 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Vision-Language Learning for Remote Sensing: Benchmarking and Analysis
Apr 01, 2026Current remote sensing vision-language models (RS VLMs) demonstrate impressive performance in image interpretation but rely on static training data, limiting their ability to accommodate continuously emerging sensing modalities and downstream tasks. This exposes a fundamental challenge: enabling RS VLMs to continually adapt without catastrophic forgetting. Despite its practical importance, the continual learning capability of RS VLMs remains underexplored, and no dedicated benchmark currently exists. In this work, we present CLeaRS, a comprehensive benchmark for continual vision-language learning in remote sensing. CLeaRS comprises 10 curated subsets with over 207k image-text pairs, spanning diverse interpretation tasks, sensing modalities, and application scenarios. We further define three evaluation protocols: long-horizon, modality-incremental, and task-incremental settings, to systematically assess continual adaptation. Extensive benchmarking of diverse vision-language models reveals catastrophic forgetting across all settings. Moreover, representative continual learning methods, when adapted to RS VLMs, exhibit limited effectiveness in handling task, instruction, and modality transitions. Our findings underscore the need for developing continual learning methods tailored to RS VLMs.
Geospatial-Reasoning-Driven Vocabulary-Agnostic Remote Sensing Semantic Segmentation
Feb 09, 2026Open-vocabulary semantic segmentation has emerged as a promising research direction in remote sensing, enabling the recognition of diverse land-cover types beyond pre-defined category sets. However, existing methods predominantly rely on the passive mapping of visual features and textual embeddings. This ``appearance-based" paradigm lacks geospatial contextual awareness, leading to severe semantic ambiguity and misclassification when encountering land-cover classes with similar spectral features but distinct semantic attributes. To address this, we propose a Geospatial Reasoning Chain-of-Thought (GR-CoT) framework designed to enhance the scene understanding capabilities of Multimodal Large Language Models (MLLMs), thereby guiding open-vocabulary segmentation models toward precise mapping. The framework comprises two collaborative components: an offline knowledge distillation stream and an online instance reasoning stream. The offline stream establishes fine-grained category interpretation standards to resolve semantic conflicts between similar land-cover types. During online inference, the framework executes a sequential reasoning process involving macro-scenario anchoring, visual feature decoupling, and knowledge-driven decision synthesis. This process generates an image-adaptive vocabulary that guides downstream models to achieve pixel-level alignment with correct geographical semantics. Extensive experiments on the LoveDA and GID5 benchmarks demonstrate the superiority of our approach.
Scaling Agentic Verifier for Competitive Coding
Feb 04, 2026Large language models (LLMs) have demonstrated strong coding capabilities but still struggle to solve competitive programming problems correctly in a single attempt. Execution-based re-ranking offers a promising test-time scaling strategy, yet existing methods are constrained by either difficult test case generation or inefficient random input sampling. To address this limitation, we propose Agentic Verifier, an execution-based agent that actively reasons about program behaviors and searches for highly discriminative test inputs that expose behavioral discrepancies among candidate solutions. Through multi-turn interaction with code execution environments, the verifier iteratively refines the candidate input generator and produces targeted counterexamples rather than blindly sampling inputs. We train the verifier to acquire this discriminative input generation capability via a scalable pipeline combining large-scale data synthesis, rejection fine-tuning, and agentic reinforcement learning. Extensive experiments across five competitive programming benchmarks demonstrate consistent improvements over strong execution-based baselines, achieving up to +10-15% absolute gains in Best@K accuracy. Further analysis reveals clear test-time scaling behavior and highlights the verifier's broader potential beyond reranking.
Sparse-RL: Breaking the Memory Wall in LLM Reinforcement Learning via Stable Sparse Rollouts
Jan 15, 2026Reinforcement Learning (RL) has become essential for eliciting complex reasoning capabilities in Large Language Models (LLMs). However, the substantial memory overhead of storing Key-Value (KV) caches during long-horizon rollouts acts as a critical bottleneck, often prohibiting efficient training on limited hardware. While existing KV compression techniques offer a remedy for inference, directly applying them to RL training induces a severe policy mismatch, leading to catastrophic performance collapse. To address this, we introduce Sparse-RL empowers stable RL training under sparse rollouts. We show that instability arises from a fundamental policy mismatch among the dense old policy, the sparse sampler policy, and the learner policy. To mitigate this issue, Sparse-RL incorporates Sparsity-Aware Rejection Sampling and Importance-based Reweighting to correct the off-policy bias introduced by compression-induced information loss. Experimental results show that Sparse-RL reduces rollout overhead compared to dense baselines while preserving the performance. Furthermore, Sparse-RL inherently implements sparsity-aware training, significantly enhancing model robustness during sparse inference deployment.
