 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025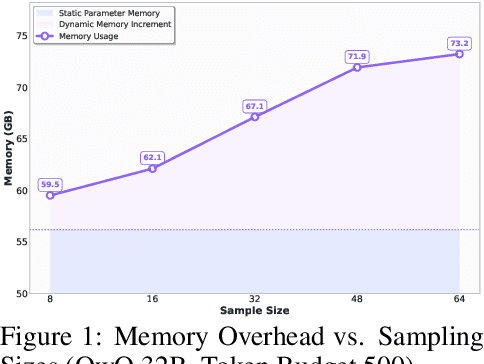
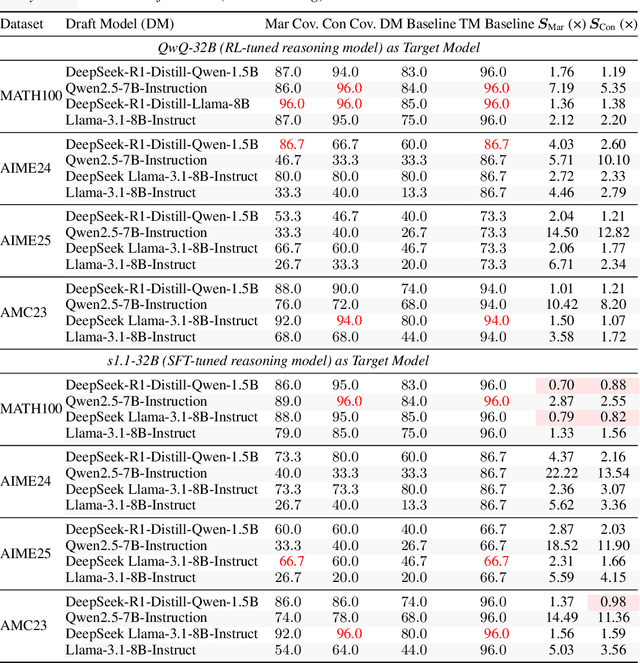
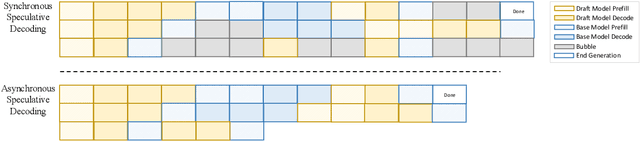
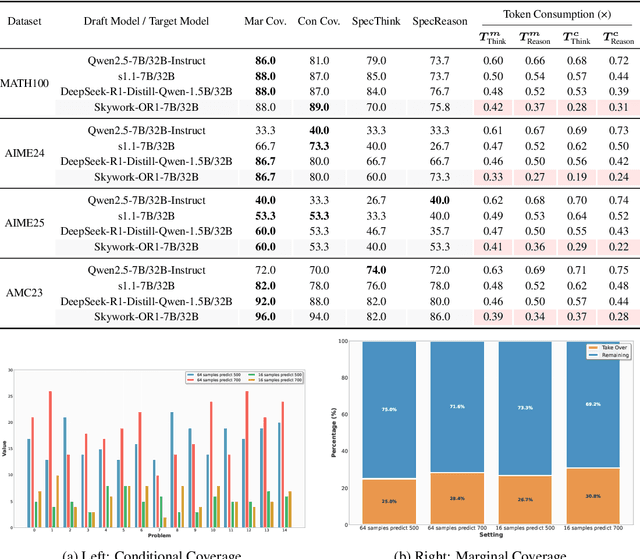
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
SynapseRoute: An Auto-Route Switching Framework on Dual-State Large Language Model
Jul 03, 2025



With the widespread adoption of large language models (LLMs) in practical applications, selecting an appropriate model requires balancing not only performance but also operational cost. The emergence of reasoning-capable models has further widened the cost gap between "thinking" (high reasoning) and "non-thinking" (fast, low-cost) modes. In this work, we reveal that approximately 58% of medical questions can be accurately answered by the non-thinking mode alone, without requiring the high-cost reasoning process. This highlights a clear dichotomy in problem complexity and suggests that dynamically routing queries to the appropriate mode based on complexity could optimize accuracy, cost-efficiency, and overall user experience. Based on this, we further propose SynapseRoute, a machine learning-based dynamic routing framework that intelligently assigns input queries to either thinking or non-thinking modes. Experimental results on several medical datasets demonstrate that SynapseRoute not only improves overall accuracy (0.8390 vs. 0.8272) compared to the thinking mode alone but also reduces inference time by 36.8% and token consumption by 39.66%. Importantly, qualitative analysis indicates that over-reasoning on simpler queries can lead to unnecessary delays and even decreased accuracy, a pitfall avoided by our adaptive routing. Finally, this work further introduces the Accuracy-Inference-Token (AIT) index to comprehensively evaluate the trade-offs among accuracy, latency, and token cost.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Logits-Based Finetuning
May 30, 2025



The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection. Codes are available at https://github.com/JulietLJY/MOOD.
