 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Between the Lines: Combining Pause Dynamics and Semantic Coherence for Automated Assessment of Thought Disorder
Jul 17, 2025Formal thought disorder (FTD), a hallmark of schizophrenia spectrum disorders, manifests as incoherent speech and poses challenges for clinical assessment. Traditional clinical rating scales, though validated, are resource-intensive and lack scalability. Automated speech analysis with automatic speech recognition (ASR) allows for objective quantification of linguistic and temporal features of speech, offering scalable alternatives. The use of utterance timestamps in ASR captures pause dynamics, which are thought to reflect the cognitive processes underlying speech production. However, the utility of integrating these ASR-derived features for assessing FTD severity requires further evaluation. This study integrates pause features with semantic coherence metrics across three datasets: naturalistic self-recorded diaries (AVH, n = 140), structured picture descriptions (TOPSY, n = 72), and dream narratives (PsyCL, n = 43). We evaluated pause related features alongside established coherence measures, using support vector regression (SVR) to predict clinical FTD scores. Key findings demonstrate that pause features alone robustly predict the severity of FTD. Integrating pause features with semantic coherence metrics enhanced predictive performance compared to semantic-only models, with integration of independent models achieving correlations up to \r{ho} = 0.649 and AUC = 83.71% for severe cases detection (TOPSY, with best \r{ho} = 0.584 and AUC = 79.23% for semantic-only models). The performance gains from semantic and pause features integration held consistently across all contexts, though the nature of pause patterns was dataset-dependent. These findings suggest that frameworks combining temporal and semantic analyses provide a roadmap for refining the assessment of disorganized speech and advance automated speech analysis in psychosis.
Mitigating Confounding in Speech-Based Dementia Detection through Weight Masking
Jun 05, 2025Deep transformer models have been used to detect linguistic anomalies in patient transcripts for early Alzheimer's disease (AD) screening. While pre-trained neural language models (LMs) fine-tuned on AD transcripts perform well, little research has explored the effects of the gender of the speakers represented by these transcripts. This work addresses gender confounding in dementia detection and proposes two methods: the $\textit{Extended Confounding Filter}$ and the $\textit{Dual Filter}$, which isolate and ablate weights associated with gender. We evaluate these methods on dementia datasets with first-person narratives from patients with cognitive impairment and healthy controls. Our results show transformer models tend to overfit to training data distributions. Disrupting gender-related weights results in a deconfounded dementia classifier, with the trade-off of slightly reduced dementia detection performance.
Are LLM-generated plain language summaries truly understandable? A large-scale crowdsourced evaluation
May 15, 2025Plain language summaries (PLSs) are essential for facilitating effective communication between clinicians and patients by making complex medical information easier for laypeople to understand and act upon. Large language models (LLMs) have recently shown promise in automating PLS generation, but their effectiveness in supporting health information comprehension remains unclear. Prior evaluations have generally relied on automated scores that do not measure understandability directly, or subjective Likert-scale ratings from convenience samples with limited generalizability. To address these gaps, we conducted a large-scale crowdsourced evaluation of LLM-generated PLSs using Amazon Mechanical Turk with 150 participants. We assessed PLS quality through subjective Likert-scale ratings focusing on simplicity, informativeness, coherence, and faithfulness; and objective multiple-choice comprehension and recall measures of reader understanding. Additionally, we examined the alignment between 10 automated evaluation metrics and human judgments. Our findings indicate that while LLMs can generate PLSs that appear indistinguishable from human-written ones in subjective evaluations, human-written PLSs lead to significantly better comprehension. Furthermore, automated evaluation metrics fail to reflect human judgment, calling into question their suitability for evaluating PLSs. This is the first study to systematically evaluate LLM-generated PLSs based on both reader preferences and comprehension outcomes. Our findings highlight the need for evaluation frameworks that move beyond surface-level quality and for generation methods that explicitly optimize for layperson comprehension.
Can Language Models Understand Social Behavior in Clinical Conversations?
May 07, 2025Effective communication between providers and their patients influences health and care outcomes. The effectiveness of such conversations has been linked not only to the exchange of clinical information, but also to a range of interpersonal behaviors; commonly referred to as social signals, which are often conveyed through non-verbal cues and shape the quality of the patient-provider relationship. Recent advances in large language models (LLMs) have demonstrated an increasing ability to infer emotional and social behaviors even when analyzing only textual information. As automation increases also in clinical settings, such as for transcription of patient-provider conversations, there is growing potential for LLMs to automatically analyze and extract social behaviors from these interactions. To explore the foundational capabilities of LLMs in tracking social signals in clinical dialogue, we designed task-specific prompts and evaluated model performance across multiple architectures and prompting styles using a highly imbalanced, annotated dataset spanning 20 distinct social signals such as provider dominance, patient warmth, etc. We present the first system capable of tracking all these 20 coded signals, and uncover patterns in LLM behavior. Further analysis of model configurations and clinical context provides insights for enhancing LLM performance on social signal processing tasks in healthcare settings.
