 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCoEvo: A Knowledge Graph Augmented Framework for Evolutionary Code Generation
Mar 08, 2026Code evolution is inevitable in modern software development. Changes to third-party APIs frequently break existing code and complicate maintenance, posing practical challenges for developers. While large language models (LLMs) have shown promise in code generation, they struggle to reason without a structured representation of these evolving relationships, often leading them to produce outdated APIs or invalid outputs. In this work, we propose a knowledge graph-augmented framework that decomposes the migration task into two synergistic stages: evolution path retrieval and path-informed code generation. Our approach constructs static and dynamic API graphs to model intra-version structures and cross-version transitions, enabling structured reasoning over API evolution. Both modules are trained with synthetic supervision automatically derived from real-world API diffs, ensuring scalability and minimal human effort. Extensive experiments across single-package and multi-package benchmarks demonstrate that our framework significantly improves migration accuracy, controllability, and execution success over standard LLM baselines. The source code and datasets are available at: https://github.com/kangjz1203/KCoEvo.
DA-SPS: A Dual-stage Network based on Singular Spectrum Analysis, Patching-strategy and Spearman-correlation for Multivariate Time-series Prediction
Jan 29, 2026Multivariate time-series forecasting, as a typical problem in the field of time series prediction, has a wide range of applications in weather forecasting, traffic flow prediction, and other scenarios. However, existing works do not effectively consider the impact of extraneous variables on the prediction of the target variable. On the other hand, they fail to fully extract complex sequence information based on various time patterns of the sequences. To address these drawbacks, we propose a DA-SPS model, which adopts different modules for feature extraction based on the information characteristics of different variables. DA-SPS mainly consists of two stages: the target variable processing stage (TVPS) and the extraneous variables processing stage (EVPS). In TVPS, the model first uses Singular Spectrum Analysis (SSA) to process the target variable sequence and then uses Long Short-Term Memory (LSTM) and P-Conv-LSTM which deploys a patching strategy to extract features from trend and seasonality components, respectively. In EVPS, the model filters extraneous variables that have a strong correlation with the target variate by using Spearman correlation analysis and further analyses them using the L-Attention module which consists of LSTM and attention mechanism. Finally, the results obtained by TVPS and EVPS are combined through weighted summation and linear mapping to produce the final prediction. The results on four public datasets demonstrate that the DA-SPS model outperforms existing state-of-the-art methods. Additionally, its performance in real-world scenarios is further validated using a private dataset collected by ourselves, which contains the test items' information on laptop motherboards.
IBN: An Interpretable Bidirectional-Modeling Network for Multivariate Time Series Forecasting with Variable Missing
Sep 09, 2025Multivariate time series forecasting (MTSF) often faces challenges from missing variables, which hinder conventional spatial-temporal graph neural networks in modeling inter-variable correlations. While GinAR addresses variable missing using attention-based imputation and adaptive graph learning for the first time, it lacks interpretability and fails to capture more latent temporal patterns due to its simple recursive units (RUs). To overcome these limitations, we propose the Interpretable Bidirectional-modeling Network (IBN), integrating Uncertainty-Aware Interpolation (UAI) and Gaussian kernel-based Graph Convolution (GGCN). IBN estimates the uncertainty of reconstructed values using MC Dropout and applies an uncertainty-weighted strategy to mitigate high-risk reconstructions. GGCN explicitly models spatial correlations among variables, while a bidirectional RU enhances temporal dependency modeling. Extensive experiments show that IBN achieves state-of-the-art forecasting performance under various missing-rate scenarios, providing a more reliable and interpretable framework for MTSF with missing variables. Code is available at: https://github.com/zhangth1211/NICLab-IBN.
In-Context Learning of Linear Dynamical Systems with Transformers: Error Bounds and Depth-Separation
Feb 12, 2025
This paper investigates approximation-theoretic aspects of the in-context learning capability of the transformers in representing a family of noisy linear dynamical systems. Our first theoretical result establishes an upper bound on the approximation error of multi-layer transformers with respect to an $L^2$-testing loss uniformly defined across tasks. This result demonstrates that transformers with logarithmic depth can achieve error bounds comparable with those of the least-squares estimator. In contrast, our second result establishes a non-diminishing lower bound on the approximation error for a class of single-layer linear transformers, which suggests a depth-separation phenomenon for transformers in the in-context learning of dynamical systems. Moreover, this second result uncovers a critical distinction in the approximation power of single-layer linear transformers when learning from IID versus non-IID data.