Geospatial Foundation Models to Enable Progress on Sustainable Development Goals
May 30, 2025Foundation Models (FMs) are large-scale, pre-trained AI systems that have revolutionized natural language processing and computer vision, and are now advancing geospatial analysis and Earth Observation (EO). They promise improved generalization across tasks, scalability, and efficient adaptation with minimal labeled data. However, despite the rapid proliferation of geospatial FMs, their real-world utility and alignment with global sustainability goals remain underexplored. We introduce SustainFM, a comprehensive benchmarking framework grounded in the 17 Sustainable Development Goals with extremely diverse tasks ranging from asset wealth prediction to environmental hazard detection. This study provides a rigorous, interdisciplinary assessment of geospatial FMs and offers critical insights into their role in attaining sustainability goals. Our findings show: (1) While not universally superior, FMs often outperform traditional approaches across diverse tasks and datasets. (2) Evaluating FMs should go beyond accuracy to include transferability, generalization, and energy efficiency as key criteria for their responsible use. (3) FMs enable scalable, SDG-grounded solutions, offering broad utility for tackling complex sustainability challenges. Critically, we advocate for a paradigm shift from model-centric development to impact-driven deployment, and emphasize metrics such as energy efficiency, robustness to domain shifts, and ethical considerations.
CADFormer: Fine-Grained Cross-modal Alignment and Decoding Transformer for Referring Remote Sensing Image Segmentation
Mar 30, 2025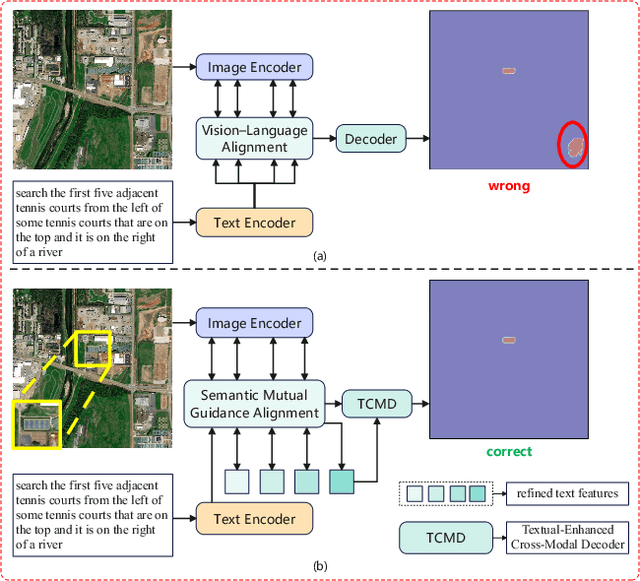

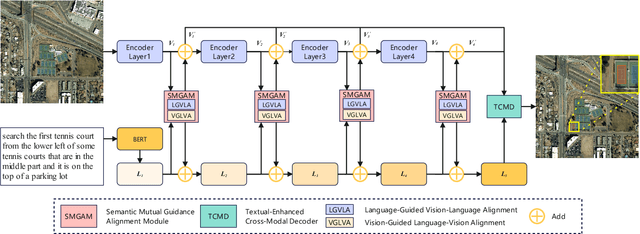
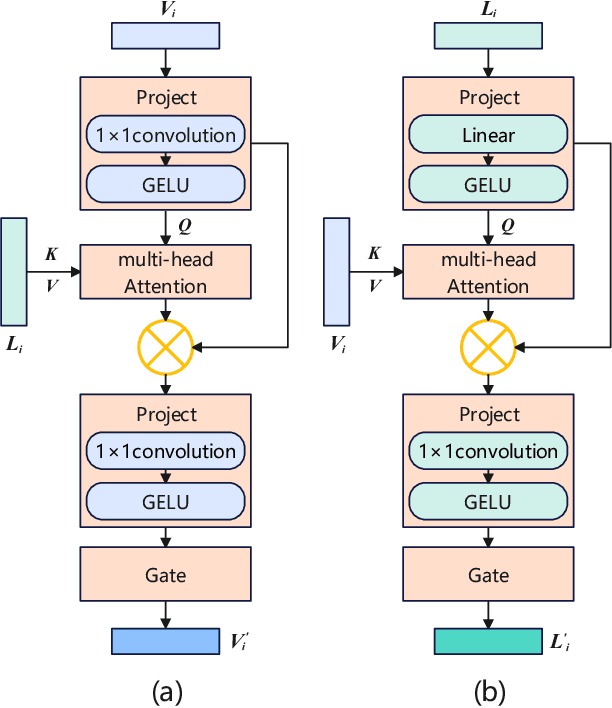
Referring Remote Sensing Image Segmentation (RRSIS) is a challenging task, aiming to segment specific target objects in remote sensing (RS) images based on a given language expression. Existing RRSIS methods typically employ coarse-grained unidirectional alignment approaches to obtain multimodal features, and they often overlook the critical role of language features as contextual information during the decoding process. Consequently, these methods exhibit weak object-level correspondence between visual and language features, leading to incomplete or erroneous predicted masks, especially when handling complex expressions and intricate RS image scenes. To address these challenges, we propose a fine-grained cross-modal alignment and decoding Transformer, CADFormer, for RRSIS. Specifically, we design a semantic mutual guidance alignment module (SMGAM) to achieve both vision-to-language and language-to-vision alignment, enabling comprehensive integration of visual and textual features for fine-grained cross-modal alignment. Furthermore, a textual-enhanced cross-modal decoder (TCMD) is introduced to incorporate language features during decoding, using refined textual information as context to enhance the relationship between cross-modal features. To thoroughly evaluate the performance of CADFormer, especially for inconspicuous targets in complex scenes, we constructed a new RRSIS dataset, called RRSIS-HR, which includes larger high-resolution RS image patches and semantically richer language expressions. Extensive experiments on the RRSIS-HR dataset and the popular RRSIS-D dataset demonstrate the effectiveness and superiority of CADFormer. Datasets and source codes will be available at https://github.com/zxk688.