Detecting PTSD in Clinical Interviews: A Comparative Analysis of NLP Methods and Large Language Models
Apr 01, 2025Post-Traumatic Stress Disorder (PTSD) remains underdiagnosed in clinical settings, presenting opportunities for automated detection to identify patients. This study evaluates natural language processing approaches for detecting PTSD from clinical interview transcripts. We compared general and mental health-specific transformer models (BERT/RoBERTa), embedding-based methods (SentenceBERT/LLaMA), and large language model prompting strategies (zero-shot/few-shot/chain-of-thought) using the DAIC-WOZ dataset. Domain-specific models significantly outperformed general models (Mental-RoBERTa F1=0.643 vs. RoBERTa-base 0.485). LLaMA embeddings with neural networks achieved the highest performance (F1=0.700). Zero-shot prompting using DSM-5 criteria yielded competitive results without training data (F1=0.657). Performance varied significantly across symptom severity and comorbidity status, with higher accuracy for severe PTSD cases and patients with comorbid depression. Our findings highlight the potential of domain-adapted embeddings and LLMs for scalable screening while underscoring the need for improved detection of nuanced presentations and offering insights for developing clinically viable AI tools for PTSD assessment.
"Is There Anything Else?'': Examining Administrator Influence on Linguistic Features from the Cookie Theft Picture Description Cognitive Test
Mar 25, 2025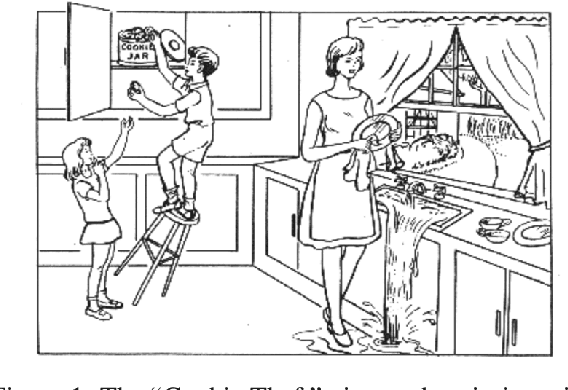
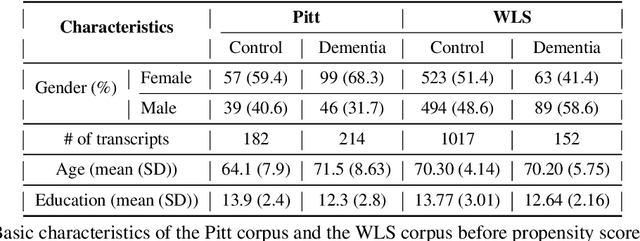
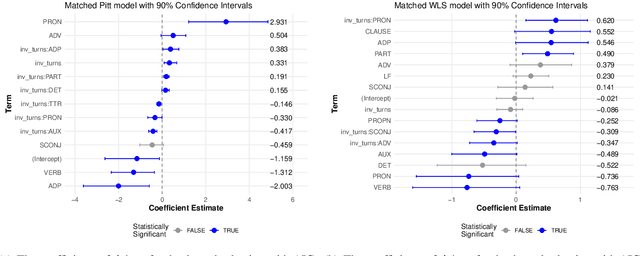
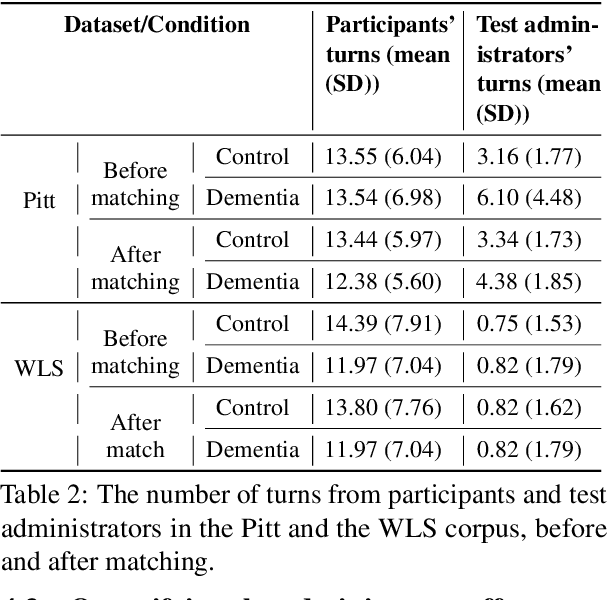
Alzheimer's Disease (AD) dementia is a progressive neurodegenerative disease that negatively impacts patients' cognitive ability. Previous studies have demonstrated that changes in naturalistic language samples can be useful for early screening of AD dementia. However, the nature of language deficits often requires test administrators to use various speech elicitation techniques during spontaneous language assessments to obtain enough propositional utterances from dementia patients. This could lead to the ``observer's effect'' on the downstream analysis that has not been fully investigated. Our study seeks to quantify the influence of test administrators on linguistic features in dementia assessment with two English corpora the ``Cookie Theft'' picture description datasets collected at different locations and test administrators show different levels of administrator involvement. Our results show that the level of test administrator involvement significantly impacts observed linguistic features in patient speech. These results suggest that many of significant linguistic features in the downstream classification task may be partially attributable to differences in the test administration practices rather than solely to participants' cognitive status. The variations in test administrator behavior can lead to systematic biases in linguistic data, potentially confounding research outcomes and clinical assessments. Our study suggests that there is a need for a more standardized test administration protocol in the development of responsible clinical speech analytics frameworks.
