 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASA: Training-Free Representation Engineering for Tool-Calling Agents
Feb 08, 2026Adapting LLM agents to domain-specific tool calling remains notably brittle under evolving interfaces. Prompt and schema engineering is easy to deploy but often fragile under distribution shift and strict parsers, while continual parameter-efficient fine-tuning improves reliability at the cost of training, maintenance, and potential forgetting. We identify a critical Lazy Agent failure mode where tool necessity is nearly perfectly decodable from mid-layer activations, yet the model remains conservative in entering tool mode, revealing a representation-behavior gap. We propose Activation Steering Adapter (ASA), a training-free, inference-time controller that performs a single-shot mid-layer intervention and targets tool domains via a router-conditioned mixture of steering vectors with a probe-guided signed gate to amplify true intent while suppressing spurious triggers. On MTU-Bench with Qwen2.5-1.5B, ASA improves strict tool-use F1 from 0.18 to 0.50 while reducing the false positive rate from 0.15 to 0.05, using only about 20KB of portable assets and no weight updates.
ASA: Activation Steering for Tool-Calling Domain Adaptation
Feb 04, 2026For real-world deployment of general-purpose LLM agents, the core challenge is often not tool use itself, but efficient domain adaptation under rapidly evolving toolsets, APIs, and protocols. Repeated LoRA or SFT across domains incurs exponentially growing training and maintenance costs, while prompt or schema methods are brittle under distribution shift and complex interfaces. We propose \textbf{Activation Steering Adapter (ASA}), a lightweight, inference-time, training-free mechanism that reads routing signals from intermediate activations and uses an ultra-light router to produce adaptive control strengths for precise domain alignment. Across multiple model scales and domains, ASA achieves LoRA-comparable adaptation with substantially lower overhead and strong cross-model transferability, making it ideally practical for robust, scalable, and efficient multi-domain tool ecosystems with frequent interface churn dynamics.
Do Latent-CoT Models Think Step-by-Step? A Mechanistic Study on Sequential Reasoning Tasks
Jan 31, 2026Latent Chain-of-Thought (Latent-CoT) aims to enable step-by-step computation without emitting long rationales, yet its mechanisms remain unclear. We study CODI, a continuous-thought teacher-student distillation model, on strictly sequential polynomial-iteration tasks. Using logit-lens decoding, linear probes, attention analysis, and activation patching, we localize intermediate-state representations and trace their routing to the final readout. On two- and three-hop tasks, CODI forms the full set of bridge states that become decodable across latent-thought positions, while the final input follows a separate near-direct route; predictions arise via late fusion at the end-of-thought boundary. For longer hop lengths, CODI does not reliably execute a full latent rollout, instead exhibiting a partial latent reasoning path that concentrates on late intermediates and fuses them with the last input at the answer readout position. Ablations show that this partial pathway can collapse under regime shifts, including harder optimization. Overall, we delineate when CODI-style latent-CoT yields faithful iterative computation versus compressed or shortcut strategies, and highlight challenges in designing robust latent-CoT objectives for sequential reasoning.
Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units
Jan 29, 2026While Mechanistic Interpretability has identified interpretable circuits in LLMs, their causal origins in training data remain elusive. We introduce Mechanistic Data Attribution (MDA), a scalable framework that employs Influence Functions to trace interpretable units back to specific training samples. Through extensive experiments on the Pythia family, we causally validate that targeted intervention--removing or augmenting a small fraction of high-influence samples--significantly modulates the emergence of interpretable heads, whereas random interventions show no effect. Our analysis reveals that repetitive structural data (e.g., LaTeX, XML) acts as a mechanistic catalyst. Furthermore, we observe that interventions targeting induction head formation induce a concurrent change in the model's in-context learning (ICL) capability. This provides direct causal evidence for the long-standing hypothesis regarding the functional link between induction heads and ICL. Finally, we propose a mechanistic data augmentation pipeline that consistently accelerates circuit convergence across model scales, providing a principled methodology for steering the developmental trajectories of LLMs.
Epistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Towards a Mechanistic Understanding of Propositional Logical Reasoning in Large Language Models
Jan 07, 2026Understanding how Large Language Models (LLMs) perform logical reasoning internally remains a fundamental challenge. While prior mechanistic studies focus on identifying taskspecific circuits, they leave open the question of what computational strategies LLMs employ for propositional reasoning. We address this gap through comprehensive analysis of Qwen3 (8B and 14B) on PropLogic-MI, a controlled dataset spanning 11 propositional logic rule categories across one-hop and two-hop reasoning. Rather than asking ''which components are necessary,'' we ask ''how does the model organize computation?'' Our analysis reveals a coherent computational architecture comprising four interlocking mechanisms: Staged Computation (layer-wise processing phases), Information Transmission (information flow aggregation at boundary tokens), Fact Retrospection (persistent re-access of source facts), and Specialized Attention Heads (functionally distinct head types). These mechanisms generalize across model scales, rule types, and reasoning depths, providing mechanistic evidence that LLMs employ structured computational strategies for logical reasoning.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.
How does Transformer Learn Implicit Reasoning?
May 29, 2025

