 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRIT: Adapting Vision Foundation Models for Unified Single- and Multi-Frame Infrared Small Target Detection
Feb 02, 2026Infrared small target detection (IRSTD) is crucial for surveillance and early-warning, with deployments spanning both single-frame analysis and video-mode tracking. A practical solution should leverage vision foundation models (VFMs) to mitigate infrared data scarcity, while adopting a memory-attention-based temporal propagation framework that unifies single- and multi-frame inference. However, infrared small targets exhibit weak radiometric signals and limited semantic cues, which differ markedly from visible-spectrum imagery. This modality gap makes direct use of semantics-oriented VFMs and appearance-driven cross-frame association unreliable for IRSTD: hierarchical feature aggregation can submerge localized target peaks, and appearance-only memory attention becomes ambiguous, leading to spurious clutter associations. To address these challenges, we propose SPIRIT, a unified and VFM-compatible framework that adapts VFMs to IRSTD via lightweight physics-informed plug-ins. Spatially, PIFR refines features by approximating rank-sparsity decomposition to suppress structured background components and enhance sparse target-like signals. Temporally, PGMA injects history-derived soft spatial priors into memory cross-attention to constrain cross-frame association, enabling robust video detection while naturally reverting to single-frame inference when temporal context is absent. Experiments on multiple IRSTD benchmarks show consistent gains over VFM-based baselines and SOTA performance.
SATMapTR: Satellite Image Enhanced Online HD Map Construction
Dec 12, 2025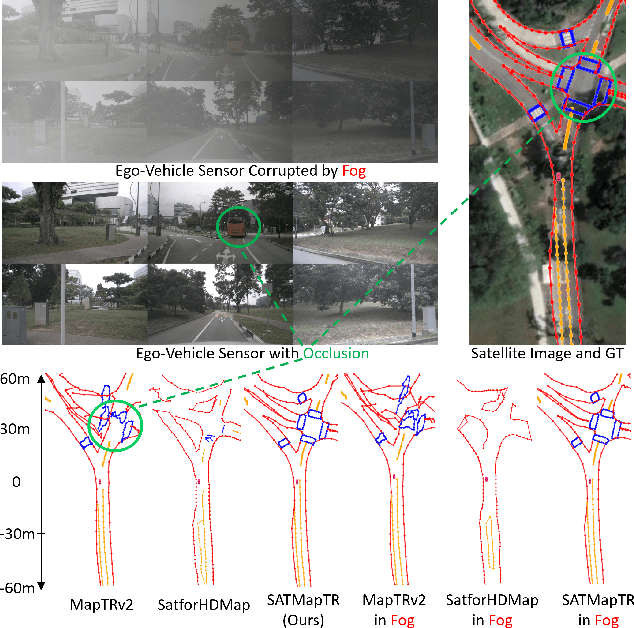
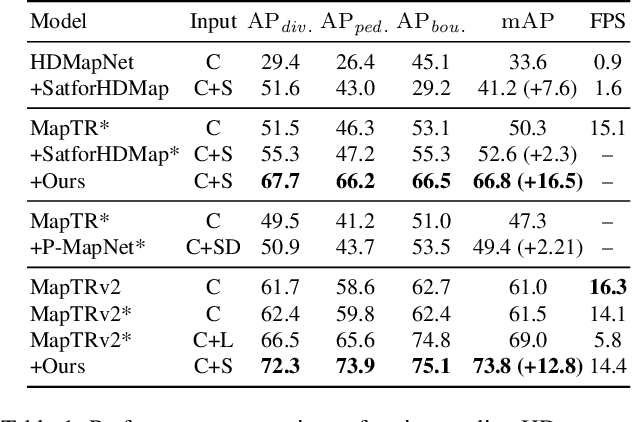
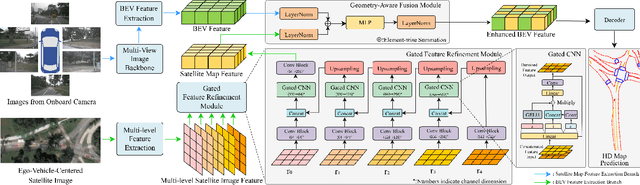
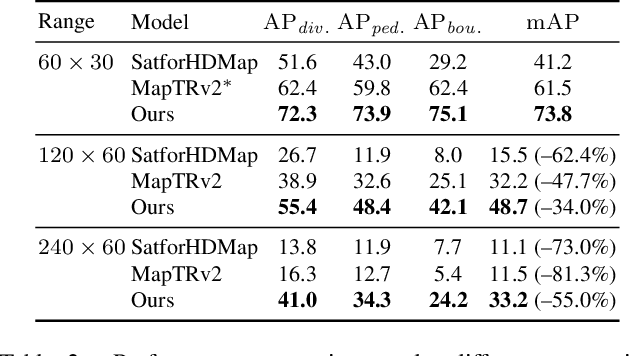
High-definition (HD) maps are evolving from pre-annotated to real-time construction to better support autonomous driving in diverse scenarios. However, this process is hindered by low-quality input data caused by onboard sensors limited capability and frequent occlusions, leading to incomplete, noisy, or missing data, and thus reduced mapping accuracy and robustness. Recent efforts have introduced satellite images as auxiliary input, offering a stable, wide-area view to complement the limited ego perspective. However, satellite images in Bird's Eye View are often degraded by shadows and occlusions from vegetation and buildings. Prior methods using basic feature extraction and fusion remain ineffective. To address these challenges, we propose SATMapTR, a novel online map construction model that effectively fuses satellite image through two key components: (1) a gated feature refinement module that adaptively filters satellite image features by integrating high-level semantics with low-level structural cues to extract high signal-to-noise ratio map-relevant representations; and (2) a geometry-aware fusion module that consistently fuse satellite and BEV features at a grid-to-grid level, minimizing interference from irrelevant regions and low-quality inputs. Experimental results on the nuScenes dataset show that SATMapTR achieves the highest mean average precision (mAP) of 73.8, outperforming state-of-the-art satellite-enhanced models by up to 14.2 mAP. It also shows lower mAP degradation under adverse weather and sensor failures, and achieves nearly 3 times higher mAP at extended perception ranges.
