 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Evaluation of Text and Audio Simplification: A Methodological Replication Study
Aug 20, 2025This study serves as a methodological replication of Leroy et al. (2022) research, which investigated the impact of text simplification on healthcare information comprehension in the evolving multimedia landscape. Building upon the original studys insights, our replication study evaluates audio content, recognizing its increasing importance in disseminating healthcare information in the digital age. Specifically, we explored the influence of text simplification on perceived and actual difficulty when users engage with audio content automatically generated from that text. Our replication involved 44 participants for whom we assessed their comprehension of healthcare information presented as audio created using Leroy et al. (2022) original and simplified texts. The findings from our study highlight the effectiveness of text simplification in enhancing perceived understandability and actual comprehension, aligning with the original studys results. Additionally, we examined the role of education level and language proficiency, shedding light on their potential impact on healthcare information access and understanding. This research underscores the practical value of text simplification tools in promoting health literacy. It suggests the need for tailored communication strategies to reach diverse audiences effectively in the healthcare domain.
Automated Feedback Loops to Protect Text Simplification with Generative AI from Information Loss
May 22, 2025Understanding health information is essential in achieving and maintaining a healthy life. We focus on simplifying health information for better understanding. With the availability of generative AI, the simplification process has become efficient and of reasonable quality, however, the algorithms remove information that may be crucial for comprehension. In this study, we compare generative AI to detect missing information in simplified text, evaluate its importance, and fix the text with the missing information. We collected 50 health information texts and simplified them using gpt-4-0613. We compare five approaches to identify missing elements and regenerate the text by inserting the missing elements. These five approaches involve adding missing entities and missing words in various ways: 1) adding all the missing entities, 2) adding all missing words, 3) adding the top-3 entities ranked by gpt-4-0613, and 4, 5) serving as controls for comparison, adding randomly chosen entities. We use cosine similarity and ROUGE scores to evaluate the semantic similarity and content overlap between the original, simplified, and reconstructed simplified text. We do this for both summaries and full text. Overall, we find that adding missing entities improves the text. Adding all the missing entities resulted in better text regeneration, which was better than adding the top-ranked entities or words, or random words. Current tools can identify these entities, but are not valuable in ranking them.
Are LLM-generated plain language summaries truly understandable? A large-scale crowdsourced evaluation
May 15, 2025Plain language summaries (PLSs) are essential for facilitating effective communication between clinicians and patients by making complex medical information easier for laypeople to understand and act upon. Large language models (LLMs) have recently shown promise in automating PLS generation, but their effectiveness in supporting health information comprehension remains unclear. Prior evaluations have generally relied on automated scores that do not measure understandability directly, or subjective Likert-scale ratings from convenience samples with limited generalizability. To address these gaps, we conducted a large-scale crowdsourced evaluation of LLM-generated PLSs using Amazon Mechanical Turk with 150 participants. We assessed PLS quality through subjective Likert-scale ratings focusing on simplicity, informativeness, coherence, and faithfulness; and objective multiple-choice comprehension and recall measures of reader understanding. Additionally, we examined the alignment between 10 automated evaluation metrics and human judgments. Our findings indicate that while LLMs can generate PLSs that appear indistinguishable from human-written ones in subjective evaluations, human-written PLSs lead to significantly better comprehension. Furthermore, automated evaluation metrics fail to reflect human judgment, calling into question their suitability for evaluating PLSs. This is the first study to systematically evaluate LLM-generated PLSs based on both reader preferences and comprehension outcomes. Our findings highlight the need for evaluation frameworks that move beyond surface-level quality and for generation methods that explicitly optimize for layperson comprehension.
