 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of ChatGPT Family of Models for Biomedical Reasoning and Classification
Apr 05, 2023



Recent advances in large language models (LLMs) have shown impressive ability in biomedical question-answering, but have not been adequately investigated for more specific biomedical applications. This study investigates the performance of LLMs such as the ChatGPT family of models (GPT-3.5s, GPT-4) in biomedical tasks beyond question-answering. Because no patient data can be passed to the OpenAI API public interface, we evaluated model performance with over 10000 samples as proxies for two fundamental tasks in the clinical domain - classification and reasoning. The first task is classifying whether statements of clinical and policy recommendations in scientific literature constitute health advice. The second task is causal relation detection from the biomedical literature. We compared LLMs with simpler models, such as bag-of-words (BoW) with logistic regression, and fine-tuned BioBERT models. Despite the excitement around viral ChatGPT, we found that fine-tuning for two fundamental NLP tasks remained the best strategy. The simple BoW model performed on par with the most complex LLM prompting. Prompt engineering required significant investment.
Mitigating Data Scarcity for Large Language Models
Feb 03, 2023



In recent years, pretrained neural language models (PNLMs) have taken the field of natural language processing by storm, achieving new benchmarks and state-of-the-art performances. These models often rely heavily on annotated data, which may not always be available. Data scarcity are commonly found in specialized domains, such as medical, or in low-resource languages that are underexplored by AI research. In this dissertation, we focus on mitigating data scarcity using data augmentation and neural ensemble learning techniques for neural language models. In both research directions, we implement neural network algorithms and evaluate their impact on assisting neural language models in downstream NLP tasks. Specifically, for data augmentation, we explore two techniques: 1) creating positive training data by moving an answer span around its original context and 2) using text simplification techniques to introduce a variety of writing styles to the original training data. Our results indicate that these simple and effective solutions improve the performance of neural language models considerably in low-resource NLP domains and tasks. For neural ensemble learning, we use a multilabel neural classifier to select the best prediction outcome from a variety of individual pretrained neural language models trained for a low-resource medical text simplification task.