SynapseRoute: An Auto-Route Switching Framework on Dual-State Large Language Model
Jul 03, 2025With the widespread adoption of large language models (LLMs) in practical applications, selecting an appropriate model requires balancing not only performance but also operational cost. The emergence of reasoning-capable models has further widened the cost gap between "thinking" (high reasoning) and "non-thinking" (fast, low-cost) modes. In this work, we reveal that approximately 58% of medical questions can be accurately answered by the non-thinking mode alone, without requiring the high-cost reasoning process. This highlights a clear dichotomy in problem complexity and suggests that dynamically routing queries to the appropriate mode based on complexity could optimize accuracy, cost-efficiency, and overall user experience. Based on this, we further propose SynapseRoute, a machine learning-based dynamic routing framework that intelligently assigns input queries to either thinking or non-thinking modes. Experimental results on several medical datasets demonstrate that SynapseRoute not only improves overall accuracy (0.8390 vs. 0.8272) compared to the thinking mode alone but also reduces inference time by 36.8% and token consumption by 39.66%. Importantly, qualitative analysis indicates that over-reasoning on simpler queries can lead to unnecessary delays and even decreased accuracy, a pitfall avoided by our adaptive routing. Finally, this work further introduces the Accuracy-Inference-Token (AIT) index to comprehensively evaluate the trade-offs among accuracy, latency, and token cost.
Enhancing Trust Management System for Connected Autonomous Vehicles Using Machine Learning Methods: A Survey
May 10, 2025Connected Autonomous Vehicles (CAVs) operate in dynamic, open, and multi-domain networks, rendering them vulnerable to various threats. Trust Management Systems (TMS) systematically organize essential steps in the trust mechanism, identifying malicious nodes against internal threats and external threats, as well as ensuring reliable decision-making for more cooperative tasks. Recent advances in machine learning (ML) offer significant potential to enhance TMS, especially for the strict requirements of CAVs, such as CAV nodes moving at varying speeds, and opportunistic and intermittent network behavior. Those features distinguish ML-based TMS from social networks, static IoT, and Social IoT. This survey proposes a novel three-layer ML-based TMS framework for CAVs in the vehicle-road-cloud integration system, i.e., trust data layer, trust calculation layer and trust incentive layer. A six-dimensional taxonomy of objectives is proposed. Furthermore, the principles of ML methods for each module in each layer are analyzed. Then, recent studies are categorized based on traffic scenarios that are against the proposed objectives. Finally, future directions are suggested, addressing the open issues and meeting the research trend. We maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/octoberzzzzz/ML-based-TMS-CAV-Survey.
