 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Long-Tail Gap: Robust Retrieval-Augmented Relation Completion via Multi-Stage Paraphrase Infusion
Apr 24, 2026Large language models (LLMs) struggle with relation completion (RC), both with and without retrieval-augmented generation (RAG), particularly when the required information is rare or sparsely represented. To address this, we propose a novel multi-stage paraphrase-guided relation-completion framework, RC-RAG, that systematically incorporates relation paraphrases across multiple stages. In particular, RC-RAG: (a) integrates paraphrases into retrieval to expand lexical coverage of the relation, (b) uses paraphrases to generate relation-aware summaries, and (c) leverages paraphrases during generation to guide reasoning for relation completion. Importantly, our method does not require any model fine-tuning. Experiments with five LLMs on two benchmark datasets show that RC-RAG consistently outperforms several RAG baselines. In long-tail settings, the best-performing LLM augmented with RC-RAG improves by 40.6 Exact Match (EM) points over its standalone performance and surpasses two strong RAG baselines by 16.0 and 13.8 EM points, respectively, while maintaining low computational overhead.
Structured Semantic Information Helps Retrieve Better Examples for In-Context Learning in Few-Shot Relation Extraction
Jan 28, 2026This paper presents several strategies to automatically obtain additional examples for in-context learning of one-shot relation extraction. Specifically, we introduce a novel strategy for example selection, in which new examples are selected based on the similarity of their underlying syntactic-semantic structure to the provided one-shot example. We show that this method results in complementary word choices and sentence structures when compared to LLM-generated examples. When these strategies are combined, the resulting hybrid system achieves a more holistic picture of the relations of interest than either method alone. Our framework transfers well across datasets (FS-TACRED and FS-FewRel) and LLM families (Qwen and Gemma). Overall, our hybrid selection method consistently outperforms alternative strategies and achieves state-of-the-art performance on FS-TACRED and strong gains on a customized FewRel subset.
The Alchemy of Thought: Understanding In-Context Learning Through Supervised Classification
Jan 03, 2026In-context learning (ICL) has become a prominent paradigm to rapidly customize LLMs to new tasks without fine-tuning. However, despite the empirical evidence of its usefulness, we still do not truly understand how ICL works. In this paper, we compare the behavior of in-context learning with supervised classifiers trained on ICL demonstrations to investigate three research questions: (1) Do LLMs with ICL behave similarly to classifiers trained on the same examples? (2) If so, which classifiers are closer, those based on gradient descent (GD) or those based on k-nearest neighbors (kNN)? (3) When they do not behave similarly, what conditions are associated with differences in behavior? Using text classification as a use case, with six datasets and three LLMs, we observe that LLMs behave similarly to these classifiers when the relevance of demonstrations is high. On average, ICL is closer to kNN than logistic regression, giving empirical evidence that the attention mechanism behaves more similarly to kNN than GD. However, when demonstration relevance is low, LLMs perform better than these classifiers, likely because LLMs can back off to their parametric memory, a luxury these classifiers do not have.