Bigger But Not Better: Small Neural Language Models Outperform Large Language Models in Detection of Thought Disorder
Mar 25, 2025Disorganized thinking is a key diagnostic indicator of schizophrenia-spectrum disorders. Recently, clinical estimates of the severity of disorganized thinking have been shown to correlate with measures of how difficult speech transcripts would be for large language models (LLMs) to predict. However, LLMs' deployment challenges -- including privacy concerns, computational and financial costs, and lack of transparency of training data -- limit their clinical utility. We investigate whether smaller neural language models can serve as effective alternatives for detecting positive formal thought disorder, using the same sliding window based perplexity measurements that proved effective with larger models. Surprisingly, our results show that smaller models are more sensitive to linguistic differences associated with formal thought disorder than their larger counterparts. Detection capability declines beyond a certain model size and context length, challenging the common assumption of ``bigger is better'' for LLM-based applications. Our findings generalize across audio diaries and clinical interview speech samples from individuals with psychotic symptoms, suggesting a promising direction for developing efficient, cost-effective, and privacy-preserving screening tools that can be deployed in both clinical and naturalistic settings.
Toward Large Language Models as a Therapeutic Tool: Comparing Prompting Techniques to Improve GPT-Delivered Problem-Solving Therapy
Aug 27, 2024While Large Language Models (LLMs) are being quickly adapted to many domains, including healthcare, their strengths and pitfalls remain under-explored. In our study, we examine the effects of prompt engineering to guide Large Language Models (LLMs) in delivering parts of a Problem-Solving Therapy (PST) session via text, particularly during the symptom identification and assessment phase for personalized goal setting. We present evaluation results of the models' performances by automatic metrics and experienced medical professionals. We demonstrate that the models' capability to deliver protocolized therapy can be improved with the proper use of prompt engineering methods, albeit with limitations. To our knowledge, this study is among the first to assess the effects of various prompting techniques in enhancing a generalist model's ability to deliver psychotherapy, focusing on overall quality, consistency, and empathy. Exploring LLMs' potential in delivering psychotherapy holds promise with the current shortage of mental health professionals amid significant needs, enhancing the potential utility of AI-based and AI-enhanced care services.
Reexamining Racial Disparities in Automatic Speech Recognition Performance: The Role of Confounding by Provenance
Jul 19, 2024Automatic speech recognition (ASR) models trained on large amounts of audio data are now widely used to convert speech to written text in a variety of applications from video captioning to automated assistants used in healthcare and other domains. As such, it is important that ASR models and their use is fair and equitable. Prior work examining the performance of commercial ASR systems on the Corpus of Regional African American Language (CORAAL) demonstrated significantly worse ASR performance on African American English (AAE). The current study seeks to understand the factors underlying this disparity by examining the performance of the current state-of-the-art neural network based ASR system (Whisper, OpenAI) on the CORAAL dataset. Two key findings have been identified as a result of the current study. The first confirms prior findings of significant dialectal variation even across neighboring communities, and worse ASR performance on AAE that can be improved to some extent with fine-tuning of ASR models. The second is a novel finding not discussed in prior work on CORAAL: differences in audio recording practices within the dataset have a significant impact on ASR accuracy resulting in a ``confounding by provenance'' effect in which both language use and recording quality differ by study location. These findings highlight the need for further systematic investigation to disentangle the effects of recording quality and inherent linguistic diversity when examining the fairness and bias present in neural ASR models, as any bias in ASR accuracy may have negative downstream effects on disparities in various domains of life in which ASR technology is used.
Too Big to Fail: Larger Language Models are Disproportionately Resilient to Induction of Dementia-Related Linguistic Anomalies
Jun 05, 2024As artificial neural networks grow in complexity, understanding their inner workings becomes increasingly challenging, which is particularly important in healthcare applications. The intrinsic evaluation metrics of autoregressive neural language models (NLMs), perplexity (PPL), can reflect how "surprised" an NLM model is at novel input. PPL has been widely used to understand the behavior of NLMs. Previous findings show that changes in PPL when masking attention layers in pre-trained transformer-based NLMs reflect linguistic anomalies associated with Alzheimer's disease dementia. Building upon this, we explore a novel bidirectional attention head ablation method that exhibits properties attributed to the concepts of cognitive and brain reserve in human brain studies, which postulate that people with more neurons in the brain and more efficient processing are more resilient to neurodegeneration. Our results show that larger GPT-2 models require a disproportionately larger share of attention heads to be masked/ablated to display degradation of similar magnitude to masking in smaller models. These results suggest that the attention mechanism in transformer models may present an analogue to the notions of cognitive and brain reserve and could potentially be used to model certain aspects of the progression of neurodegenerative disorders and aging.