 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTMMBench: Benchmarking Temporal-Aware Multi-Modal RAG in Finance
Mar 07, 2025



Finance decision-making often relies on in-depth data analysis across various data sources, including financial tables, news articles, stock prices, etc. In this work, we introduce FinTMMBench, the first comprehensive benchmark for evaluating temporal-aware multi-modal Retrieval-Augmented Generation (RAG) systems in finance. Built from heterologous data of NASDAQ 100 companies, FinTMMBench offers three significant advantages. 1) Multi-modal Corpus: It encompasses a hybrid of financial tables, news articles, daily stock prices, and visual technical charts as the corpus. 2) Temporal-aware Questions: Each question requires the retrieval and interpretation of its relevant data over a specific time period, including daily, weekly, monthly, quarterly, and annual periods. 3) Diverse Financial Analysis Tasks: The questions involve 10 different tasks, including information extraction, trend analysis, sentiment analysis and event detection, etc. We further propose a novel TMMHybridRAG method, which first leverages LLMs to convert data from other modalities (e.g., tabular, visual and time-series data) into textual format and then incorporates temporal information in each node when constructing graphs and dense indexes. Its effectiveness has been validated in extensive experiments, but notable gaps remain, highlighting the challenges presented by our FinTMMBench.
MMDocBench: Benchmarking Large Vision-Language Models for Fine-Grained Visual Document Understanding
Oct 25, 2024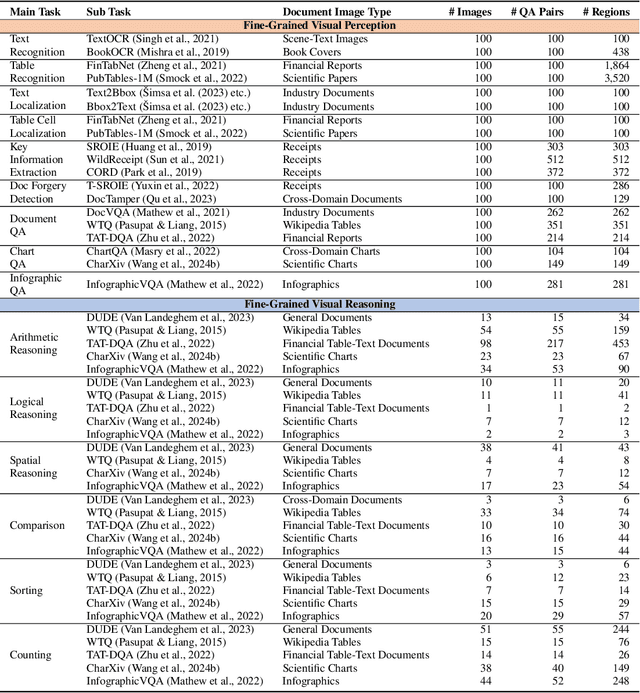

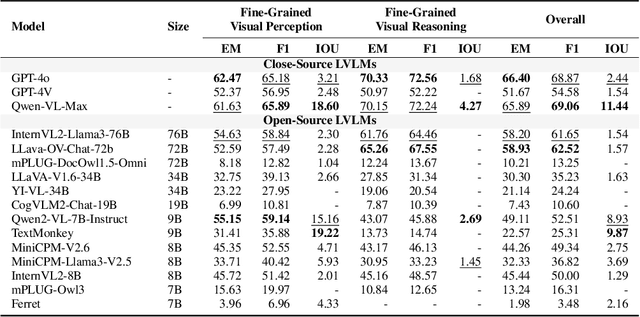
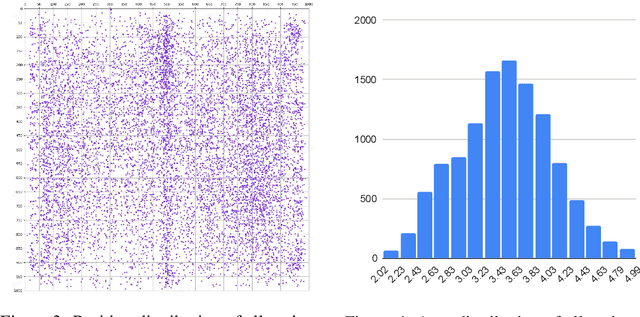
Large Vision-Language Models (LVLMs) have achieved remarkable performance in many vision-language tasks, yet their capabilities in fine-grained visual understanding remain insufficiently evaluated. Existing benchmarks either contain limited fine-grained evaluation samples that are mixed with other data, or are confined to object-level assessments in natural images. To holistically assess LVLMs' fine-grained visual understanding capabilities, we propose using document images with multi-granularity and multi-modal information to supplement natural images. In this light, we construct