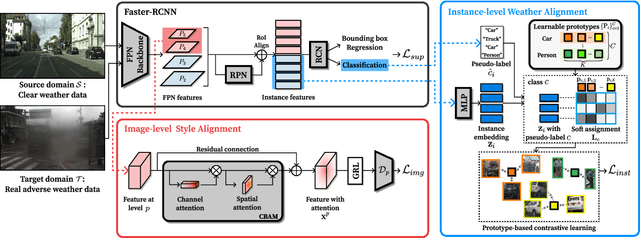

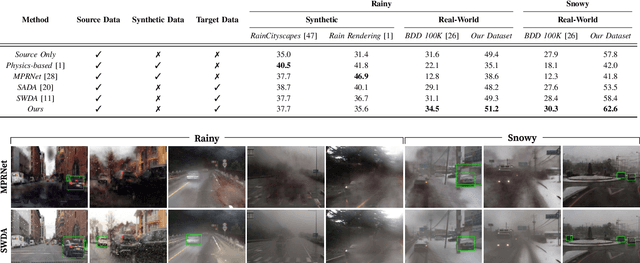
Despite the success of deep learning-based object detection methods in recent years, it is still challenging to make the object detector reliable in adverse weather conditions such as rain and snow. For the robust performance of object detectors, unsupervised domain adaptation has been utilized to adapt the detection network trained on clear weather images to adverse weather images. While previous methods do not explicitly address weather corruption during adaptation, the domain gap between clear and adverse weather can be decomposed into two factors with distinct characteristics: a style gap and a weather gap. In this paper, we present an unsupervised domain adaptation framework for object detection that can more effectively adapt to real-world environments with adverse weather conditions by addressing these two gaps separately. Our method resolves the style gap by concentrating on style-related information of high-level features using an attention module. Using self-supervised contrastive learning, our framework then reduces the weather gap and acquires instance features that are robust to weather corruption. Extensive experiments demonstrate that our method outperforms other methods for object detection in adverse weather conditions.
METAVerse: Meta-Learning Traversability Cost Map for Off-Road Navigation
Jul 26, 2023



Autonomous navigation in off-road conditions requires an accurate estimation of terrain traversability. However, traversability estimation in unstructured environments is subject to high uncertainty due to the variability of numerous factors that influence vehicle-terrain interaction. Consequently, it is challenging to obtain a generalizable model that can accurately predict traversability in a variety of environments. This paper presents METAVerse, a meta-learning framework for learning a global model that accurately and reliably predicts terrain traversability across diverse environments. We train the traversability prediction network to generate a dense and continuous-valued cost map from a sparse LiDAR point cloud, leveraging vehicle-terrain interaction feedback in a self-supervised manner. Meta-learning is utilized to train a global model with driving data collected from multiple environments, effectively minimizing estimation uncertainty. During deployment, online adaptation is performed to rapidly adapt the network to the local environment by exploiting recent interaction experiences. To conduct a comprehensive evaluation, we collect driving data from various terrains and demonstrate that our method can obtain a global model that minimizes uncertainty. Moreover, by integrating our model with a model predictive controller, we demonstrate that the reduced uncertainty results in safe and stable navigation in unstructured and unknown terrains.