 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Prompts Interact: Assessing Prompt Arithmetic for Deconfounding under Distribution Shift
May 04, 2026In classification tasks, models may rely on confounding variables to achieve strong in-distribution performance, capturing spurious features that fail under distribution shift. This shortcut behavior leads to substantial degradation in out-of-distribution settings. Task arithmetic offers a potential solution by removing unwanted signals via subtraction of secondary model updates, but it typically requires full fine-tuning, which is computationally expensive. Prompt tuning provides a parameter-efficient alternative by adapting models through a small set of trainable virtual tokens. Task arithmetic on the resulting prompts presents an appealing alternative to operations on entire models, but the extent to which this approach can limit reliance on spurious features remains to be established. In this work, we study whether composing soft prompts through task arithmetic improves robustness to confounding shifts. We propose Hybrid Prompt Arithmetic (HyPA), which combines task prompts with linearized confounder prompts to counteract spurious correlations. Across multiple benchmarks, HyPA consistently improves the robustness-performance trade-off relative to prompt-arithmetic baselines under distribution shift. We further analyze how HyPA affects hidden representations and find evidence consistent with it mitigating confounding either by reducing the influence of confounder signals on predictions or by suppressing them in the representation. These results establish HyPA as a parameter-efficient and promising approach for improving robustness under confounding shifts in the evaluated setting.
Mitigating Confounding in Speech-Based Dementia Detection through Weight Masking
Jun 05, 2025Deep transformer models have been used to detect linguistic anomalies in patient transcripts for early Alzheimer's disease (AD) screening. While pre-trained neural language models (LMs) fine-tuned on AD transcripts perform well, little research has explored the effects of the gender of the speakers represented by these transcripts. This work addresses gender confounding in dementia detection and proposes two methods: the $\textit{Extended Confounding Filter}$ and the $\textit{Dual Filter}$, which isolate and ablate weights associated with gender. We evaluate these methods on dementia datasets with first-person narratives from patients with cognitive impairment and healthy controls. Our results show transformer models tend to overfit to training data distributions. Disrupting gender-related weights results in a deconfounded dementia classifier, with the trade-off of slightly reduced dementia detection performance.
"Is There Anything Else?'': Examining Administrator Influence on Linguistic Features from the Cookie Theft Picture Description Cognitive Test
Mar 25, 2025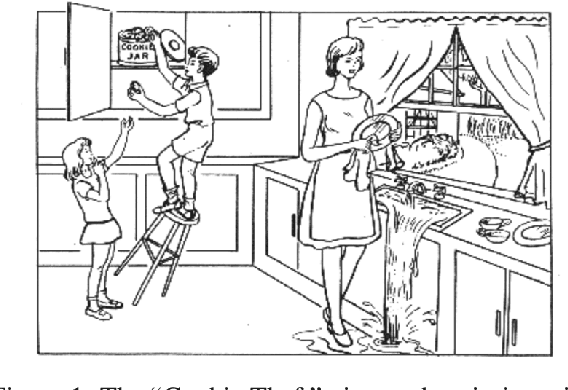
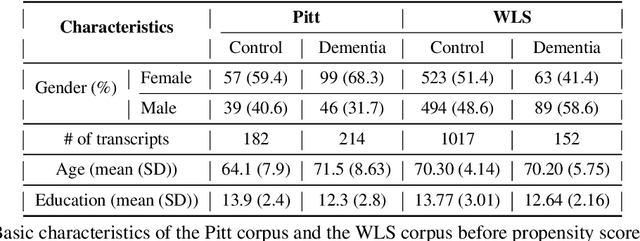
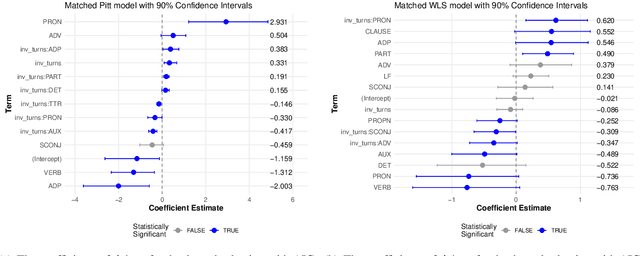
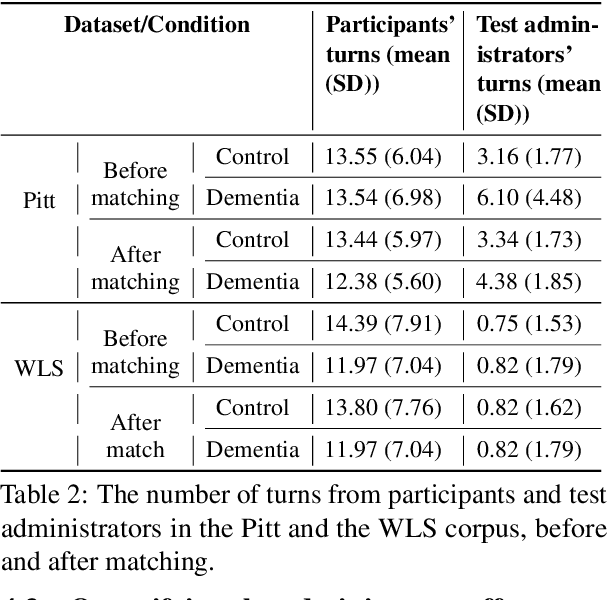
