 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeVLA-Bench: A Benchmark for the Success-Safety Gap in Vision-Language-Action Models
May 30, 2026Vision-language-action (VLA) benchmarks measure whether a policy completes a requested manipulation task, but binary success can hide safety-relevant trajectory behavior: reaching the goal while applying excessive contact, disturbing bystander objects, destabilizing the held object, or entering robot self-contact. We present SafeVLA-Bench, a post-hoc safety-evaluation framework for existing simulator-based VLA benchmarks. It formalizes task-aware safety requirements as Signal Temporal Logic (STL) specifications and reports native success with two unsafe-success metrics: Succ-But-Unsafe (SBU), the fraction of rollouts that both succeed and violate safety, and Violation Severity Index (VSI), a bounded worst-violation depth score. We instantiate SafeVLA-Bench on LIBERO and RoboCasa-365, evaluating nine policy-benchmark entries across tabletop and kitchen manipulation tasks. High task success does not imply safe execution: high-SR tabletop baselines still leave 13 to 15 percent unsafe-episode rates,and 36 to 56 percent of successful RoboCasa-365 rollouts violate at least one active safety clause. Project page: https://safevla.org.
SafePilot: A Framework for Assuring LLM-enabled Cyber-Physical Systems
Mar 23, 2026Large Language Models (LLMs), deep learning architectures with typically over 10 billion parameters, have recently begun to be integrated into various cyber-physical systems (CPS) such as robotics, industrial automation, and autopilot systems. The abstract knowledge and reasoning capabilities of LLMs are employed for tasks like planning and navigation. However, a significant challenge arises from the tendency of LLMs to produce "hallucinations" - outputs that are coherent yet factually incorrect or contextually unsuitable. This characteristic can lead to undesirable or unsafe actions in the CPS. Therefore, our research focuses on assuring the LLM-enabled CPS by enhancing their critical properties. We propose SafePilot, a novel hierarchical neuro-symbolic framework that provides end-to-end assurance for LLM-enabled CPS according to attribute-based and temporal specifications. Given a task and its specification, SafePilot first invokes a hierarchical planner with a discriminator that assesses task complexity. If the task is deemed manageable, it is passed directly to an LLM-based task planner with built-in verification. Otherwise, the hierarchical planner applies a divide-and-conquer strategy, decomposing the task into sub-tasks, each of which is individually planned and later merged into a final solution. The LLM-based task planner translates natural language constraints into formal specifications and verifies the LLM's output against them. If violations are detected, it identifies the flaw, adjusts the prompt accordingly, and re-invokes the LLM. This iterative process continues until a valid plan is produced or a predefined limit is reached. Our framework supports LLM-enabled CPS with both attribute-based and temporal constraints. Its effectiveness and adaptability are demonstrated through two illustrative case studies.
SafeGen-LLM: Enhancing Safety Generalization in Task Planning for Robotic Systems
Feb 27, 2026Safety-critical task planning in robotic systems remains challenging: classical planners suffer from poor scalability, Reinforcement Learning (RL)-based methods generalize poorly, and base Large Language Models (LLMs) cannot guarantee safety. To address this gap, we propose safety-generalizable large language models, named SafeGen-LLM. SafeGen-LLM can not only enhance the safety satisfaction of task plans but also generalize well to novel safety properties in various domains. We first construct a multi-domain Planning Domain Definition Language 3 (PDDL3) benchmark with explicit safety constraints. Then, we introduce a two-stage post-training framework: Supervised Fine-Tuning (SFT) on a constraint-compliant planning dataset to learn planning syntax and semantics, and Group Relative Policy Optimization (GRPO) guided by fine-grained reward machines derived from formal verification to enforce safety alignment and by curriculum learning to better handle complex tasks. Extensive experiments show that SafeGen-LLM achieves strong safety generalization and outperforms frontier proprietary baselines across multi-domain planning tasks and multiple input formats (e.g., PDDLs and natural language).
Reading Between the Lines: Combining Pause Dynamics and Semantic Coherence for Automated Assessment of Thought Disorder
Jul 17, 2025Formal thought disorder (FTD), a hallmark of schizophrenia spectrum disorders, manifests as incoherent speech and poses challenges for clinical assessment. Traditional clinical rating scales, though validated, are resource-intensive and lack scalability. Automated speech analysis with automatic speech recognition (ASR) allows for objective quantification of linguistic and temporal features of speech, offering scalable alternatives. The use of utterance timestamps in ASR captures pause dynamics, which are thought to reflect the cognitive processes underlying speech production. However, the utility of integrating these ASR-derived features for assessing FTD severity requires further evaluation. This study integrates pause features with semantic coherence metrics across three datasets: naturalistic self-recorded diaries (AVH, n = 140), structured picture descriptions (TOPSY, n = 72), and dream narratives (PsyCL, n = 43). We evaluated pause related features alongside established coherence measures, using support vector regression (SVR) to predict clinical FTD scores. Key findings demonstrate that pause features alone robustly predict the severity of FTD. Integrating pause features with semantic coherence metrics enhanced predictive performance compared to semantic-only models, with integration of independent models achieving correlations up to \r{ho} = 0.649 and AUC = 83.71% for severe cases detection (TOPSY, with best \r{ho} = 0.584 and AUC = 79.23% for semantic-only models). The performance gains from semantic and pause features integration held consistently across all contexts, though the nature of pause patterns was dataset-dependent. These findings suggest that frameworks combining temporal and semantic analyses provide a roadmap for refining the assessment of disorganized speech and advance automated speech analysis in psychosis.