Extracting Space Situational Awareness Events from News Text
Jan 15, 2022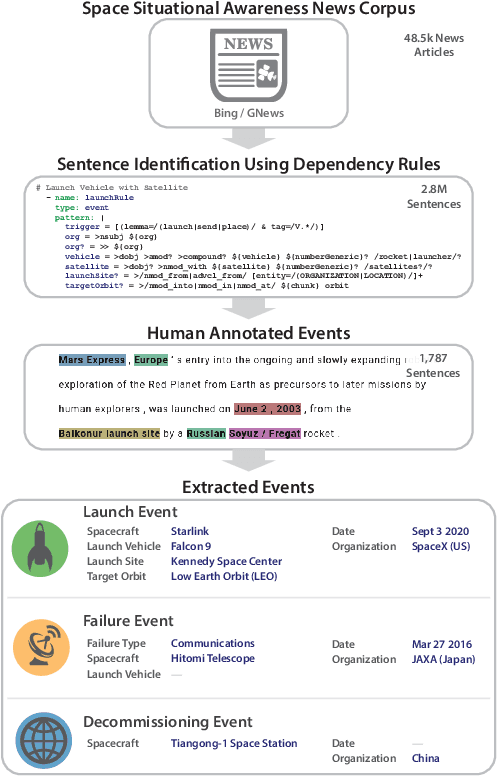
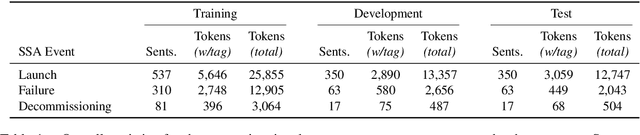

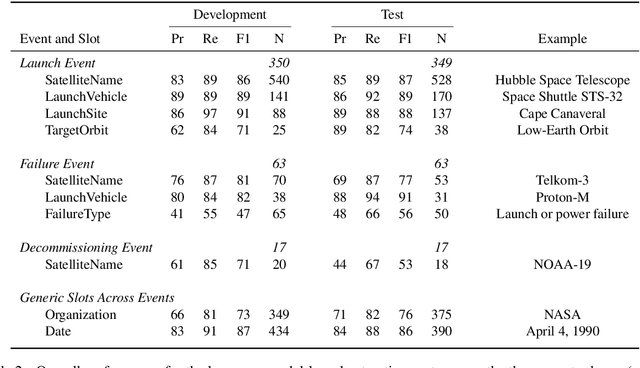
Space situational awareness typically makes use of physical measurements from radar, telescopes, and other assets to monitor satellites and other spacecraft for operational, navigational, and defense purposes. In this work we explore using textual input for the space situational awareness task. We construct a corpus of 48.5k news articles spanning all known active satellites between 2009 and 2020. Using a dependency-rule-based extraction system designed to target three high-impact events -- spacecraft launches, failures, and decommissionings, we identify 1,787 space-event sentences that are then annotated by humans with 15.9k labels for event slots. We empirically demonstrate a state-of-the-art neural extraction system achieves an overall F1 between 53 and 91 per slot for event extraction in this low-resource, high-impact domain.
How May I Help You? Using Neural Text Simplification to Improve Downstream NLP Tasks
Sep 14, 2021

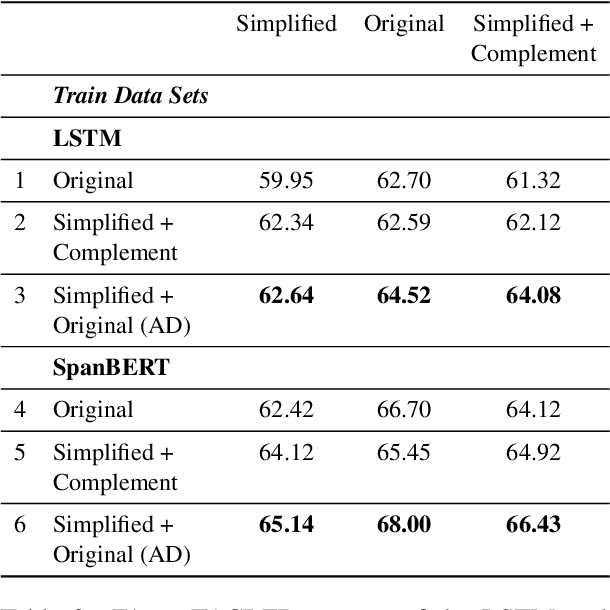
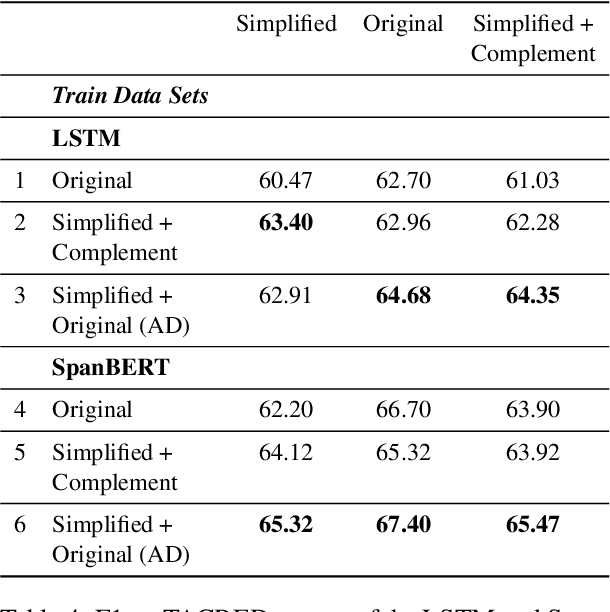
The general goal of text simplification (TS) is to reduce text complexity for human consumption. This paper investigates another potential use of neural TS: assisting machines performing natural language processing (NLP) tasks. We evaluate the use of neural TS in two ways: simplifying input texts at prediction time and augmenting data to provide machines with additional information during training. We demonstrate that the latter scenario provides positive effects on machine performance on two separate datasets. In particular, the latter use of TS improves the performances of LSTM (1.82-1.98%) and SpanBERT (0.7-1.3%) extractors on TACRED, a complex, large-scale, real-world relation extraction task. Further, the same setting yields improvements of up to 0.65% matched and 0.62% mismatched accuracies for a BERT text classifier on MNLI, a practical natural language inference dataset.