ICD Codes are Insufficient to Create Datasets for Machine Learning: An Evaluation Using All of Us Data for Coccidioidomycosis and Myocardial Infarction
Jul 10, 2024In medicine, machine learning (ML) datasets are often built using the International Classification of Diseases (ICD) codes. As new models are being developed, there is a need for larger datasets. However, ICD codes are intended for billing. We aim to determine how suitable ICD codes are for creating datasets to train ML models. We focused on a rare and common disease using the All of Us database. First, we compared the patient cohort created using ICD codes for Valley fever (coccidioidomycosis, CM) with that identified via serological confirmation. Second, we compared two similarly created patient cohorts for myocardial infarction (MI) patients. We identified significant discrepancies between these two groups, and the patient overlap was small. The CM cohort had 811 patients in the ICD-10 group, 619 patients in the positive-serology group, and 24 with both. The MI cohort had 14,875 patients in the ICD-10 group, 23,598 in the MI laboratory-confirmed group, and 6,531 in both. Demographics, rates of disease symptoms, and other clinical data varied across our case study cohorts.
Utilizing Large Language Models to Generate Synthetic Data to Increase the Performance of BERT-Based Neural Networks
May 08, 2024An important issue impacting healthcare is a lack of available experts. Machine learning (ML) models could resolve this by aiding in diagnosing patients. However, creating datasets large enough to train these models is expensive. We evaluated large language models (LLMs) for data creation. Using Autism Spectrum Disorders (ASD), we prompted ChatGPT and GPT-Premium to generate 4,200 synthetic observations to augment existing medical data. Our goal is to label behaviors corresponding to autism criteria and improve model accuracy with synthetic training data. We used a BERT classifier pre-trained on biomedical literature to assess differences in performance between models. A random sample (N=140) from the LLM-generated data was evaluated by a clinician and found to contain 83% correct example-label pairs. Augmenting data increased recall by 13% but decreased precision by 16%, correlating with higher quality and lower accuracy across pairs. Future work will analyze how different synthetic data traits affect ML outcomes.