MMDocBench, a benchmark with various OCR-free document understanding tasks for the evaluation of fine-grained visual perception and reasoning abilities. MMDocBench defines 15 main tasks with 4,338 QA pairs and 11,353 supporting regions, covering various document images such as research papers, receipts, financial reports, Wikipedia tables, charts, and infographics. Based on MMDocBench, we conduct extensive experiments using 13 open-source and 3 proprietary advanced LVLMs, assessing their strengths and weaknesses across different tasks and document image types. The benchmark, task instructions, and evaluation code will be made publicly available.
Modeling Voting for System Combination in Machine Translation
Jul 14, 2020
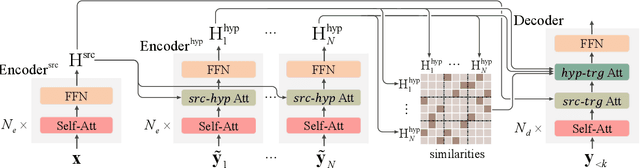
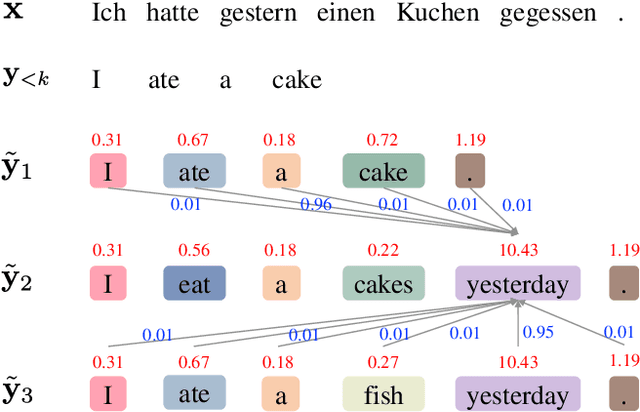
System combination is an important technique for combining the hypotheses of different machine translation systems to improve translation performance. Although early statistical approaches to system combination have been proven effective in analyzing the consensus between hypotheses, they suffer from the error propagation problem due to the use of pipelines. While this problem has been alleviated by end-to-end training of multi-source sequence-to-sequence models recently, these neural models do not explicitly analyze the relations between hypotheses and fail to capture their agreement because the attention to a word in a hypothesis is calculated independently, ignoring the fact that the word might occur in multiple hypotheses. In this work, we propose an approach to modeling voting for system combination in machine translation. The basic idea is to enable words in hypotheses from different systems to vote on words that are representative and should get involved in the generation process. This can be done by quantifying the influence of each voter and its preference for each candidate. Our approach combines the advantages of statistical and neural methods since it can not only analyze the relations between hypotheses but also allow for end-to-end training. Experiments show that our approach is capable of better taking advantage of the consensus between hypotheses and achieves significant improvements over state-of-the-art baselines on Chinese-English and English-German machine translation tasks.