Alzheimer's Disease (AD) dementia is a progressive neurodegenerative disease that negatively impacts patients' cognitive ability. Previous studies have demonstrated that changes in naturalistic language samples can be useful for early screening of AD dementia. However, the nature of language deficits often requires test administrators to use various speech elicitation techniques during spontaneous language assessments to obtain enough propositional utterances from dementia patients. This could lead to the ``observer's effect'' on the downstream analysis that has not been fully investigated. Our study seeks to quantify the influence of test administrators on linguistic features in dementia assessment with two English corpora the ``Cookie Theft'' picture description datasets collected at different locations and test administrators show different levels of administrator involvement. Our results show that the level of test administrator involvement significantly impacts observed linguistic features in patient speech. These results suggest that many of significant linguistic features in the downstream classification task may be partially attributable to differences in the test administration practices rather than solely to participants' cognitive status. The variations in test administrator behavior can lead to systematic biases in linguistic data, potentially confounding research outcomes and clinical assessments. Our study suggests that there is a need for a more standardized test administration protocol in the development of responsible clinical speech analytics frameworks.
Too Big to Fail: Larger Language Models are Disproportionately Resilient to Induction of Dementia-Related Linguistic Anomalies
Jun 05, 2024As artificial neural networks grow in complexity, understanding their inner workings becomes increasingly challenging, which is particularly important in healthcare applications. The intrinsic evaluation metrics of autoregressive neural language models (NLMs), perplexity (PPL), can reflect how "surprised" an NLM model is at novel input. PPL has been widely used to understand the behavior of NLMs. Previous findings show that changes in PPL when masking attention layers in pre-trained transformer-based NLMs reflect linguistic anomalies associated with Alzheimer's disease dementia. Building upon this, we explore a novel bidirectional attention head ablation method that exhibits properties attributed to the concepts of cognitive and brain reserve in human brain studies, which postulate that people with more neurons in the brain and more efficient processing are more resilient to neurodegeneration. Our results show that larger GPT-2 models require a disproportionately larger share of attention heads to be masked/ablated to display degradation of similar magnitude to masking in smaller models. These results suggest that the attention mechanism in transformer models may present an analogue to the notions of cognitive and brain reserve and could potentially be used to model certain aspects of the progression of neurodegenerative disorders and aging.
