 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTIS: Agentic Risk-Aware Test-Time Scaling via Iterative Simulation
Feb 03, 2026Current test-time scaling (TTS) techniques enhance large language model (LLM) performance by allocating additional computation at inference time, yet they remain insufficient for agentic settings, where actions directly interact with external environments and their effects can be irreversible and costly. We propose ARTIS, Agentic Risk-Aware Test-Time Scaling via Iterative Simulation, a framework that decouples exploration from commitment by enabling test-time exploration through simulated interactions prior to real-world execution. This design allows extending inference-time computation to improve action-level reliability and robustness without incurring environmental risk. We further show that naive LLM-based simulators struggle to capture rare but high-impact failure modes, substantially limiting their effectiveness for agentic decision making. To address this limitation, we introduce a risk-aware tool simulator that emphasizes fidelity on failure-inducing actions via targeted data generation and rebalanced training. Experiments on multi-turn and multi-step agentic benchmarks demonstrate that iterative simulation substantially improves agent reliability, and that risk-aware simulation is essential for consistently realizing these gains across models and tasks.
DreamVAR: Taming Reinforced Visual Autoregressive Model for High-Fidelity Subject-Driven Image Generation
Jan 30, 2026Recent advances in subject-driven image generation using diffusion models have attracted considerable attention for their remarkable capabilities in producing high-quality images. Nevertheless, the potential of Visual Autoregressive (VAR) models, despite their unified architecture and efficient inference, remains underexplored. In this work, we present DreamVAR, a novel framework for subject-driven image synthesis built upon a VAR model that employs next-scale prediction. Technically, multi-scale features of the reference subject are first extracted by a visual tokenizer. Instead of interleaving these conditional features with target image tokens across scales, our DreamVAR pre-fills the full subject feature sequence prior to predicting target image tokens. This design simplifies autoregressive dependencies and mitigates the train-test discrepancy in multi-scale conditioning scenario within the VAR paradigm. DreamVAR further incorporates reinforcement learning to jointly enhance semantic alignment and subject consistency. Extensive experiments demonstrate that DreamVAR achieves superior appearance preservation compared to leading diffusion-based methods.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
May 23, 2025Mathematical reasoning through Chain-of-Thought (CoT) has emerged as a powerful capability of Large Language Models (LLMs), which can be further enhanced through Test-Time Scaling (TTS) methods like Beam Search and DVTS. However, these methods, despite improving accuracy by allocating more computational resources during inference, often suffer from path homogenization and inefficient use of intermediate results. To address these limitations, we propose Stepwise Reasoning Checkpoint Analysis (SRCA), a framework that introduces checkpoints between reasoning steps. It incorporates two key strategies: (1) Answer-Clustered Search, which groups reasoning paths by their intermediate checkpoint answers to maintain diversity while ensuring quality, and (2) Checkpoint Candidate Augmentation, which leverages all intermediate answers for final decision-making. Our approach effectively reduces path homogenization and creates a fault-tolerant mechanism by utilizing high-quality intermediate results. Experimental results show that SRCA improves reasoning accuracy compared to existing TTS methods across various mathematical datasets.
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Apr 22, 2025The improvement of LLMs' instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm--Web as Instruction and Web as Response--where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.
IMAGGarment-1: Fine-Grained Garment Generation for Controllable Fashion Design
Apr 17, 2025



This paper presents IMAGGarment-1, a fine-grained garment generation (FGG) framework that enables high-fidelity garment synthesis with precise control over silhouette, color, and logo placement. Unlike existing methods that are limited to single-condition inputs, IMAGGarment-1 addresses the challenges of multi-conditional controllability in personalized fashion design and digital apparel applications. Specifically, IMAGGarment-1 employs a two-stage training strategy to separately model global appearance and local details, while enabling unified and controllable generation through end-to-end inference. In the first stage, we propose a global appearance model that jointly encodes silhouette and color using a mixed attention module and a color adapter. In the second stage, we present a local enhancement model with an adaptive appearance-aware module to inject user-defined logos and spatial constraints, enabling accurate placement and visual consistency. To support this task, we release GarmentBench, a large-scale dataset comprising over 180K garment samples paired with multi-level design conditions, including sketches, color references, logo placements, and textual prompts. Extensive experiments demonstrate that our method outperforms existing baselines, achieving superior structural stability, color fidelity, and local controllability performance. The code and model are available at https://github.com/muzishen/IMAGGarment-1.