STTS-EAD: Improving Spatio-Temporal Learning Based Time Series Prediction via
Jan 14, 2025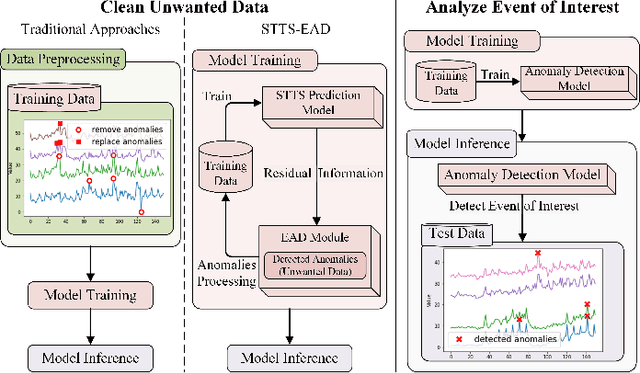
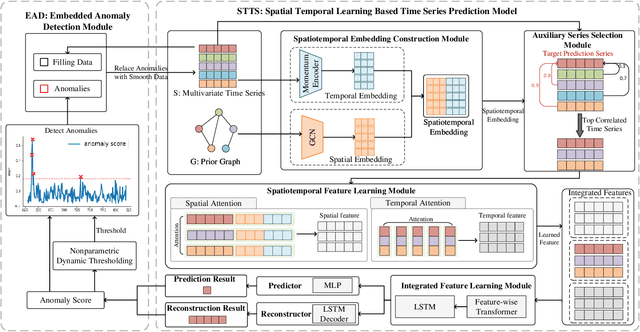
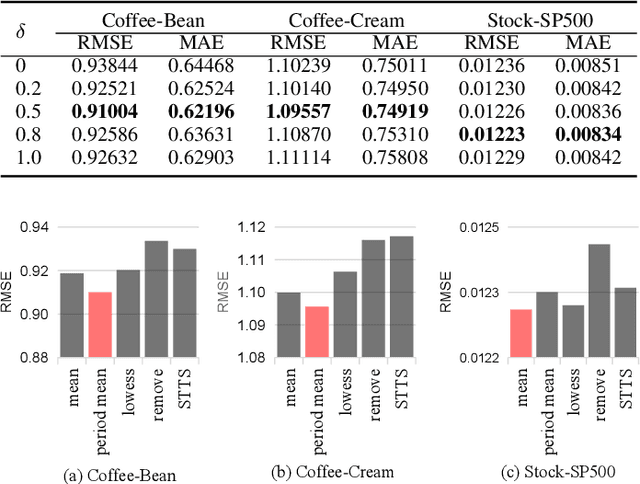
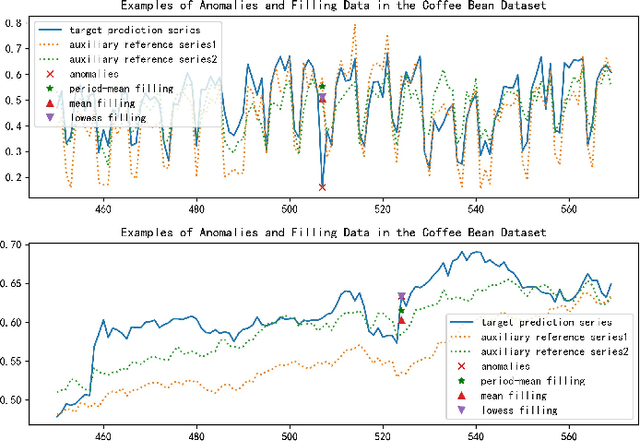
Handling anomalies is a critical preprocessing step in multivariate time series prediction. However, existing approaches that separate anomaly preprocessing from model training for multivariate time series prediction encounter significant limitations. Specifically, these methods fail to utilize auxiliary information crucial for identifying latent anomalies associated with spatiotemporal factors during the preprocessing stage. Instead, they rely solely on data distribution for anomaly detection, which can result in the incorrect processing of numerous samples that could otherwise contribute positively to model training. To address this, we propose STTS-EAD, an end-to-end method that seamlessly integrates anomaly detection into the training process of multivariate time series forecasting and aims to improve Spatio-Temporal learning based Time Series prediction via Embedded Anomaly Detection. Our proposed STTS-EAD leverages spatio-temporal information for forecasting and anomaly detection, with the two parts alternately executed and optimized for each other. To the best of our knowledge, STTS-EAD is the first to integrate anomaly detection and forecasting tasks in the training phase for improving the accuracy of multivariate time series forecasting. Extensive experiments on a public stock dataset and two real-world sales datasets from a renowned coffee chain enterprise show that our proposed method can effectively process detected anomalies in the training stage to improve forecasting performance in the inference stage and significantly outperform baselines.