Graph Random Neural Network
May 22, 2020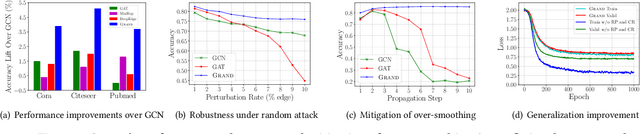
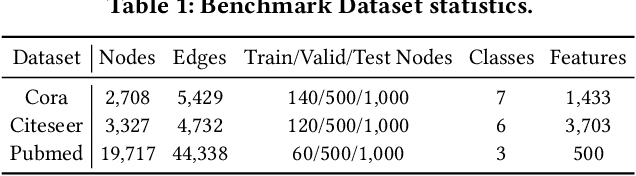
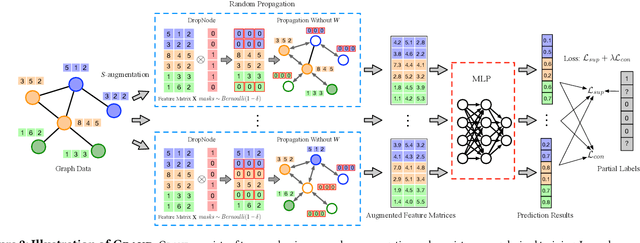
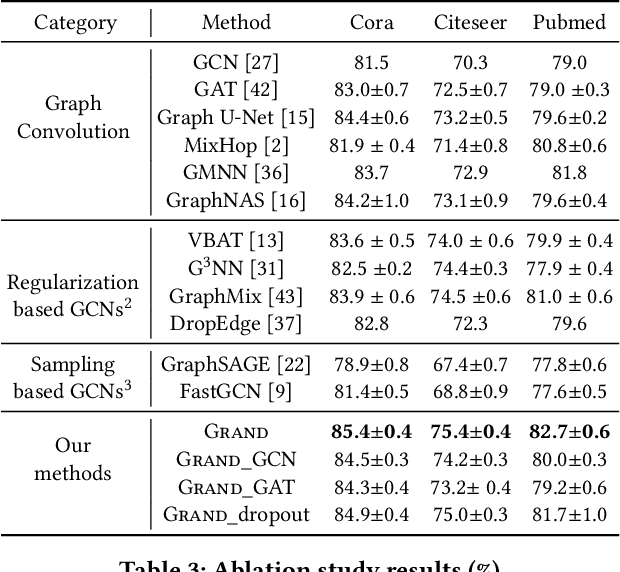
Graph neural networks (GNNs) have generalized deep learning methods into graph-structured data with promising performance on graph mining tasks. However, existing GNNs often meet complex graph structures with scarce labeled nodes and suffer from the limitations of non-robustness, over-smoothing, and overfitting. To address these issues, we propose a simple yet effective GNN framework---Graph Random Neural Network (Grand). Different from the deterministic propagation in existing GNNs, Grand adopts a random propagation strategy to enhance model robustness. This strategy also naturally enables Grand to decouple the propagation from feature transformation, reducing the risks of over-smoothing and overfitting. Moreover, random propagation acts as an efficient method for graph data augmentation. Based on this, we propose the consistency regularization for Grand by leveraging the distributional consistency of unlabeled nodes in multiple augmentations, improving the generalization capacity of the model. Extensive experiments on graph benchmark datasets suggest that Grand significantly outperforms state-of-the-art GNN baselines on semi-supervised graph learning tasks. Finally, we show that Grand mitigates the issues of over-smoothing and overfitting, and its performance is married with robustness.