Self-Adjust Softmax
Feb 25, 2025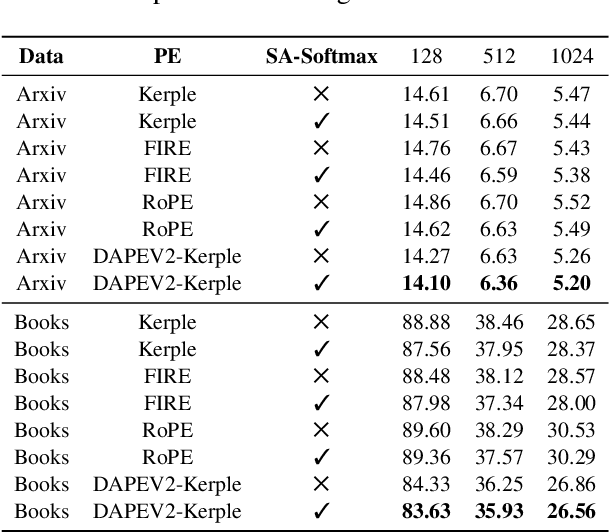
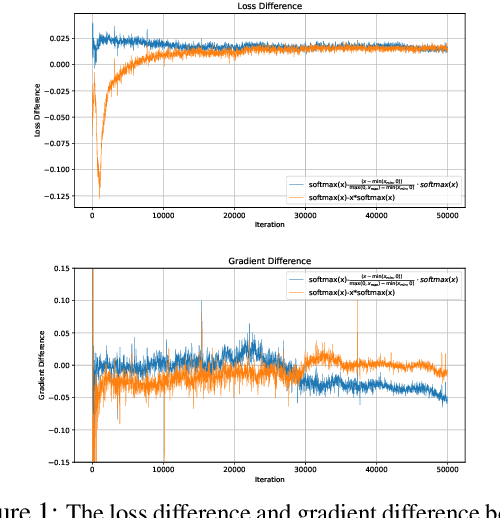
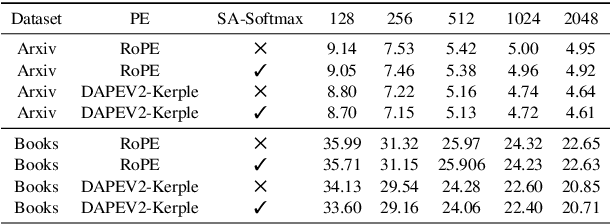
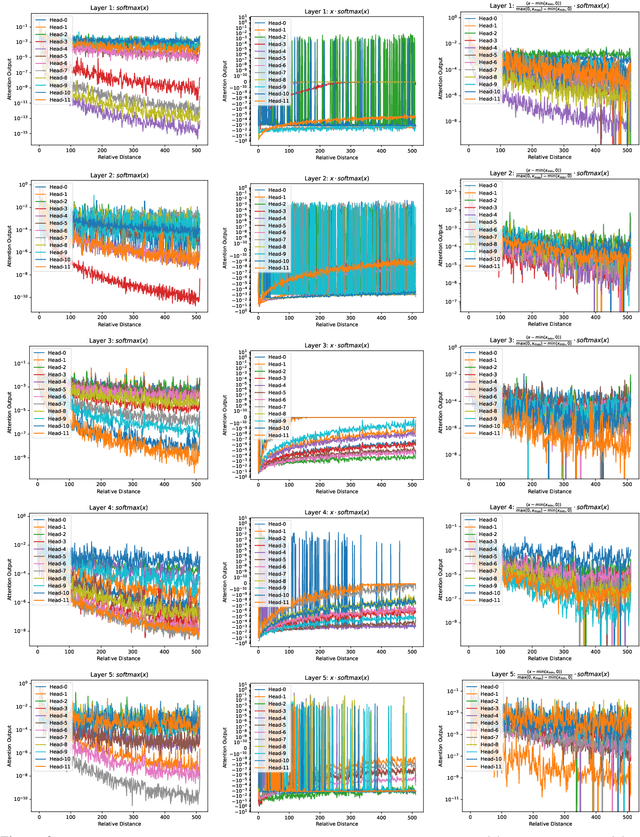
The softmax function is crucial in Transformer attention, which normalizes each row of the attention scores with summation to one, achieving superior performances over other alternative functions. However, the softmax function can face a gradient vanishing issue when some elements of the attention scores approach extreme values, such as probabilities close to one or zero. In this paper, we propose Self-Adjust Softmax (SA-Softmax) to address this issue by modifying $softmax(x)$ to $x \cdot softmax(x)$ and its normalized variant $\frac{(x - min(x_{\min},0))}{max(0,x_{max})-min(x_{min},0)} \cdot softmax(x)$. We theoretically show that SA-Softmax provides enhanced gradient properties compared to the vanilla softmax function. Moreover, SA-Softmax Attention can be seamlessly integrated into existing Transformer models to their attention mechanisms with minor adjustments. We conducted experiments to evaluate the empirical performance of Transformer models using SA-Softmax compared to the vanilla softmax function. These experiments, involving models with up to 2.7 billion parameters, are conducted across diverse datasets, language tasks, and positional encoding methods.
ParallelComp: Parallel Long-Context Compressor for Length Extrapolation
Feb 20, 2025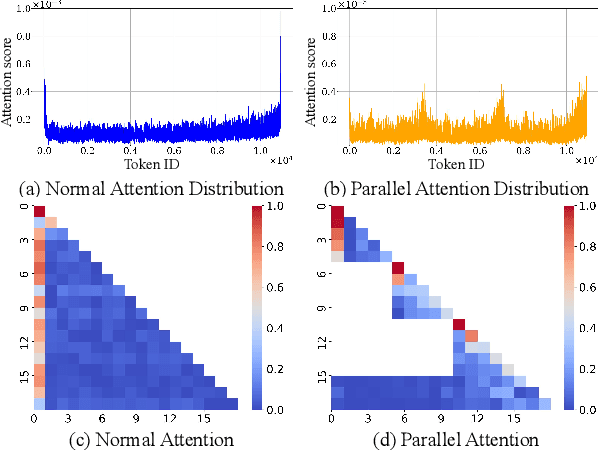
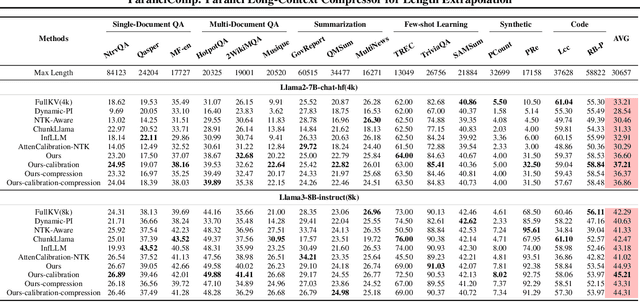
