 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADFormer: Fine-Grained Cross-modal Alignment and Decoding Transformer for Referring Remote Sensing Image Segmentation
Paper and Code
Mar 30, 2025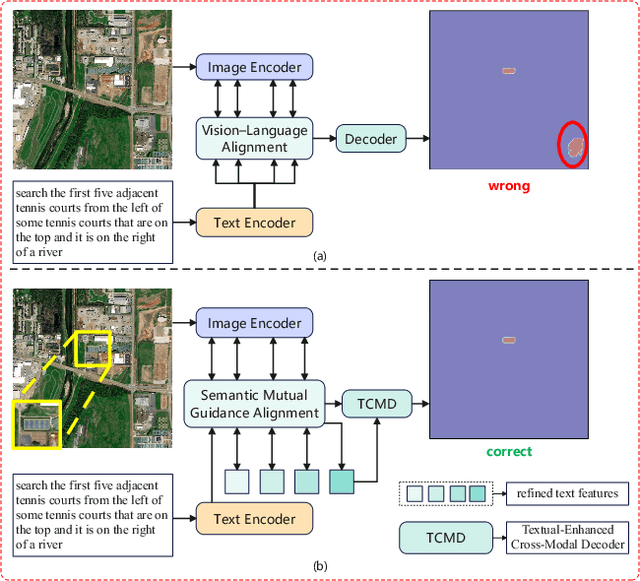

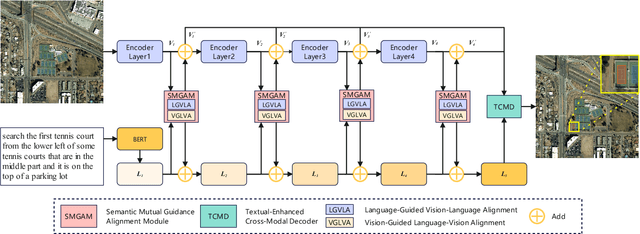
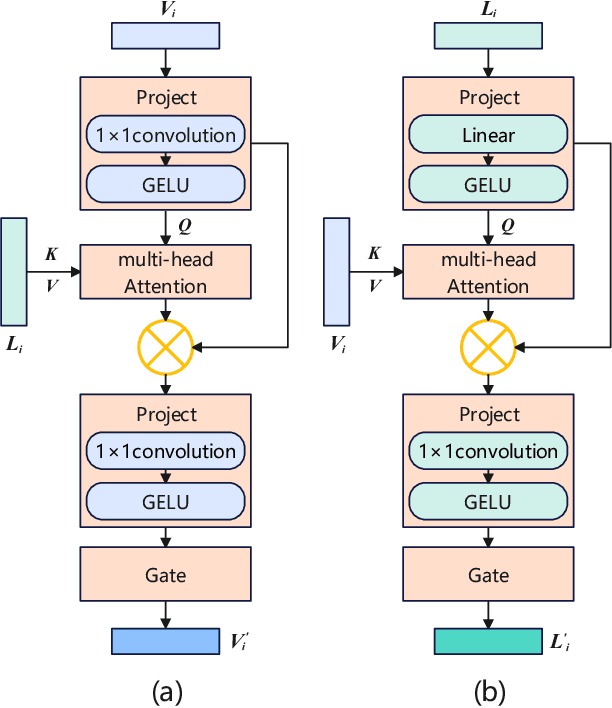
Referring Remote Sensing Image Segmentation (RRSIS) is a challenging task, aiming to segment specific target objects in remote sensing (RS) images based on a given language expression. Existing RRSIS methods typically employ coarse-grained unidirectional alignment approaches to obtain multimodal features, and they often overlook the critical role of language features as contextual information during the decoding process. Consequently, these methods exhibit weak object-level correspondence between visual and language features, leading to incomplete or erroneous predicted masks, especially when handling complex expressions and intricate RS image scenes. To address these challenges, we propose a fine-grained cross-modal alignment and decoding Transformer, CADFormer, for RRSIS. Specifically, we design a semantic mutual guidance alignment module (SMGAM) to achieve both vision-to-language and language-to-vision alignment, enabling comprehensive integration of visual and textual features for fine-grained cross-modal alignment. Furthermore, a textual-enhanced cross-modal decoder (TCMD) is introduced to incorporate language features during decoding, using refined textual information as context to enhance the relationship between cross-modal features. To thoroughly evaluate the performance of CADFormer, especially for inconspicuous targets in complex scenes, we constructed a new RRSIS dataset, called RRSIS-HR, which includes larger high-resolution RS image patches and semantically richer language expressions. Extensive experiments on the RRSIS-HR dataset and the popular RRSIS-D dataset demonstrate the effectiveness and superiority of CADFormer. Datasets and source codes will be available at https://github.com/zxk688.