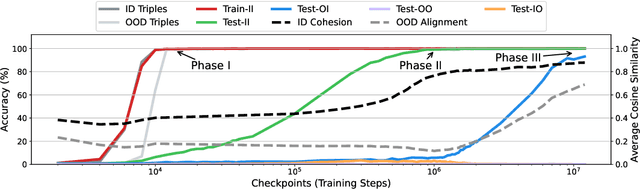

Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly -- producing correct answers without explicitly verbalizing intermediate steps -- but the underlying mechanisms remain poorly understood. In this paper, we study how such implicit reasoning emerges by training transformers from scratch in a controlled symbolic environment. Our analysis reveals a three-stage developmental trajectory: early memorization, followed by in-distribution generalization, and eventually cross-distribution generalization. We find that training with atomic triples is not necessary but accelerates learning, and that second-hop generalization relies on query-level exposure to specific compositional structures. To interpret these behaviors, we introduce two diagnostic tools: cross-query semantic patching, which identifies semantically reusable intermediate representations, and a cosine-based representational lens, which reveals that successful reasoning correlates with the cosine-base clustering in hidden space. This clustering phenomenon in turn provides a coherent explanation for the behavioral dynamics observed across training, linking representational structure to reasoning capability. These findings provide new insights into the interpretability of implicit multi-hop reasoning in LLMs, helping to clarify how complex reasoning processes unfold internally and offering pathways to enhance the transparency of such models.
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark
May 24, 2025We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models' (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
ConciseRL: Conciseness-Guided Reinforcement Learning for Efficient Reasoning Models
May 22, 2025



Large language models excel at complex tasks by breaking down problems into structured reasoning steps. However, reasoning traces often extend beyond reaching a correct answer, causing wasted computation, reduced readability, and hallucinations. To address this, we introduce a novel hyperparameter-free conciseness score used as a reward signal within a reinforcement learning framework to guide models toward generating correct and concise reasoning traces. This score is evaluated by a large language model acting as a judge, enabling dynamic, context-aware feedback beyond simple token length. Our method achieves state-of-the-art efficiency-accuracy trade-offs on the MATH dataset, reducing token usage by up to 31x on simple problems while improving accuracy by 7%, and on the hardest problems, it outperforms full reasoning by +7.5% accuracy with up to 3.6x fewer tokens. On TheoremQA, our method improves accuracy by +2.2% using 12.5x fewer tokens. We also conduct ablation studies on the judge model, reward composition, and problem difficulty, showing that our method dynamically adapts reasoning length based on problem difficulty and benefits significantly from stronger judges. The code, model weights, and datasets are open-sourced at https://github.com/RazvanDu/ConciseRL.