 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sequence Evaluation based on Stochastic Processes
Paper and Code
May 28, 2024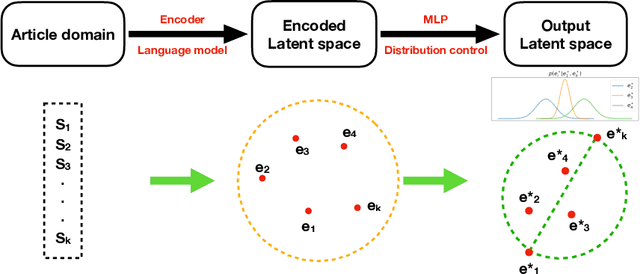
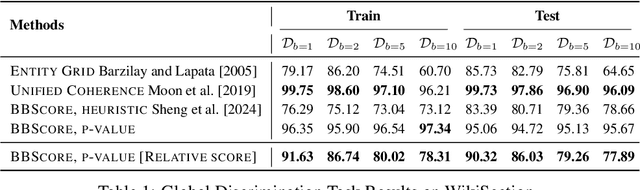

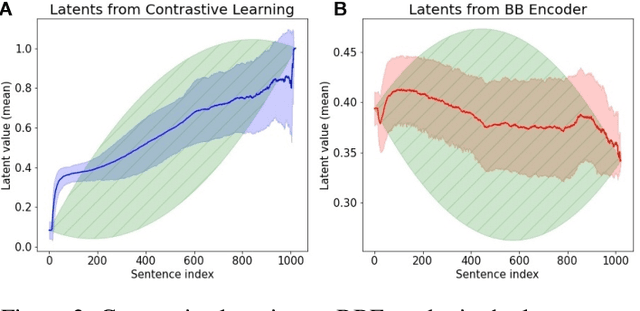
Modeling and analyzing long sequences of text is an essential task for Natural Language Processing. Success in capturing long text dynamics using neural language models will facilitate many downstream tasks such as coherence evaluation, text generation, machine translation and so on. This paper presents a novel approach to model sequences through a stochastic process. We introduce a likelihood-based training objective for the text encoder and design a more thorough measurement (score) for long text evaluation compared to the previous approach. The proposed training objective effectively preserves the sequence coherence, while the new score comprehensively captures both temporal and spatial dependencies. Theoretical properties of our new score show its advantages in sequence evaluation. Experimental results show superior performance in various sequence evaluation tasks, including global and local discrimination within and between documents of different lengths. We also demonstrate the encoder achieves competitive results on discriminating human and AI written text.