Cheap and Good? Simple and Effective Data Augmentation for Low Resource Machine Reading
Jun 08, 2021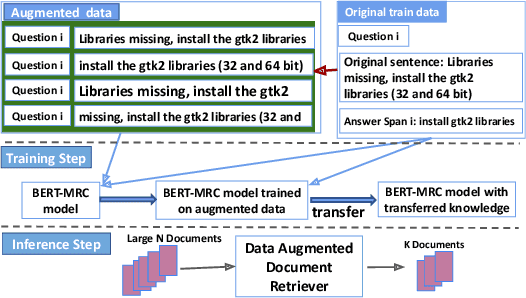
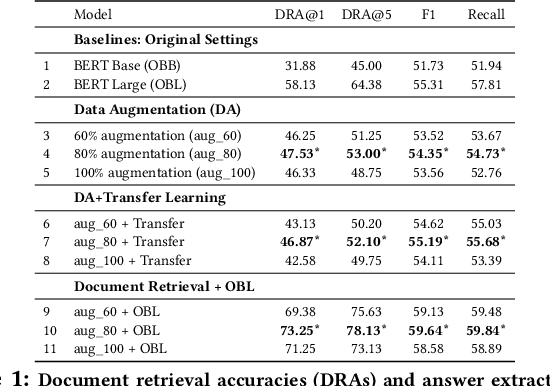
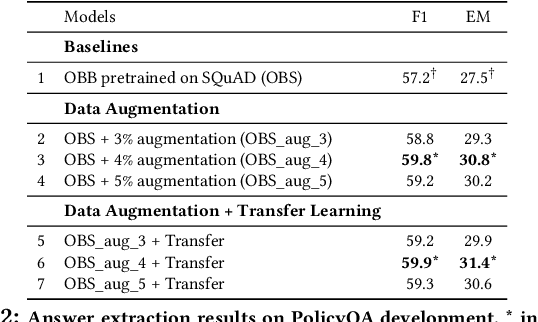

We propose a simple and effective strategy for data augmentation for low-resource machine reading comprehension (MRC). Our approach first pretrains the answer extraction components of a MRC system on the augmented data that contains approximate context of the correct answers, before training it on the exact answer spans. The approximate context helps the QA method components in narrowing the location of the answers. We demonstrate that our simple strategy substantially improves both document retrieval and answer extraction performance by providing larger context of the answers and additional training data. In particular, our method significantly improves the performance of BERT based retriever (15.12\%), and answer extractor (4.33\% F1) on TechQA, a complex, low-resource MRC task. Further, our data augmentation strategy yields significant improvements of up to 3.9\% exact match (EM) and 2.7\% F1 for answer extraction on PolicyQA, another practical but moderate sized QA dataset that also contains long answer spans.