Learning to Predict Explainable Plots for Neural Story Generation
Dec 06, 2019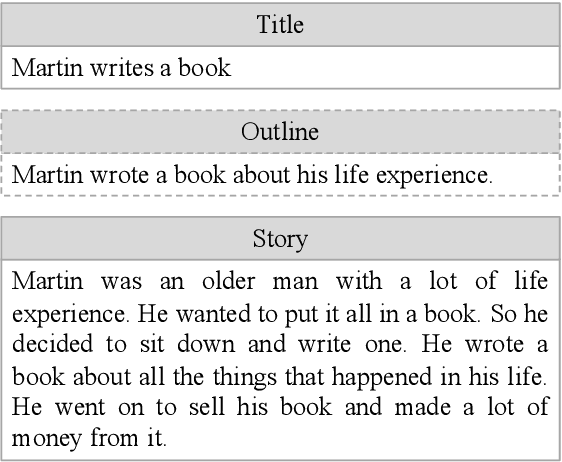
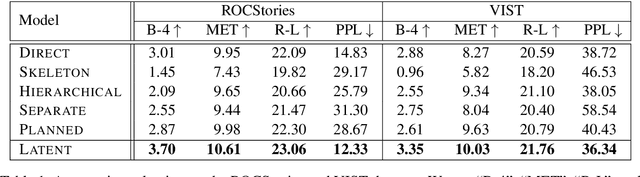
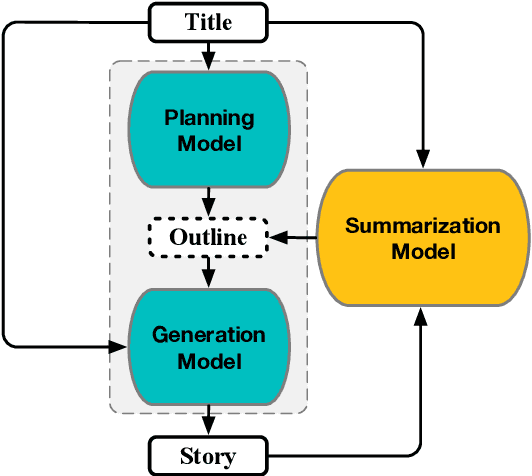
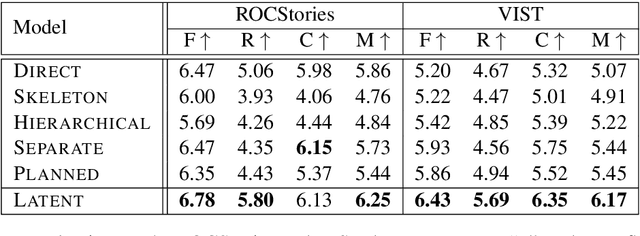
Story generation is an important natural language processing task that aims to generate coherent stories automatically. While the use of neural networks has proven effective in improving story generation, how to learn to generate an explainable high-level plot still remains a major challenge. In this work, we propose a latent variable model for neural story generation. The model treats an outline, which is a natural language sentence explainable to humans, as a latent variable to represent a high-level plot that bridges the input and output. We adopt an external summarization model to guide the latent variable model to learn how to generate outlines from training data. Experiments show that our approach achieves significant improvements over state-of-the-art methods in both automatic and human evaluations.
Neural Machine Translation with Explicit Phrase Alignment
Nov 28, 2019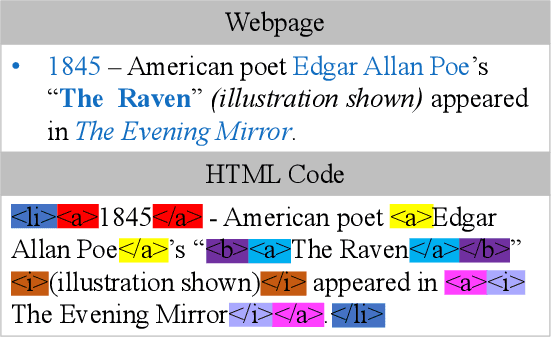
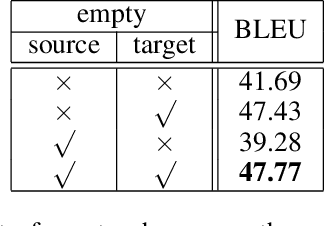

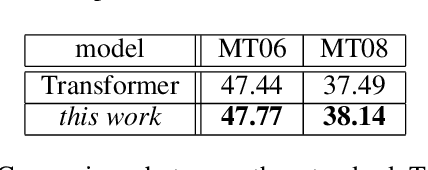
While neural machine translation (NMT) has achieved state-of-the-art translation performance, it is unable to capture the alignment between the input and output during the translation process. The lack of alignment in NMT models leads to three problems: it is hard to (1) interpret the translation process, (2) impose lexical constraints, and (3) impose structural constraints. To alleviate these problems, we propose to introduce explicit phrase alignment into the translation process of arbitrary NMT models. The key idea is to build a search space similar to that of phrase-based statistical machine translation for NMT where phrase alignment is readily available. We design a new decoding algorithm that can easily impose lexical and structural constraints. Experiments show that our approach makes the translation process of NMT more interpretable without sacrificing translation quality. In addition, our approach achieves significant improvements in lexically and structurally constrained translation tasks.