On the Sequence Evaluation based on Stochastic Processes
May 28, 2024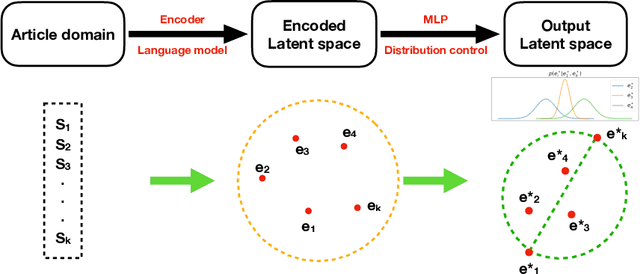
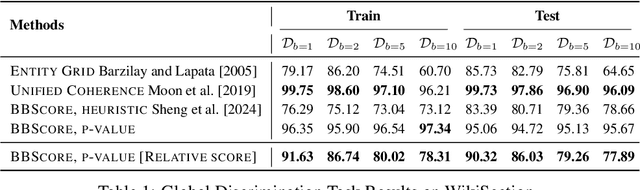

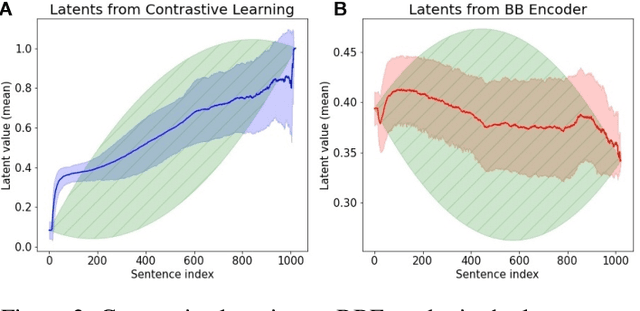
Modeling and analyzing long sequences of text is an essential task for Natural Language Processing. Success in capturing long text dynamics using neural language models will facilitate many downstream tasks such as coherence evaluation, text generation, machine translation and so on. This paper presents a novel approach to model sequences through a stochastic process. We introduce a likelihood-based training objective for the text encoder and design a more thorough measurement (score) for long text evaluation compared to the previous approach. The proposed training objective effectively preserves the sequence coherence, while the new score comprehensively captures both temporal and spatial dependencies. Theoretical properties of our new score show its advantages in sequence evaluation. Experimental results show superior performance in various sequence evaluation tasks, including global and local discrimination within and between documents of different lengths. We also demonstrate the encoder achieves competitive results on discriminating human and AI written text.
BBScore: A Brownian Bridge Based Metric for Assessing Text Coherence
Dec 28, 2023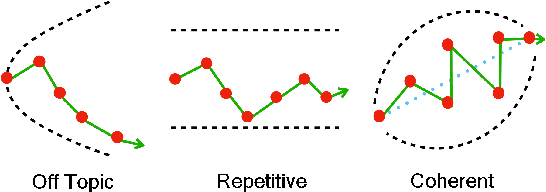
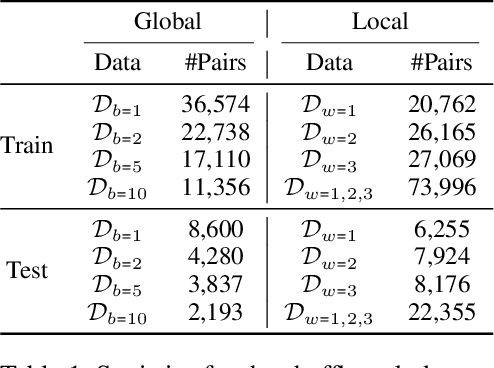

Measuring the coherence of text is a vital aspect of evaluating the quality of written content. Recent advancements in neural coherence modeling have demonstrated their efficacy in capturing entity coreference and discourse relations, thereby enhancing coherence evaluation. However, many existing methods heavily depend on static embeddings or focus narrowly on nearby context, constraining their capacity to measure the overarching coherence of long texts. In this paper, we posit that coherent texts inherently manifest a sequential and cohesive interplay among sentences, effectively conveying the central theme, purpose, or standpoint. To explore this abstract relationship, we introduce the "BBScore," a novel reference-free metric grounded in Brownian bridge theory for assessing text coherence. Our findings showcase that when synergized with a simple additional classification component, this metric attains a performance level comparable to state-of-the-art techniques on standard artificial discrimination tasks. We also establish in downstream tasks that this metric effectively differentiates between human-written documents and text generated by large language models under a specific domain. Furthermore, we illustrate the efficacy of this approach in detecting written styles attributed to diverse large language models, underscoring its potential for generalizability. In summary, we present a novel Brownian bridge coherence metric capable of measuring both local and global text coherence, while circumventing the need for end-to-end model training. This flexibility allows for its application in various downstream tasks.