ToolACE-R: Tool Learning with Adaptive Self-Refinement
Apr 02, 2025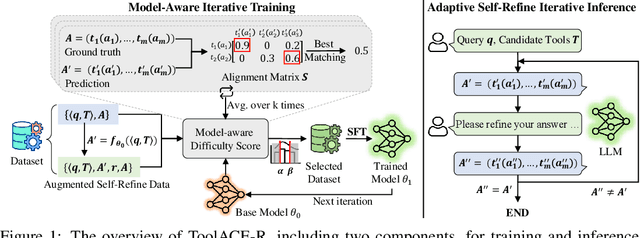
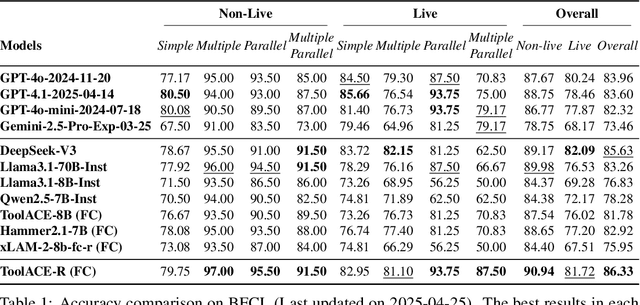
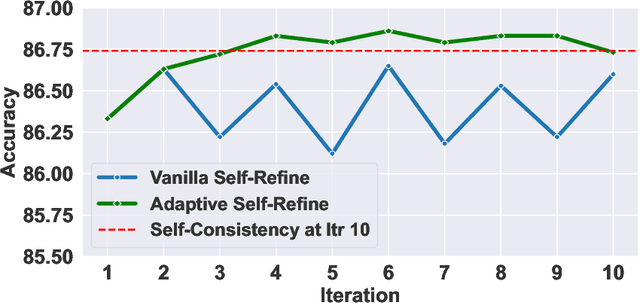

Tool learning, which allows Large Language Models (LLMs) to leverage external tools for solving complex user tasks, has emerged as a promising avenue for extending model capabilities. However, current approaches primarily focus on data synthesis for fine-tuning LLMs to invoke tools effectively, largely ignoring how to fully stimulate the potential of the model. In this paper, we propose ToolACE-R, a novel method that introduces adaptive self-refinement for tool invocations. Our approach features a model-aware iterative training procedure that progressively incorporates more training samples based on the model's evolving capabilities. Additionally, it allows LLMs to iteratively refine their tool calls, optimizing performance without requiring external feedback. To further enhance computational efficiency, we integrate an adaptive mechanism when scaling the inference time, enabling the model to autonomously determine when to stop the refinement process. We conduct extensive experiments across several benchmark datasets, showing that ToolACE-R achieves competitive performance compared to advanced API-based models, even without any refinement. Furthermore, its performance can be further improved efficiently through adaptive self-refinement. Our results demonstrate the effectiveness of the proposed method, which is compatible with base models of various sizes, offering a promising direction for more efficient tool learning.
CADFormer: Fine-Grained Cross-modal Alignment and Decoding Transformer for Referring Remote Sensing Image Segmentation
Mar 30, 2025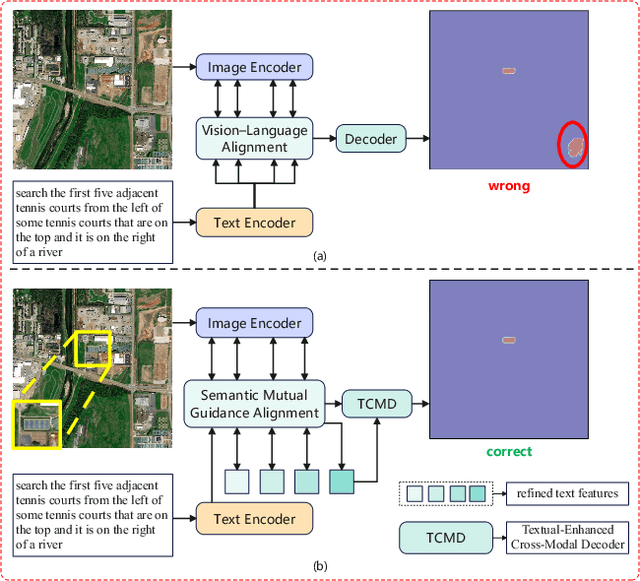

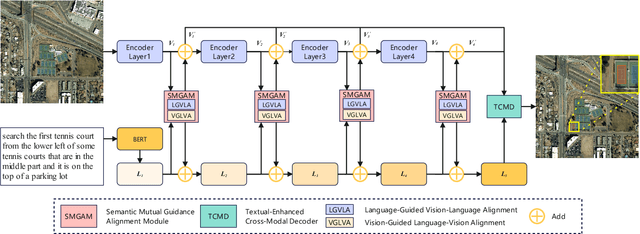
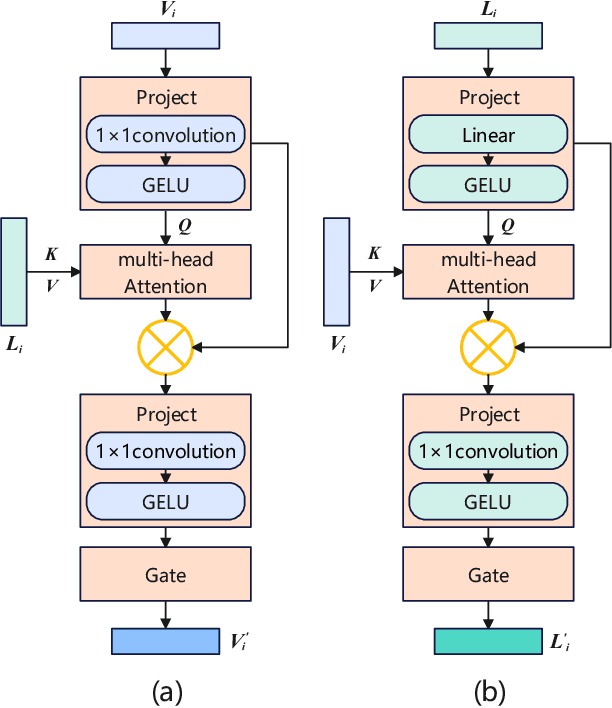
Referring Remote Sensing Image Segmentation (RRSIS) is a challenging task, aiming to segment specific target objects in remote sensing (RS) images based on a given language expression. Existing RRSIS methods typically employ coarse-grained unidirectional alignment approaches to obtain multimodal features, and they often overlook the critical role of language features as contextual information during the decoding process. Consequently, these methods exhibit weak object-level correspondence between visual and language features, leading to incomplete or erroneous predicted masks, especially when handling complex expressions and intricate RS image scenes. To address these challenges, we propose a fine-grained cross-modal alignment and decoding Transformer, CADFormer, for RRSIS. Specifically, we design a semantic mutual guidance alignment module (SMGAM) to achieve both vision-to-language and language-to-vision alignment, enabling comprehensive integration of visual and textual features for fine-grained cross-modal alignment. Furthermore, a textual-enhanced cross-modal decoder (TCMD) is introduced to incorporate language features during decoding, using refined textual information as context to enhance the relationship between cross-modal features. To thoroughly evaluate the performance of CADFormer, especially for inconspicuous targets in complex scenes, we constructed a new RRSIS dataset, called RRSIS-HR, which includes larger high-resolution RS image patches and semantically richer language expressions. Extensive experiments on the RRSIS-HR dataset and the popular RRSIS-D dataset demonstrate the effectiveness and superiority of CADFormer. Datasets and source codes will be available at https://github.com/zxk688.