Learning to Copy for Automatic Post-Editing
Nov 09, 2019
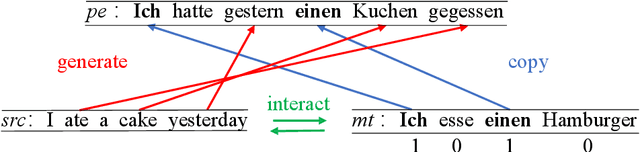
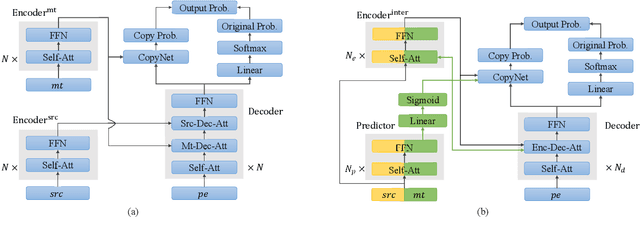
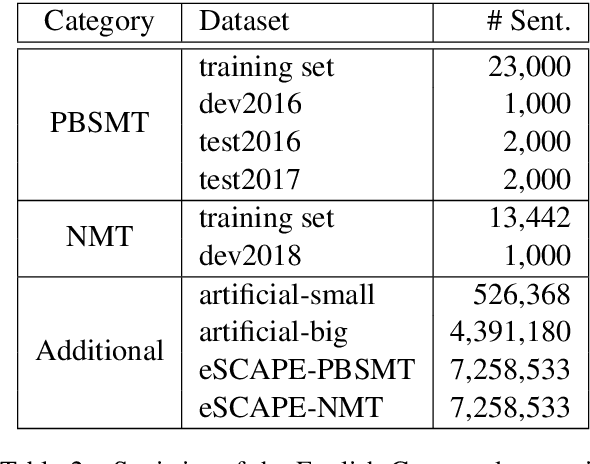
Automatic post-editing (APE), which aims to correct errors in the output of machine translation systems in a post-processing step, is an important task in natural language processing. While recent work has achieved considerable performance gains by using neural networks, how to model the copying mechanism for APE remains a challenge. In this work, we propose a new method for modeling copying for APE. To better identify translation errors, our method learns the representations of source sentences and system outputs in an interactive way. These representations are used to explicitly indicate which words in the system outputs should be copied, which is useful to help CopyNet (Gu et al., 2016) better generate post-edited translations. Experiments on the datasets of the WMT 2016-2017 APE shared tasks show that our approach outperforms all best published results.