Aerial Active STAR-RIS-Aided IoT NOMA Networks
Jan 05, 2025



A novel framework of the unmanned aerial vehicle (UAV)-mounted active simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) communications with the non-orthogonal multiple access (NOMA) is proposed for Internet-of-Things (IoT) networks. In particular, an active STAR-RIS is deployed onboard to enhance the communication link between the base station (BS) and the IoT devices, and NOMA is utilized for supporting the multi-device connectivity. Based on the proposed framework, a system sum rate maximization problem is formulated for the joint optimization of the active STAR-RIS beamforming, the UAV trajectory design, and the power allocation. To solve the non-convex problem with highly-coupled variables, an alternating optimization (AO) algorithm is proposed to decouple the original problem into three subproblems. Specifically, for the active STAR-RIS beamforming, the amplification coefficient, the power-splitting ratio, and the phase shift are incorporated into a combined variable to simplify the optimization process. Afterwards, the penalty-based method is invoked for handling the non-convex rank-one constraint. For the UAV trajectory design and the power allocation subproblems, the successive convex optimization method is applied for iteratively approximating the local-optimal solution. Numerical results demonstrate that: 1) the proposed algorithm achieves superior performance compared to the benchmarks in terms of the sum rate; and 2) the UAV-mounted active STAR-RIS can effectively enhance the channel gain from the BS to the IoT devices by the high-quality channel construction and the power compensation.
CCTNet: A Circular Convolutional Transformer Network for LiDAR-based Place Recognition Handling Movable Objects Occlusion
May 17, 2024



Place recognition is a fundamental task for robotic application, allowing robots to perform loop closure detection within simultaneous localization and mapping (SLAM), and achieve relocalization on prior maps. Current range image-based networks use single-column convolution to maintain feature invariance to shifts in image columns caused by LiDAR viewpoint change.However, this raises the issues such as "restricted receptive fields" and "excessive focus on local regions", degrading the performance of networks. To address the aforementioned issues, we propose a lightweight circular convolutional Transformer network denoted as CCTNet, which boosts performance by capturing structural information in point clouds and facilitating crossdimensional interaction of spatial and channel information. Initially, a Circular Convolution Module (CCM) is introduced, expanding the network's perceptual field while maintaining feature consistency across varying LiDAR perspectives. Then, a Range Transformer Module (RTM) is proposed, which enhances place recognition accuracy in scenarios with movable objects by employing a combination of channel and spatial attention mechanisms. Furthermore, we propose an Overlap-based loss function, transforming the place recognition task from a binary loop closure classification into a regression problem linked to the overlap between LiDAR frames. Through extensive experiments on the KITTI and Ford Campus datasets, CCTNet surpasses comparable methods, achieving Recall@1 of 0.924 and 0.965, and Recall@1% of 0.990 and 0.993 on the test set, showcasing a superior performance. Results on the selfcollected dataset further demonstrate the proposed method's potential for practical implementation in complex scenarios to handle movable objects, showing improved generalization in various datasets.
An Alternative Method to Identify the Susceptibility Threshold Level of Device under Test in a Reverberation Chamber
Apr 23, 2024



By counting the number of pass/fail occurrences of a DUT (Device under Test) in the stirring process in a reverberation chamber (RC), the threshold electric field (E-field) level can be well estimated without tuning the input power and repeating the whole testing many times. The Monte-Carlo method is used to verify the results. Estimated values and uncertainties are given for Rayleigh distributed fields and for Rice distributed fields with different K-factors.