Can LLMs Judge Debates? Evaluating Non-Linear Reasoning via Argumentation Theory Semantics
Sep 19, 2025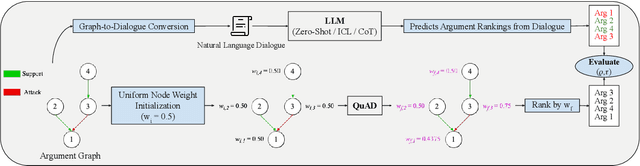
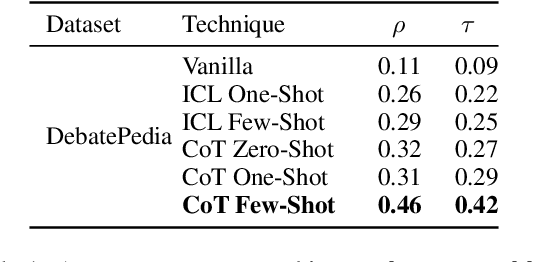
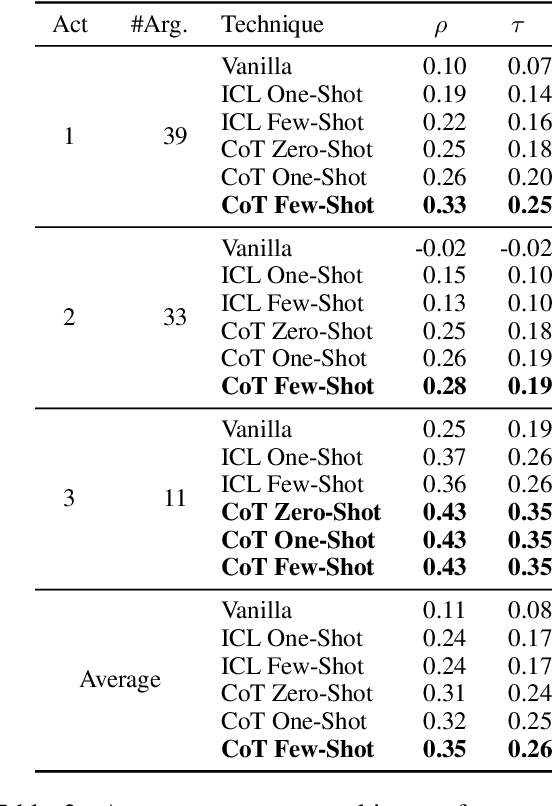
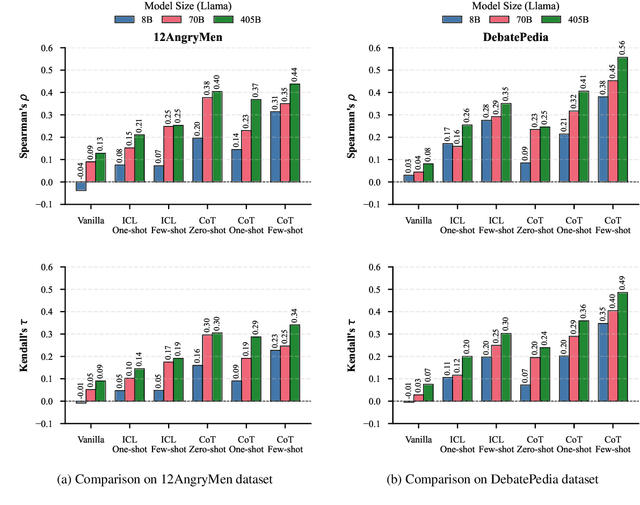
Large Language Models (LLMs) excel at linear reasoning tasks but remain underexplored on non-linear structures such as those found in natural debates, which are best expressed as argument graphs. We evaluate whether LLMs can approximate structured reasoning from Computational Argumentation Theory (CAT). Specifically, we use Quantitative Argumentation Debate (QuAD) semantics, which assigns acceptability scores to arguments based on their attack and support relations. Given only dialogue-formatted debates from two NoDE datasets, models are prompted to rank arguments without access to the underlying graph. We test several LLMs under advanced instruction strategies, including Chain-of-Thought and In-Context Learning. While models show moderate alignment with QuAD rankings, performance degrades with longer inputs or disrupted discourse flow. Advanced prompting helps mitigate these effects by reducing biases related to argument length and position. Our findings highlight both the promise and limitations of LLMs in modeling formal argumentation semantics and motivate future work on graph-aware reasoning.
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark
May 24, 2025We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models' (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
Fane at SemEval-2025 Task 10: Zero-Shot Entity Framing with Large Language Models
Apr 29, 2025Understanding how news narratives frame entities is crucial for studying media's impact on societal perceptions of events. In this paper, we evaluate the zero-shot capabilities of large language models (LLMs) in classifying framing roles. Through systematic experimentation, we assess the effects of input context, prompting strategies, and task decomposition. Our findings show that a hierarchical approach of first identifying broad roles and then fine-grained roles, outperforms single-step classification. We also demonstrate that optimal input contexts and prompts vary across task levels, highlighting the need for subtask-specific strategies. We achieve a Main Role Accuracy of 89.4% and an Exact Match Ratio of 34.5%, demonstrating the effectiveness of our approach. Our findings emphasize the importance of tailored prompt design and input context optimization for improving LLM performance in entity framing.
Say Less, Mean More: Leveraging Pragmatics in Retrieval-Augmented Generation
Feb 25, 2025We propose a simple, unsupervised method that injects pragmatic principles in retrieval-augmented generation (RAG) frameworks such as Dense Passage Retrieval~\cite{karpukhin2020densepassageretrievalopendomain} to enhance the utility of retrieved contexts. Our approach first identifies which sentences in a pool of documents retrieved by RAG are most relevant to the question at hand, cover all the topics addressed in the input question and no more, and then highlights these sentences within their context, before they are provided to the LLM, without truncating or altering the context in any other way. We show that this simple idea brings consistent improvements in experiments on three question answering tasks (ARC-Challenge, PubHealth and PopQA) using five different LLMs. It notably enhances relative accuracy by up to 19.7\% on PubHealth and 10\% on ARC-Challenge compared to a conventional RAG system.