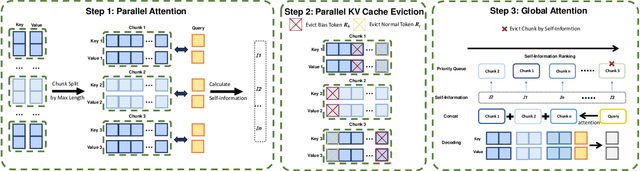
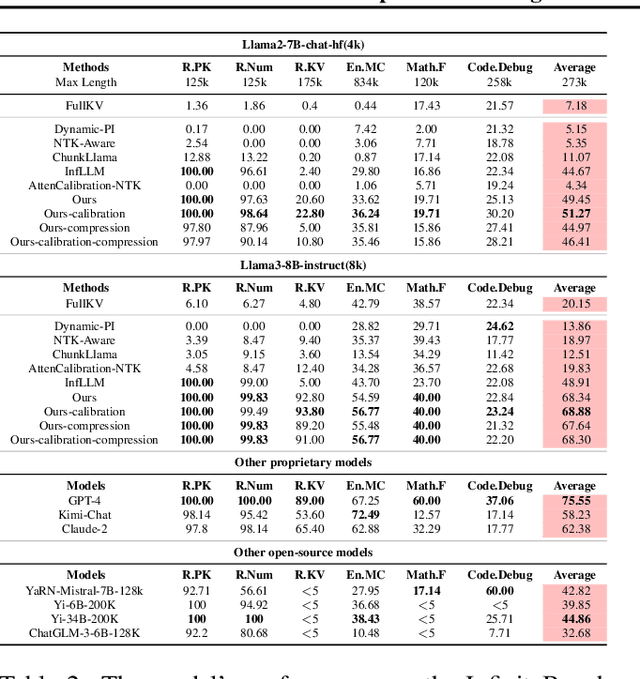
Efficiently handling long contexts is crucial for large language models (LLMs). While rotary position embeddings (RoPEs) enhance length generalization, effective length extrapolation remains challenging and often requires costly fine-tuning. In contrast, recent training-free approaches suffer from the attention sink phenomenon, leading to severe performance degradation. In this paper, we introduce ParallelComp, a novel training-free method for long-context extrapolation that extends LLMs' context length from 4K to 128K while maintaining high throughput and preserving perplexity, and integrates seamlessly with Flash Attention. Our analysis offers new insights into attention biases in parallel attention mechanisms and provides practical solutions to tackle these challenges. To mitigate the attention sink issue, we propose an attention calibration strategy that reduces biases, ensuring more stable long-range attention. Additionally, we introduce a chunk eviction strategy to efficiently manage ultra-long contexts on a single A100 80GB GPU. To further enhance efficiency, we propose a parallel KV cache eviction technique, which improves chunk throughput by 1.76x, thereby achieving a 23.50x acceleration in the prefilling stage with negligible performance loss due to attention calibration. Furthermore, ParallelComp achieves 91.17% of GPT-4's performance on long-context tasks using an 8B model trained on 8K-length context, outperforming powerful closed-source models such as Claude-2 and Kimi-Chat.