Bigger But Not Better: Small Neural Language Models Outperform Large Language Models in Detection of Thought Disorder
Mar 25, 2025Disorganized thinking is a key diagnostic indicator of schizophrenia-spectrum disorders. Recently, clinical estimates of the severity of disorganized thinking have been shown to correlate with measures of how difficult speech transcripts would be for large language models (LLMs) to predict. However, LLMs' deployment challenges -- including privacy concerns, computational and financial costs, and lack of transparency of training data -- limit their clinical utility. We investigate whether smaller neural language models can serve as effective alternatives for detecting positive formal thought disorder, using the same sliding window based perplexity measurements that proved effective with larger models. Surprisingly, our results show that smaller models are more sensitive to linguistic differences associated with formal thought disorder than their larger counterparts. Detection capability declines beyond a certain model size and context length, challenging the common assumption of ``bigger is better'' for LLM-based applications. Our findings generalize across audio diaries and clinical interview speech samples from individuals with psychotic symptoms, suggesting a promising direction for developing efficient, cost-effective, and privacy-preserving screening tools that can be deployed in both clinical and naturalistic settings.
Useful Blunders: Can Automated Speech Recognition Errors Improve Downstream Dementia Classification?
Jan 10, 2024\textbf{Objectives}: We aimed to investigate how errors from automatic speech recognition (ASR) systems affect dementia classification accuracy, specifically in the ``Cookie Theft'' picture description task. We aimed to assess whether imperfect ASR-generated transcripts could provide valuable information for distinguishing between language samples from cognitively healthy individuals and those with Alzheimer's disease (AD). \textbf{Methods}: We conducted experiments using various ASR models, refining their transcripts with post-editing techniques. Both these imperfect ASR transcripts and manually transcribed ones were used as inputs for the downstream dementia classification. We conducted comprehensive error analysis to compare model performance and assess ASR-generated transcript effectiveness in dementia classification. \textbf{Results}: Imperfect ASR-generated transcripts surprisingly outperformed manual transcription for distinguishing between individuals with AD and those without in the ``Cookie Theft'' task. These ASR-based models surpassed the previous state-of-the-art approach, indicating that ASR errors may contain valuable cues related to dementia. The synergy between ASR and classification models improved overall accuracy in dementia classification. \textbf{Conclusion}: Imperfect ASR transcripts effectively capture linguistic anomalies linked to dementia, improving accuracy in classification tasks. This synergy between ASR and classification models underscores ASR's potential as a valuable tool in assessing cognitive impairment and related clinical applications.
GPT-D: Inducing Dementia-related Linguistic Anomalies by Deliberate Degradation of Artificial Neural Language Models
Mar 25, 2022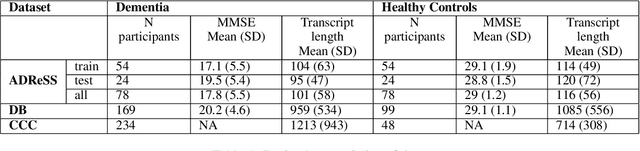

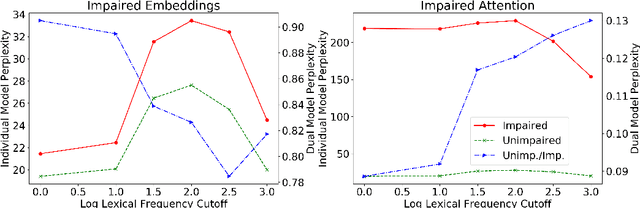

Deep learning (DL) techniques involving fine-tuning large numbers of model parameters have delivered impressive performance on the task of discriminating between language produced by cognitively healthy individuals, and those with Alzheimer's disease (AD). However, questions remain about their ability to generalize beyond the small reference sets that are publicly available for research. As an alternative to fitting model parameters directly, we propose a novel method by which a Transformer DL model (GPT-2) pre-trained on general English text is paired with an artificially degraded version of itself (GPT-D), to compute the ratio between these two models' \textit{perplexities} on language from cognitively healthy and impaired individuals. This technique approaches state-of-the-art performance on text data from a widely used "Cookie Theft" picture description task, and unlike established alternatives also generalizes well to spontaneous conversations. Furthermore, GPT-D generates text with characteristics known to be associated with AD, demonstrating the induction of dementia-related linguistic anomalies. Our study is a step toward better understanding of the relationships between the inner workings of generative neural language models, the language that they produce, and the deleterious effects of dementia on human speech and language characteristics.