 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConciseRL: Conciseness-Guided Reinforcement Learning for Efficient Reasoning Models
May 22, 2025



Large language models excel at complex tasks by breaking down problems into structured reasoning steps. However, reasoning traces often extend beyond reaching a correct answer, causing wasted computation, reduced readability, and hallucinations. To address this, we introduce a novel hyperparameter-free conciseness score used as a reward signal within a reinforcement learning framework to guide models toward generating correct and concise reasoning traces. This score is evaluated by a large language model acting as a judge, enabling dynamic, context-aware feedback beyond simple token length. Our method achieves state-of-the-art efficiency-accuracy trade-offs on the MATH dataset, reducing token usage by up to 31x on simple problems while improving accuracy by 7%, and on the hardest problems, it outperforms full reasoning by +7.5% accuracy with up to 3.6x fewer tokens. On TheoremQA, our method improves accuracy by +2.2% using 12.5x fewer tokens. We also conduct ablation studies on the judge model, reward composition, and problem difficulty, showing that our method dynamically adapts reasoning length based on problem difficulty and benefits significantly from stronger judges. The code, model weights, and datasets are open-sourced at https://github.com/RazvanDu/ConciseRL.
Change Is the Only Constant: Dynamic LLM Slicing based on Layer Redundancy
Nov 05, 2024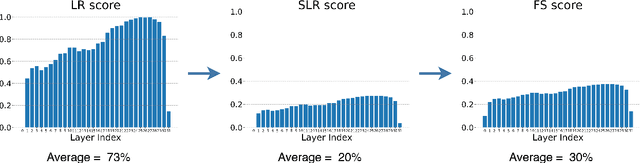
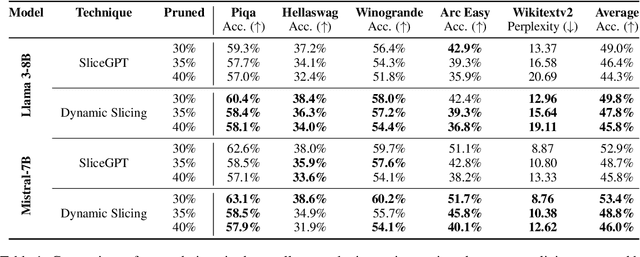
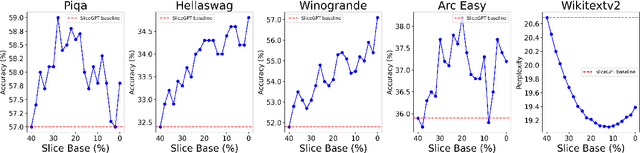
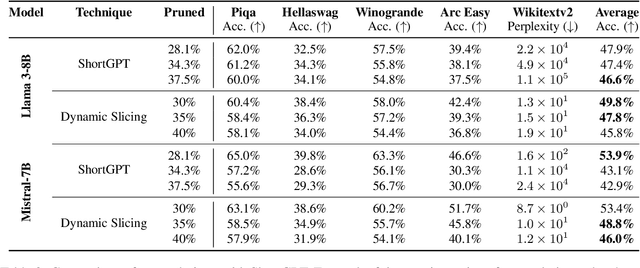
This paper introduces a novel model compression approach through dynamic layer-specific pruning in Large Language Models (LLMs), enhancing the traditional methodology established by SliceGPT. By transitioning from constant to dynamic slicing, our method leverages the newly proposed Layer Redundancy (LR) score, which assesses how much change each layer changes its input by measuring the cosine similarity of the input to the output of the layer. We use this score to prune parts of individual layers based on redundancy in such a way that the average pruned percentage for all layers is a fixed value. We conducted extensive experiments using models like Llama3-8B and Mistral-7B on multiple datasets, evaluating different slicing bases and percentages to determine optimal configurations that balance efficiency and performance. Our findings show that our dynamic slicing approach not only maintains but, in many cases, enhances model performance compared to the baseline established by constant slicing methods. For instance, in several settings, we see performance improvements of up to 5% over the SliceGPT baseline. Additionally, a perplexity decrease by as much as 7% was observed across multiple benchmarks, validating the effectiveness of our method. The code, model weights, and datasets are open-sourced at https://github.com/RazvanDu/DynamicSlicing.
Enhancing Transformer RNNs with Multiple Temporal Perspectives
Feb 04, 2024We introduce the concept of multiple temporal perspectives, a novel approach applicable to Recurrent Neural Network (RNN) architectures for enhancing their understanding of sequential data. This method involves maintaining diverse temporal views of previously encountered text, significantly enriching the language models' capacity to interpret context. To show the efficacy of this approach, we incorporate it into the Receptance Weighted Key Value (RWKV) architecture, addressing its inherent challenge of retaining all historical information within a single hidden state. Notably, this improvement is achieved with a minimal increase in the number of parameters --even as little as $0.04\%$ of the original number of parameters. Further, the additional parameters necessary for the multiple temporal perspectives are fine-tuned with minimal computational overhead, avoiding the need for a full pre-training. The resulting model maintains linear computational complexity during prompt inference, ensuring consistent efficiency across various sequence lengths. The empirical results and ablation studies included in our research validate the effectiveness of our approach, showcasing improved performance across multiple benchmarks. The code, model weights and datasets are open-sourced at: https://github.com/RazvanDu/TemporalRNNs.
Using DUCK-Net for Polyp Image Segmentation
Nov 03, 2023This paper presents a novel supervised convolutional neural network architecture, "DUCK-Net", capable of effectively learning and generalizing from small amounts of medical images to perform accurate segmentation tasks. Our model utilizes an encoder-decoder structure with a residual downsampling mechanism and a custom convolutional block to capture and process image information at multiple resolutions in the encoder segment. We employ data augmentation techniques to enrich the training set, thus increasing our model's performance. While our architecture is versatile and applicable to various segmentation tasks, in this study, we demonstrate its capabilities specifically for polyp segmentation in colonoscopy images. We evaluate the performance of our method on several popular benchmark datasets for polyp segmentation, Kvasir-SEG, CVC-ClinicDB, CVC-ColonDB, and ETIS-LARIBPOLYPDB showing that it achieves state-of-the-art results in terms of mean Dice coefficient, Jaccard index, Precision, Recall, and Accuracy. Our approach demonstrates strong generalization capabilities, achieving excellent performance even with limited training data. The code is publicly available on GitHub: https://github.com/RazvanDu/DUCK-Net