Collage: Decomposable Rapid Prototyping for Information Extraction on Scientific PDFs
Oct 30, 2024



Recent years in NLP have seen the continued development of domain-specific information extraction tools for scientific documents, alongside the release of increasingly multimodal pretrained transformer models. While the opportunity for scientists outside of NLP to evaluate and apply such systems to their own domains has never been clearer, these models are difficult to compare: they accept different input formats, are often black-box and give little insight into processing failures, and rarely handle PDF documents, the most common format of scientific publication. In this work, we present Collage, a tool designed for rapid prototyping, visualization, and evaluation of different information extraction models on scientific PDFs. Collage allows the use and evaluation of any HuggingFace token classifier, several LLMs, and multiple other task-specific models out of the box, and provides extensible software interfaces to accelerate experimentation with new models. Further, we enable both developers and users of NLP-based tools to inspect, debug, and better understand modeling pipelines by providing granular views of intermediate states of processing. We demonstrate our system in the context of information extraction to assist with literature review in materials science.
PViT: Prior-augmented Vision Transformer for Out-of-distribution Detection
Oct 27, 2024


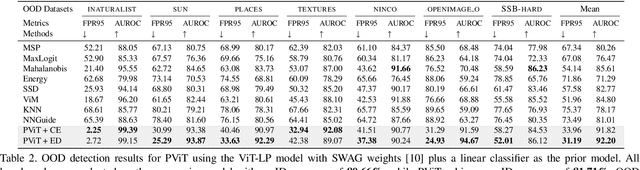
Vision Transformers (ViTs) have achieved remarkable success over various vision tasks, yet their robustness against data distribution shifts and inherent inductive biases remain underexplored. To enhance the robustness of ViT models for image Out-of-Distribution (OOD) detection, we introduce a novel and generic framework named Prior-augmented Vision Transformer (PViT). PViT identifies OOD samples by quantifying the divergence between the predicted class logits and the prior logits obtained from pre-trained models. Unlike existing state-of-the-art OOD detection methods, PViT shapes the decision boundary between ID and OOD by utilizing the proposed prior guide confidence, without requiring additional data modeling, generation methods, or structural modifications. Extensive experiments on the large-scale ImageNet benchmark demonstrate that PViT significantly outperforms existing state-of-the-art OOD detection methods. Additionally, through comprehensive analyses, ablation studies, and discussions, we show how PViT can strategically address specific challenges in managing large vision models, paving the way for new advancements in OOD detection.
MorphoSeg: An Uncertainty-Aware Deep Learning Method for Biomedical Segmentation of Complex Cellular Morphologies
Sep 25, 2024



Deep learning has revolutionized medical and biological imaging, particularly in segmentation tasks. However, segmenting biological cells remains challenging due to the high variability and complexity of cell shapes. Addressing this challenge requires high-quality datasets that accurately represent the diverse morphologies found in biological cells. Existing cell segmentation datasets are often limited by their focus on regular and uniform shapes. In this paper, we introduce a novel benchmark dataset of Ntera-2 (NT2) cells, a pluripotent carcinoma cell line, exhibiting diverse morphologies across multiple stages of differentiation, capturing the intricate and heterogeneous cellular structures that complicate segmentation tasks. To address these challenges, we propose an uncertainty-aware deep learning framework for complex cellular morphology segmentation (MorphoSeg) by incorporating sampling of virtual outliers from low-likelihood regions during training. Our comprehensive experimental evaluations against state-of-the-art baselines demonstrate that MorphoSeg significantly enhances segmentation accuracy, achieving up to a 7.74% increase in the Dice Similarity Coefficient (DSC) and a 28.36% reduction in the Hausdorff Distance. These findings highlight the effectiveness of our dataset and methodology in advancing cell segmentation capabilities, especially for complex and variable cell morphologies. The dataset and source code is publicly available at https://github.com/RanchoGoose/MorphoSeg.