Improving Back-Translation with Uncertainty-based Confidence Estimation
Aug 31, 2019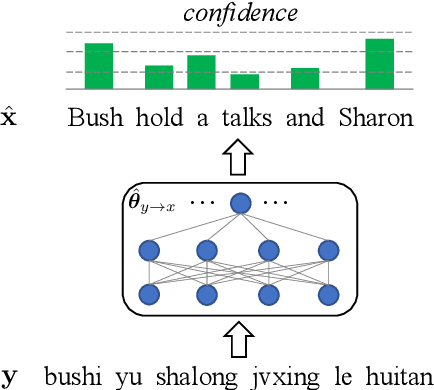
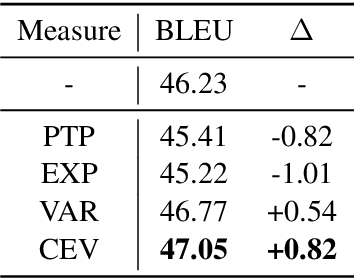
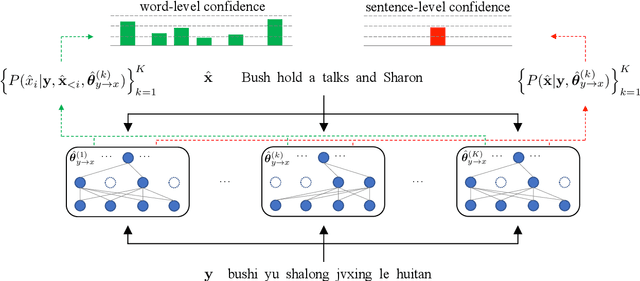
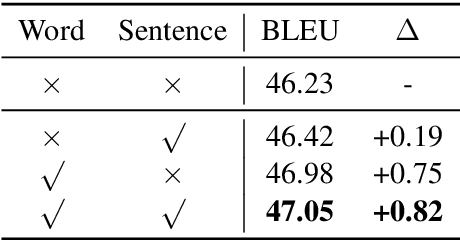
While back-translation is simple and effective in exploiting abundant monolingual corpora to improve low-resource neural machine translation (NMT), the synthetic bilingual corpora generated by NMT models trained on limited authentic bilingual data are inevitably noisy. In this work, we propose to quantify the confidence of NMT model predictions based on model uncertainty. With word- and sentence-level confidence measures based on uncertainty, it is possible for back-translation to better cope with noise in synthetic bilingual corpora. Experiments on Chinese-English and English-German translation tasks show that uncertainty-based confidence estimation significantly improves the performance of back-translation.
Prior Knowledge Integration for Neural Machine Translation using Posterior Regularization
Nov 02, 2018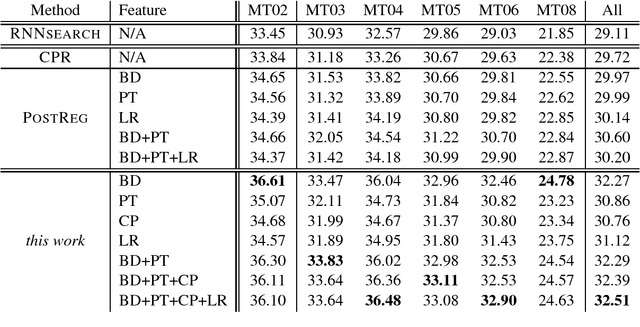
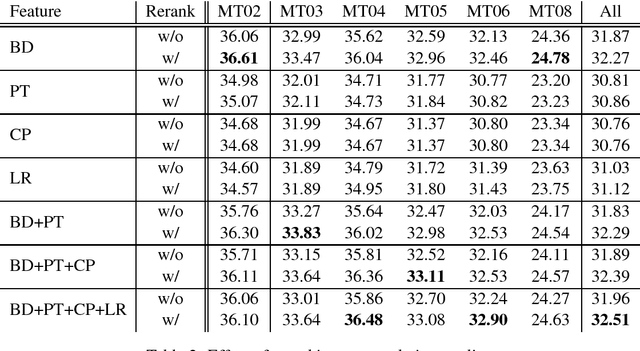
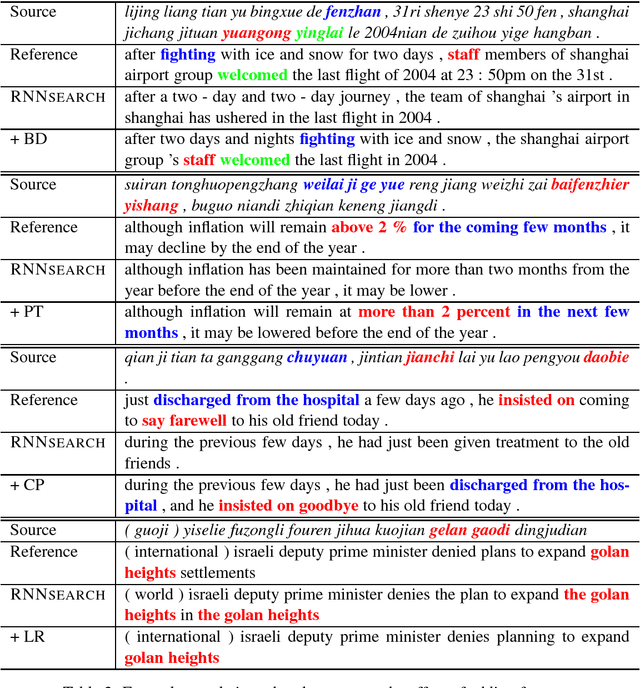