Enhancing Robustness of Foundation Model Representations under Provenance-related Distribution Shifts
Dec 09, 2023
Foundation models are a current focus of attention in both industry and academia. While they have shown their capabilities in a variety of tasks, in-depth research is required to determine their robustness to distribution shift when used as a basis for supervised machine learning. This is especially important in the context of clinical data, with particular limitations related to data accessibility, lack of pretraining materials, and limited availability of high-quality annotations. In this work, we examine the stability of models based on representations from foundation models under distribution shift. We focus on confounding by provenance, a form of distribution shift that emerges in the context of multi-institutional datasets when there are differences in source-specific language use and class distributions. Using a sampling strategy that synthetically induces varying degrees of distribution shift, we evaluate the extent to which representations from foundation models result in predictions that are inherently robust to confounding by provenance. Additionally, we examine the effectiveness of a straightforward confounding adjustment method inspired by Pearl's conception of backdoor adjustment. Results indicate that while foundation models do show some out-of-the-box robustness to confounding-by-provenance related distribution shifts, this can be considerably improved through adjustment. These findings suggest a need for deliberate adjustment of predictive models using representations from foundation models in the context of source-specific distributional differences.
Backdoor Adjustment of Confounding by Provenance for Robust Text Classification of Multi-institutional Clinical Notes
Oct 03, 2023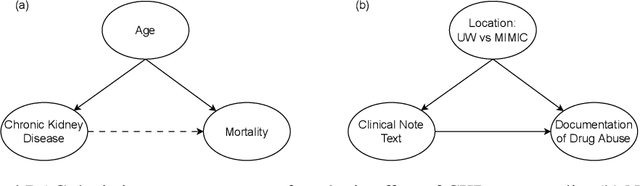

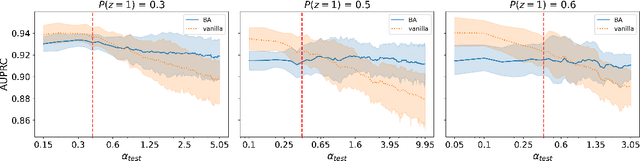
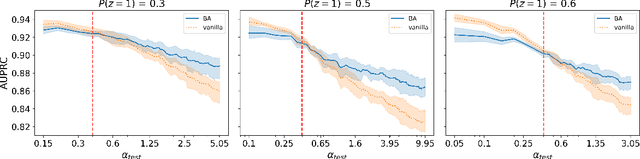
Natural Language Processing (NLP) methods have been broadly applied to clinical tasks. Machine learning and deep learning approaches have been used to improve the performance of clinical NLP. However, these approaches require sufficiently large datasets for training, and trained models have been shown to transfer poorly across sites. These issues have led to the promotion of data collection and integration across different institutions for accurate and portable models. However, this can introduce a form of bias called confounding by provenance. When source-specific data distributions differ at deployment, this may harm model performance. To address this issue, we evaluate the utility of backdoor adjustment for text classification in a multi-site dataset of clinical notes annotated for mentions of substance abuse. Using an evaluation framework devised to measure robustness to distributional shifts, we assess the utility of backdoor adjustment. Our results indicate that backdoor adjustment can effectively mitigate for confounding shift.
A Dialogue System for Assessing Activities of Daily Living: Improving Consistency with Grounded Knowledge
Jul 15, 2023



In healthcare, the ability to care for oneself is reflected in the "Activities of Daily Living (ADL)," which serve as a measure of functional ability (functioning). A lack of functioning may lead to poor living conditions requiring personal care and assistance. To accurately identify those in need of support, assistance programs continuously evaluate participants' functioning across various domains. However, the assessment process may encounter consistency issues when multiple assessors with varying levels of expertise are involved. Novice assessors, in particular, may lack the necessary preparation for real-world interactions with participants. To address this issue, we developed a dialogue system that simulates interactions between assessors and individuals of varying functioning in a natural and reproducible way. The dialogue system consists of two major modules, one for natural language understanding (NLU) and one for natural language generation (NLG), respectively. In order to generate responses consistent with the underlying knowledge base, the dialogue system requires both an understanding of the user's query and of biographical details of an individual being simulated. To fulfill this requirement, we experimented with query classification and generated responses based on those biographical details using some recently released InstructGPT-like models.
* Accepted to ACL 2023 DialDoc Workshop