MorphNLI: A Stepwise Approach to Natural Language Inference Using Text Morphing
Feb 13, 2025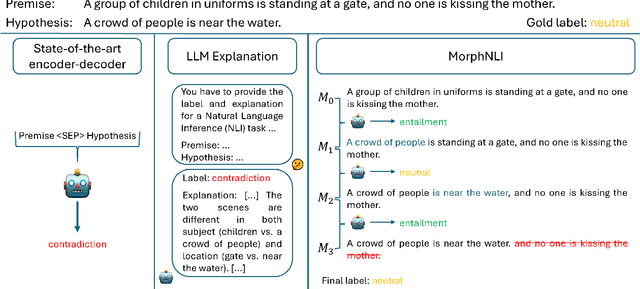

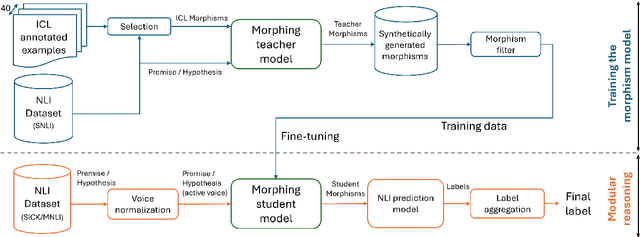

We introduce MorphNLI, a modular step-by-step approach to natural language inference (NLI). When classifying the premise-hypothesis pairs into {entailment, contradiction, neutral}, we use a language model to generate the necessary edits to incrementally transform (i.e., morph) the premise into the hypothesis. Then, using an off-the-shelf NLI model we track how the entailment progresses with these atomic changes, aggregating these intermediate labels into a final output. We demonstrate the advantages of our proposed method particularly in realistic cross-domain settings, where our method always outperforms strong baselines with improvements up to 12.6% (relative). Further, our proposed approach is explainable as the atomic edits can be used to understand the overall NLI label.
CopySpec: Accelerating LLMs with Speculative Copy-and-Paste Without Compromising Quality
Feb 13, 2025We introduce CopySpec, an innovative technique designed to tackle the inefficiencies LLMs face when generating responses that closely resemble previous outputs. CopySpec identifies repeated sequences in the model's chat history and speculates that the same tokens will follow, enabling seamless copying without compromising output quality or requiring additional GPU memory. To evaluate the effectiveness of our approach, we conducted experiments using five LLMs and five datasets: MT-Bench, CNN/DM, GSM-8K, HumanEval, and our newly created dataset, MT-Redundant. MT-Redundant, introduced in this paper, transforms the second turn of MT-Bench into a request for variations of the first turn's answer, simulating real-world scenarios where users request modifications to prior responses. Our results demonstrate significant speed-ups: up to 2.35x on CNN/DM, 3.08x on the second turn of select MT-Redundant categories, and 2.66x on the third turn of GSM-8K's self-correction tasks. Moreover, we show that CopySpec integrates seamlessly with speculative decoding, yielding an average 49% additional speed-up over speculative decoding for the second turn of MT-Redundant across all eight categories. While LLMs, even with speculative decoding, suffer from slower inference as context sizes grow, CopySpec leverages the expanded context to accelerate inference, making it faster as the context size increases. Our code and dataset are publicly available at https://github.com/RazvanDu/CopySpec.
Finding a Wolf in Sheep's Clothing: Combating Adversarial Text-To-Image Prompts with Text Summarization
Dec 15, 2024



Text-to-image models are vulnerable to the stepwise "Divide-and-Conquer Attack" (DACA) that utilize a large language model to obfuscate inappropriate content in prompts by wrapping sensitive text in a benign narrative. To mitigate stepwise DACA attacks, we propose a two-layer method involving text summarization followed by binary classification. We assembled the Adversarial Text-to-Image Prompt (ATTIP) dataset ($N=940$), which contained DACA-obfuscated and non-obfuscated prompts. From the ATTIP dataset, we created two summarized versions: one generated by a small encoder model and the other by a large language model. Then, we used an encoder classifier and a GPT-4o classifier to perform content moderation on the summarized and unsummarized prompts. When compared with a classifier that operated over the unsummarized data, our method improved F1 score performance by 31%. Further, the highest recorded F1 score achieved (98%) was produced by the encoder classifier on a summarized ATTIP variant. This study indicates that pre-classification text summarization can inoculate content detection models against stepwise DACA obfuscations.