Although neural machine translation has made significant progress recently, how to integrate multiple overlapping, arbitrary prior knowledge sources remains a challenge. In this work, we propose to use posterior regularization to provide a general framework for integrating prior knowledge into neural machine translation. We represent prior knowledge sources as features in a log-linear model, which guides the learning process of the neural translation model. Experiments on Chinese-English translation show that our approach leads to significant improvements.
Improving the Transformer Translation Model with Document-Level Context
Oct 08, 2018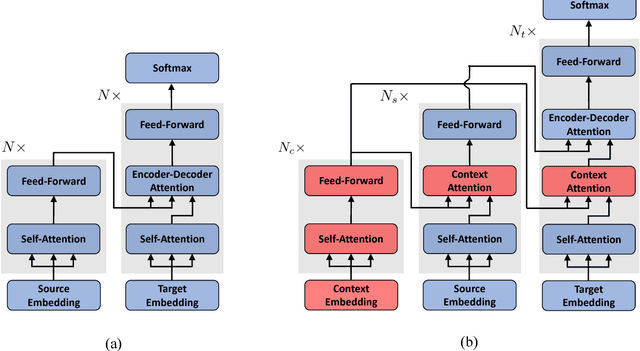


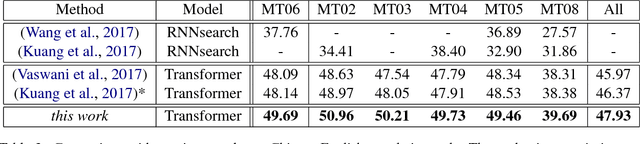
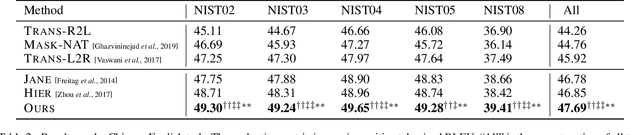
Although the Transformer translation model (Vaswani et al., 2017) has achieved state-of-the-art performance in a variety of translation tasks, how to use document-level context to deal with discourse phenomena problematic for Transformer still remains a challenge. In this work, we extend the Transformer model with a new context encoder to represent document-level context, which is then incorporated into the original encoder and decoder. As large-scale document-level parallel corpora are usually not available, we introduce a two-step training method to take full advantage of abundant sentence-level parallel corpora and limited document-level parallel corpora. Experiments on the NIST Chinese-English datasets and the IWSLT French-English datasets show that our approach improves over Transformer significantly.