Text and Audio Simplification: Human vs. ChatGPT
Apr 29, 2024
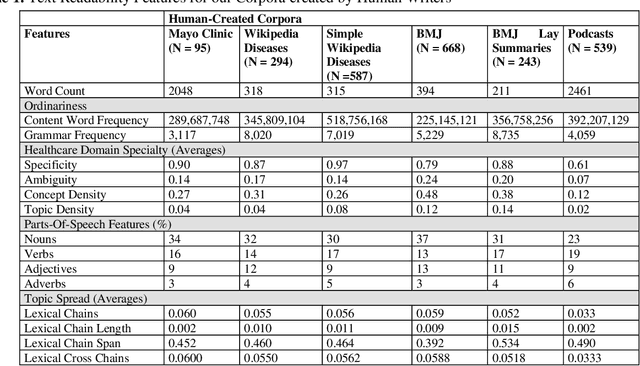
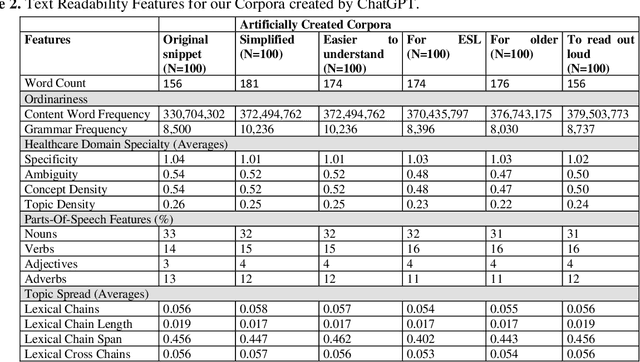
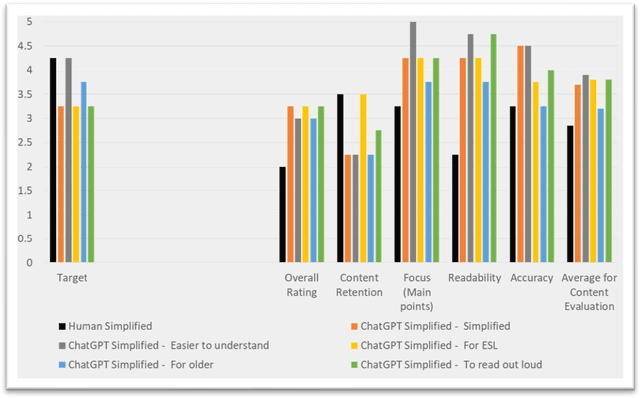
Text and audio simplification to increase information comprehension are important in healthcare. With the introduction of ChatGPT, an evaluation of its simplification performance is needed. We provide a systematic comparison of human and ChatGPT simplified texts using fourteen metrics indicative of text difficulty. We briefly introduce our online editor where these simplification tools, including ChatGPT, are available. We scored twelve corpora using our metrics: six text, one audio, and five ChatGPT simplified corpora. We then compare these corpora with texts simplified and verified in a prior user study. Finally, a medical domain expert evaluated these texts and five, new ChatGPT simplified versions. We found that simple corpora show higher similarity with the human simplified texts. ChatGPT simplification moves metrics in the right direction. The medical domain expert evaluation showed a preference for the ChatGPT style, but the text itself was rated lower for content retention.
Effects of Added Emphasis and Pause in Audio Delivery of Health Information
Apr 29, 2024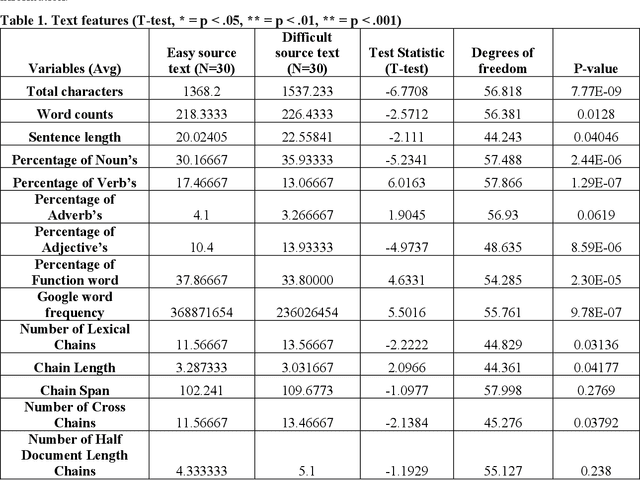
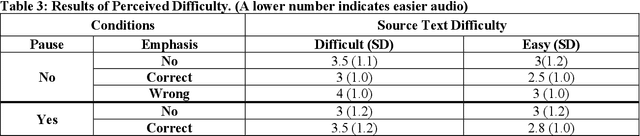
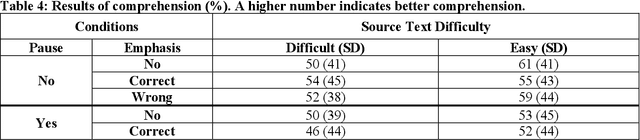
Health literacy is crucial to supporting good health and is a major national goal. Audio delivery of information is becoming more popular for informing oneself. In this study, we evaluate the effect of audio enhancements in the form of information emphasis and pauses with health texts of varying difficulty and we measure health information comprehension and retention. We produced audio snippets from difficult and easy text and conducted the study on Amazon Mechanical Turk (AMT). Our findings suggest that emphasis matters for both information comprehension and retention. When there is no added pause, emphasizing significant information can lower the perceived difficulty for difficult and easy texts. Comprehension is higher (54%) with correctly placed emphasis for the difficult texts compared to not adding emphasis (50%). Adding a pause lowers perceived difficulty and can improve retention but adversely affects information comprehension.