The Linear Attention Resurrection in Vision Transformer
Jan 27, 2025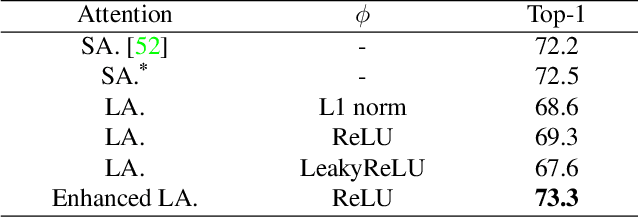
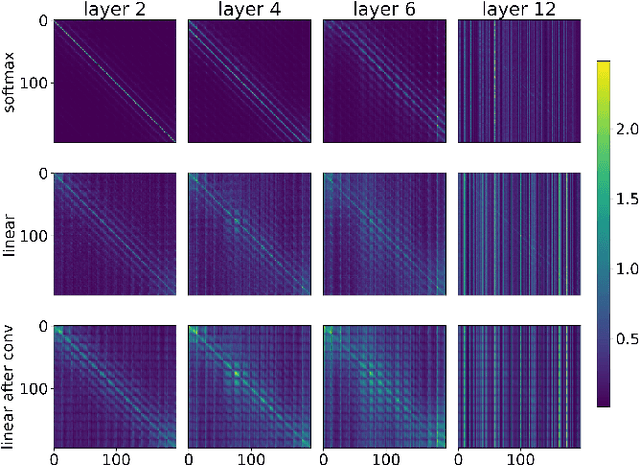
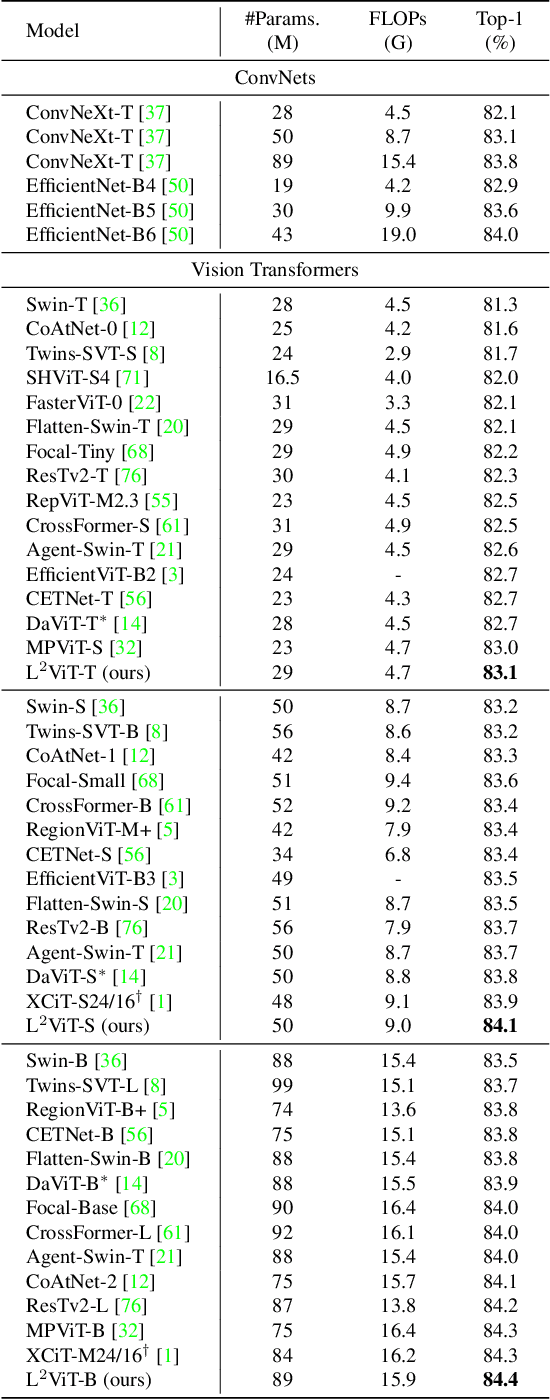
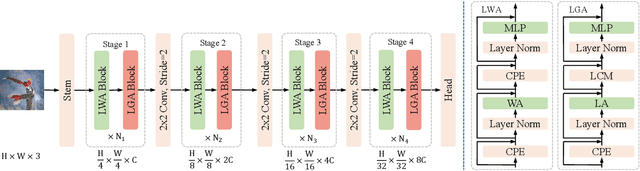
Vision Transformers (ViTs) have recently taken computer vision by storm. However, the softmax attention underlying ViTs comes with a quadratic complexity in time and memory, hindering the application of ViTs to high-resolution images. We revisit the attention design and propose a linear attention method to address the limitation, which doesn't sacrifice ViT's core advantage of capturing global representation like existing methods (e.g. local window attention of Swin). We further investigate the key difference between linear attention and softmax attention. Our empirical results suggest that linear attention lacks a fundamental property of concentrating the distribution of the attention matrix. Inspired by this observation, we introduce a local concentration module to enhance linear attention. By incorporating enhanced linear global attention and local window attention, we propose a new ViT architecture, dubbed L$^2$ViT. Notably, L$^2$ViT can effectively capture both global interactions and local representations while enjoying linear computational complexity. Extensive experiments demonstrate the strong performance of L$^2$ViT. On image classification, L$^2$ViT achieves 84.4% Top-1 accuracy on ImageNet-1K without any extra training data or label. By further pre-training on ImageNet-22k, it attains 87.0% when fine-tuned with resolution 384$^2$. For downstream tasks, L$^2$ViT delivers favorable performance as a backbone on object detection as well as semantic segmentation.
iFormer: Integrating ConvNet and Transformer for Mobile Application
Jan 26, 2025We present a new family of mobile hybrid vision networks, called iFormer, with a focus on optimizing latency and accuracy on mobile applications. iFormer effectively integrates the fast local representation capacity of convolution with the efficient global modeling ability of self-attention. The local interactions are derived from transforming a standard convolutional network, \textit{i.e.}, ConvNeXt, to design a more lightweight mobile network. Our newly introduced mobile modulation attention removes memory-intensive operations in MHA and employs an efficient modulation mechanism to boost dynamic global representational capacity. We conduct comprehensive experiments demonstrating that iFormer outperforms existing lightweight networks across various tasks. Notably, iFormer achieves an impressive Top-1 accuracy of 80.4\% on ImageNet-1k with a latency of only 1.10 ms on an iPhone 13, surpassing the recently proposed MobileNetV4 under similar latency constraints. Additionally, our method shows significant improvements in downstream tasks, including COCO object detection, instance segmentation, and ADE20k semantic segmentation, while still maintaining low latency on mobile devices for high-resolution inputs in these scenarios.