Fusion of Infrared and Visible Images based on Spatial-Channel Attentional Mechanism
Aug 25, 2023In the study, we present AMFusionNet, an innovative approach to infrared and visible image fusion (IVIF), harnessing the power of multiple kernel sizes and attention mechanisms. By assimilating thermal details from infrared images with texture features from visible sources, our method produces images enriched with comprehensive information. Distinct from prevailing deep learning methodologies, our model encompasses a fusion mechanism powered by multiple convolutional kernels, facilitating the robust capture of a wide feature spectrum. Notably, we incorporate parallel attention mechanisms to emphasize and retain pivotal target details in the resultant images. Moreover, the integration of the multi-scale structural similarity (MS-SSIM) loss function refines network training, optimizing the model for IVIF task. Experimental results demonstrate that our method outperforms state-of-the-art algorithms in terms of quality and quantity. The performance metrics on publicly available datasets also show significant improvement
Uncertainty-Encoded Multi-Modal Fusion for Robust Object Detection in Autonomous Driving
Jul 30, 2023
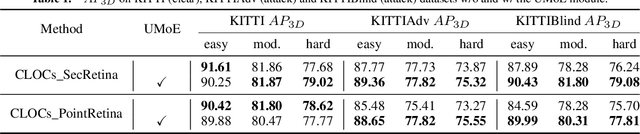

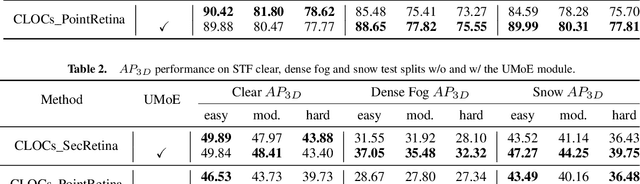
Multi-modal fusion has shown initial promising results for object detection of autonomous driving perception. However, many existing fusion schemes do not consider the quality of each fusion input and may suffer from adverse conditions on one or more sensors. While predictive uncertainty has been applied to characterize single-modal object detection performance at run time, incorporating uncertainties into the multi-modal fusion still lacks effective solutions due primarily to the uncertainty's cross-modal incomparability and distinct sensitivities to various adverse conditions. To fill this gap, this paper proposes Uncertainty-Encoded Mixture-of-Experts (UMoE) that explicitly incorporates single-modal uncertainties into LiDAR-camera fusion. UMoE uses individual expert network to process each sensor's detection result together with encoded uncertainty. Then, the expert networks' outputs are analyzed by a gating network to determine the fusion weights. The proposed UMoE module can be integrated into any proposal fusion pipeline. Evaluation shows that UMoE achieves a maximum of 10.67%, 3.17%, and 5.40% performance gain compared with the state-of-the-art proposal-level multi-modal object detectors under extreme weather, adversarial, and blinding attack scenarios.
Neural Architecture Search for Intel Movidius VPU
May 05, 2023


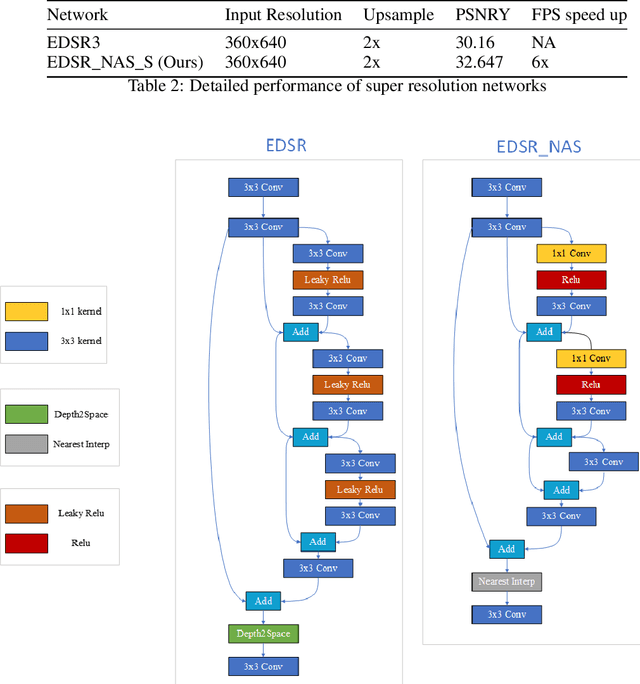
Hardware-aware Neural Architecture Search (NAS) technologies have been proposed to automate and speed up model design to meet both quality and inference efficiency requirements on a given hardware. Prior arts have shown the capability of NAS on hardware specific network design. In this whitepaper, we further extend the use of NAS to Intel Movidius VPU (Vision Processor Units). To determine the hardware-cost to be incorporated into the NAS process, we introduced two methods: pre-collected hardware-cost on device and device-specific hardware-cost model VPUNN. With the help of NAS, for classification task on VPU, we can achieve 1.3x fps acceleration over Mobilenet-v2-1.4 and 2.2x acceleration over Resnet50 with the same accuracy score. For super resolution task on VPU, we can achieve 1.08x PSNR and 6x higher fps compared with EDSR3.