APPLS: A Meta-evaluation Testbed for Plain Language Summarization
May 23, 2023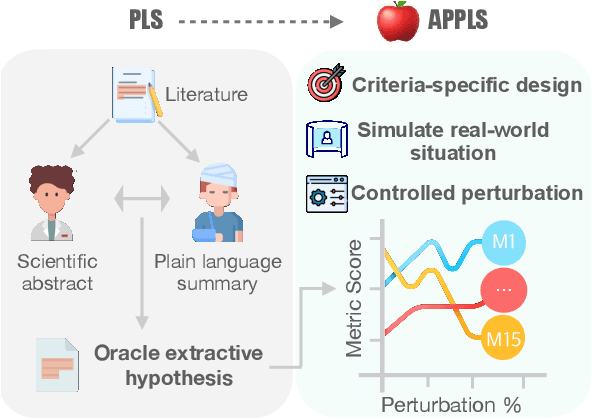



While there has been significant development of models for Plain Language Summarization (PLS), evaluation remains a challenge. This is in part because PLS involves multiple, interrelated language transformations (e.g., adding background explanations, removing specialized terminology). No metrics are explicitly engineered for PLS, and the suitability of other text generation evaluation metrics remains unclear. To address these concerns, our study presents a granular meta-evaluation testbed, APPLS, designed to evaluate existing metrics for PLS. Drawing on insights from previous research, we define controlled perturbations for our testbed along four criteria that a metric of plain language should capture: informativeness, simplification, coherence, and faithfulness. Our analysis of metrics using this testbed reveals that current metrics fail to capture simplification, signaling a crucial gap. In response, we introduce POMME, a novel metric designed to assess text simplification in PLS. We demonstrate its correlation with simplification perturbations and validate across a variety of datasets. Our research contributes the first meta-evaluation testbed for PLS and a comprehensive evaluation of existing metrics, offering insights with relevance to other text generation tasks.
CELLS: A Parallel Corpus for Biomedical Lay Language Generation
Nov 07, 2022
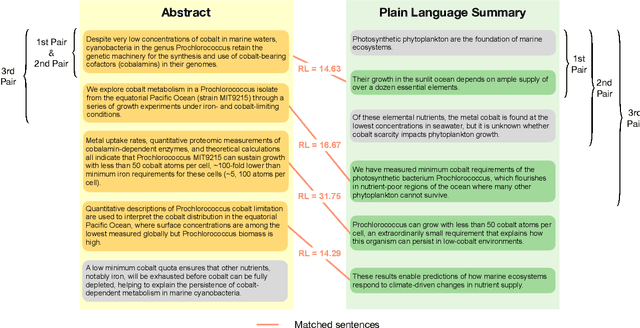
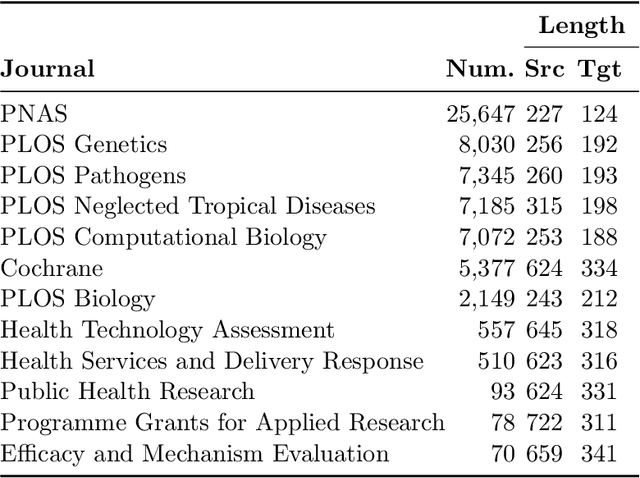
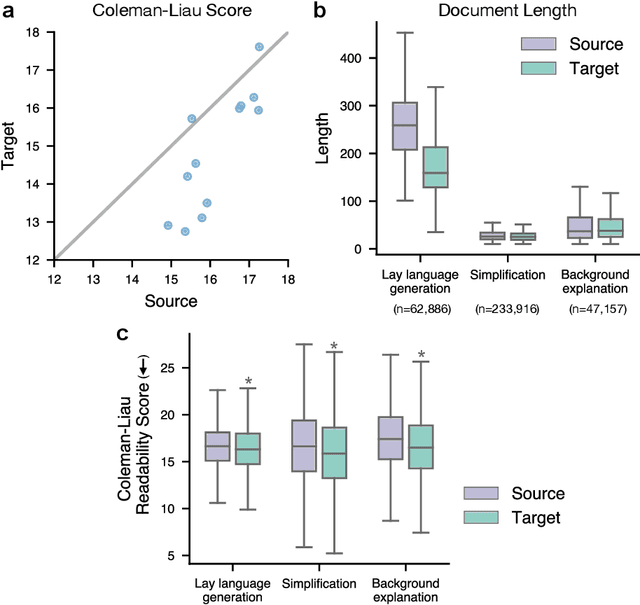
Recent lay language generation systems have used Transformer models trained on a parallel corpus to increase health information accessibility. However, the applicability of these models is constrained by the limited size and topical breadth of available corpora. We introduce CELLS, the largest (63k pairs) and broadest-ranging (12 journals) parallel corpus for lay language generation. The abstract and the corresponding lay language summary are written by domain experts, assuring the quality of our dataset. Furthermore, qualitative evaluation of expert-authored plain language