 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMeTS: The Autocomplete for Medical Text Simplification
Paper and Code

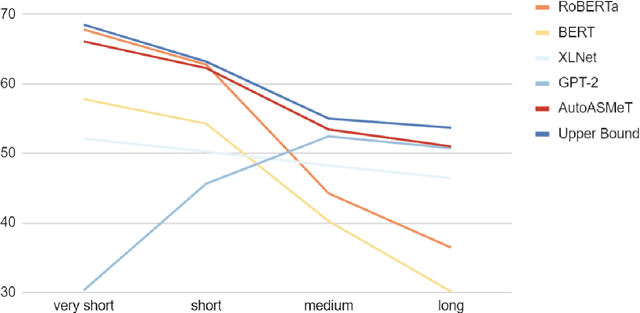

The goal of text simplification (TS) is to transform difficult text into a version that is easier to understand and more broadly accessible to a wide variety of readers. In some domains, such as healthcare, fully automated approaches cannot be used since information must be accurately preserved. Instead, semi-automated approaches can be used that assist a human writer in simplifying text faster and at a higher quality. In this paper, we examine the application of autocomplete to text simplification in the medical domain. We introduce a new parallel medical data set consisting of aligned English Wikipedia with Simple English Wikipedia sentences and examine the application of pretrained neural language models (PNLMs) on this dataset. We compare four PNLMs(BERT, RoBERTa, XLNet, and GPT-2), and show how the additional context of the sentence to be simplified can be incorporated to achieve better results (6.17% absolute improvement over the best individual model). We also introduce an ensemble model that combines the four PNLMs and outperforms the best individual model by 2.1%, resulting in an overall word prediction accuracy of 64.52%.