A Survey on the Optimization of Large Language Model-based Agents
Mar 16, 2025



With the rapid development of Large Language Models (LLMs), LLM-based agents have been widely adopted in various fields, becoming essential for autonomous decision-making and interactive tasks. However, current work typically relies on prompt design or fine-tuning strategies applied to vanilla LLMs, which often leads to limited effectiveness or suboptimal performance in complex agent-related environments. Although LLM optimization techniques can improve model performance across many general tasks, they lack specialized optimization towards critical agent functionalities such as long-term planning, dynamic environmental interaction, and complex decision-making. Although numerous recent studies have explored various strategies to optimize LLM-based agents for complex agent tasks, a systematic review summarizing and comparing these methods from a holistic perspective is still lacking. In this survey, we provide a comprehensive review of LLM-based agent optimization approaches, categorizing them into parameter-driven and parameter-free methods. We first focus on parameter-driven optimization, covering fine-tuning-based optimization, reinforcement learning-based optimization, and hybrid strategies, analyzing key aspects such as trajectory data construction, fine-tuning techniques, reward function design, and optimization algorithms. Additionally, we briefly discuss parameter-free strategies that optimize agent behavior through prompt engineering and external knowledge retrieval. Finally, we summarize the datasets and benchmarks used for evaluation and tuning, review key applications of LLM-based agents, and discuss major challenges and promising future directions. Our repository for related references is available at https://github.com/YoungDubbyDu/LLM-Agent-Optimization.
Implicit Search via Discrete Diffusion: A Study on Chess
Feb 27, 2025In the post-AlphaGo era, there has been a renewed interest in search techniques such as Monte Carlo Tree Search (MCTS), particularly in their application to Large Language Models (LLMs). This renewed attention is driven by the recognition that current next-token prediction models often lack the ability for long-term planning. Is it possible to instill search-like abilities within the models to enhance their planning abilities without relying on explicit search? We propose DiffuSearch , a model that does \textit{implicit search} by looking into the future world via discrete diffusion modeling. We instantiate DiffuSearch on a classical board game, Chess, where explicit search is known to be essential. Through extensive controlled experiments, we show DiffuSearch outperforms both the searchless and explicit search-enhanced policies. Specifically, DiffuSearch outperforms the one-step policy by 19.2% and the MCTS-enhanced policy by 14% on action accuracy. Furthermore, DiffuSearch demonstrates a notable 30% enhancement in puzzle-solving abilities compared to explicit search-based policies, along with a significant 540 Elo increase in game-playing strength assessment. These results indicate that implicit search via discrete diffusion is a viable alternative to explicit search over a one-step policy. All codes are publicly available at \href{https://github.com/HKUNLP/DiffuSearch}{https://github.com/HKUNLP/DiffuSearch}.