AutoMeTS: The Autocomplete for Medical Text Simplification
Oct 20, 2020
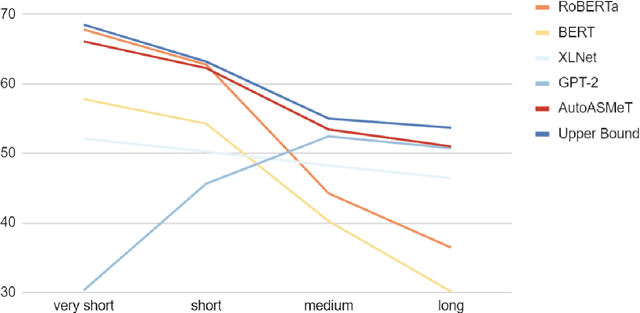
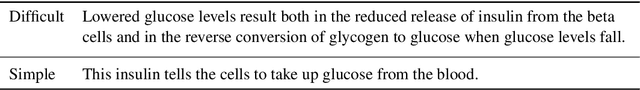

The goal of text simplification (TS) is to transform difficult text into a version that is easier to understand and more broadly accessible to a wide variety of readers. In some domains, such as healthcare, fully automated approaches cannot be used since information must be accurately preserved. Instead, semi-automated approaches can be used that assist a human writer in simplifying text faster and at a higher quality. In this paper, we examine the application of autocomplete to text simplification in the medical domain. We introduce a new parallel medical data set consisting of aligned English Wikipedia with Simple English Wikipedia sentences and examine the application of pretrained neural language models (PNLMs) on this dataset. We compare four PNLMs(BERT, RoBERTa, XLNet, and GPT-2), and show how the additional context of the sentence to be simplified can be incorporated to achieve better results (6.17% absolute improvement over the best individual model). We also introduce an ensemble model that combines the four PNLMs and outperforms the best individual model by 2.1%, resulting in an overall word prediction accuracy of 64.52%.
The Language of Food during the Pandemic: Hints about the Dietary Effects of Covid-19
Oct 15, 2020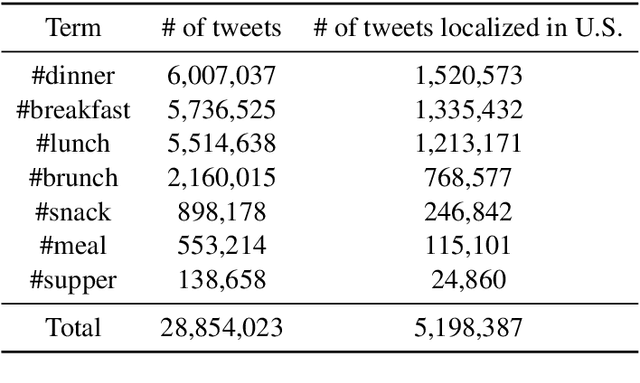
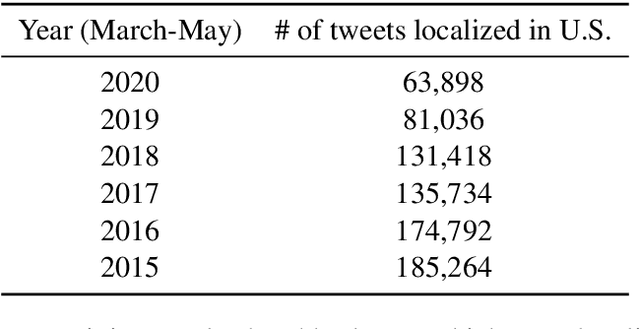
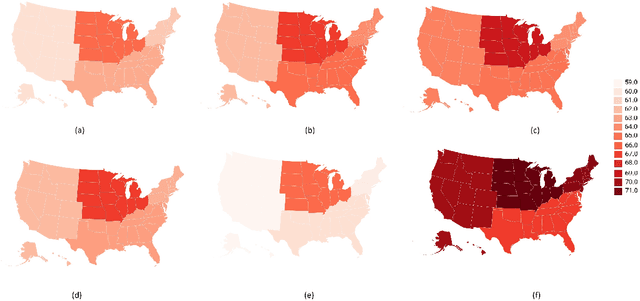
We study the language of food on Twitter during the pandemic lockdown in the United States, focusing on the two month period of March 15 to May 15, 2020. Specifically, we analyze over770,000 tweets published during the lockdown and the equivalent period in the five previous years and highlight several worrying trends. First, we observe that during the lockdown there was a notable shift from mentions of healthy foods to unhealthy foods. Second, we show an increased pointwise mutual information of depression hashtags with food-related tweets posted during the lockdown and an increased association between depression hashtags and unhealthy foods, tobacco, and alcohol during the lockdown.