Gaussian Representation for Deformable Image Registration
Jun 05, 2024



Deformable image registration (DIR) is a fundamental task in radiotherapy, with existing methods often struggling to balance computational efficiency, registration accuracy, and speed effectively. We introduce a novel DIR approach employing parametric 3D Gaussian control points achieving a better tradeoff. It provides an explicit and flexible representation for spatial deformation fields between 3D volumetric medical images, producing a displacement vector field (DVF) across all volumetric positions. The movement of individual voxels is derived using linear blend skinning (LBS) through localized interpolation of transformations associated with neighboring Gaussians. This interpolation strategy not only simplifies the determination of voxel motions but also acts as an effective regularization technique. Our approach incorporates a unified optimization process through backpropagation, enabling iterative learning of both the parameters of the 3D Gaussians and their transformations. Additionally, the density of Gaussians is adjusted adaptively during the learning phase to accommodate varying degrees of motion complexity. We validated our approach on the 4D-CT lung DIR-Lab and cardiac ACDC datasets, achieving an average target registration error (TRE) of 1.06 mm within a much-improved processing time of 2.43 seconds for the DIR-Lab dataset over existing methods, demonstrating significant advancements in both accuracy and efficiency.
On the Sequence Evaluation based on Stochastic Processes
May 28, 2024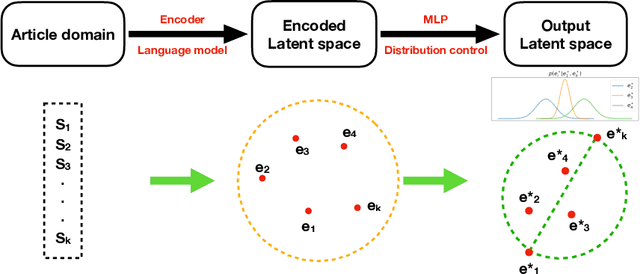
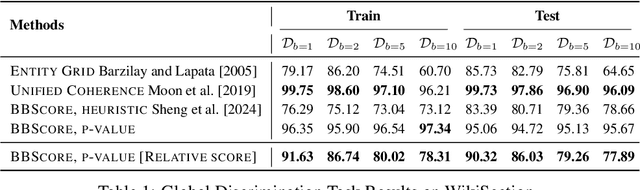

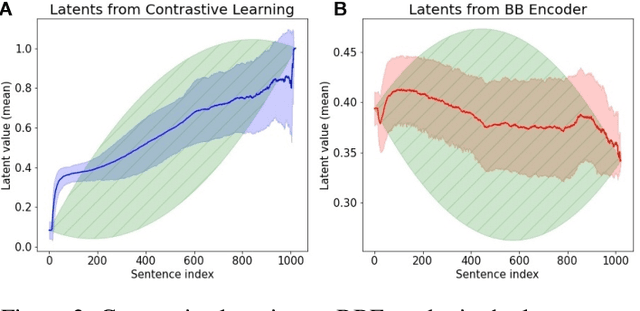
Modeling and analyzing long sequences of text is an essential task for Natural Language Processing. Success in capturing long text dynamics using neural language models will facilitate many downstream tasks such as coherence evaluation, text generation, machine translation and so on. This paper presents a novel approach to model sequences through a stochastic process. We introduce a likelihood-based training objective for the text encoder and design a more thorough measurement (score) for long text evaluation compared to the previous approach. The proposed training objective effectively preserves the sequence coherence, while the new score comprehensively captures both temporal and spatial dependencies. Theoretical properties of our new score show its advantages in sequence evaluation. Experimental results show superior performance in various sequence evaluation tasks, including global and local discrimination within and between documents of different lengths. We also demonstrate the encoder achieves competitive results on discriminating human and AI written text.