summaries has revealed background explanation as a key strategy to increase accessibility. Such explanation is challenging for neural models to generate because it goes beyond simplification by adding content absent from the source. We derive two specialized paired corpora from CELLS to address key challenges in lay language generation: generating background explanations and simplifying the original abstract. We adopt retrieval-augmented models as an intuitive fit for the task of background explanation generation, and show improvements in summary quality and simplicity while maintaining factual correctness. Taken together, this work presents the first comprehensive study of background explanation for lay language generation, paving the path for disseminating scientific knowledge to a broader audience. CELLS is publicly available at: https://github.com/LinguisticAnomalies/pls_retrieval.
AutoMeTS: The Autocomplete for Medical Text Simplification
Oct 20, 2020
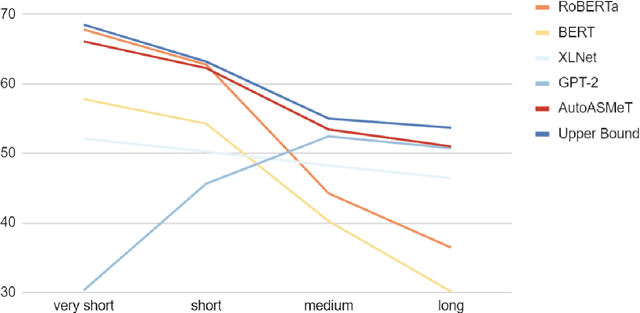
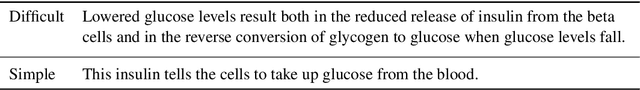

The goal of text simplification (TS) is to transform difficult text into a version that is easier to understand and more broadly accessible to a wide variety of readers. In some domains, such as healthcare, fully automated approaches cannot be used since information must be accurately preserved. Instead, semi-automated approaches can be used that assist a human writer in simplifying text faster and at a higher quality. In this paper, we examine the application of autocomplete to text simplification in the medical domain. We introduce a new parallel medical data set consisting of aligned English Wikipedia with Simple English Wikipedia sentences and examine the application of pretrained neural language models (PNLMs) on this dataset. We compare four PNLMs(BERT, RoBERTa, XLNet, and GPT-2), and show how the additional context of the sentence to be simplified can be incorporated to achieve better results (6.17% absolute improvement over the best individual model). We also introduce an ensemble model that combines the four PNLMs and outperforms the best individual model by 2.1%, resulting in an overall word prediction accuracy of 64.52%.