Semantic-Spatial Feature Fusion with Dynamic Graph Refinement for Remote Sensing Image Captioning
Mar 30, 2025



Remote sensing image captioning aims to generate semantically accurate descriptions that are closely linked to the visual features of remote sensing images. Existing approaches typically emphasize fine-grained extraction of visual features and capturing global information. However, they often overlook the complementary role of textual information in enhancing visual semantics and face challenges in precisely locating objects that are most relevant to the image context. To address these challenges, this paper presents a semantic-spatial feature fusion with dynamic graph refinement (SFDR) method, which integrates the semantic-spatial feature fusion (SSFF) and dynamic graph feature refinement (DGFR) modules. The SSFF module utilizes a multi-level feature representation strategy by leveraging pre-trained CLIP features, grid features, and ROI features to integrate rich semantic and spatial information. In the DGFR module, a graph attention network captures the relationships between feature nodes, while a dynamic weighting mechanism prioritizes objects that are most relevant to the current scene and suppresses less significant ones. Therefore, the proposed SFDR method significantly enhances the quality of the generated descriptions. Experimental results on three benchmark datasets demonstrate the effectiveness of the proposed method. The source code will be available at https://github.com/zxk688}{https://github.com/zxk688.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
Feb 17, 2025



Direct Preference Optimization (DPO) has proven effective in complex reasoning tasks like math word problems and code generation. However, when applied to Text-to-SQL datasets, it often fails to improve performance and can even degrade it. Our investigation reveals the root cause: unlike math and code tasks, which naturally integrate Chain-of-Thought (CoT) reasoning with DPO, Text-to-SQL datasets typically include only final answers (gold SQL queries) without detailed CoT solutions. By augmenting Text-to-SQL datasets with synthetic CoT solutions, we achieve, for the first time, consistent and significant performance improvements using DPO. Our analysis shows that CoT reasoning is crucial for unlocking DPO's potential, as it mitigates reward hacking, strengthens discriminative capabilities, and improves scalability. These findings offer valuable insights for building more robust Text-to-SQL models. To support further research, we publicly release the code and CoT-enhanced datasets.
Kolmogorov-Arnold Network for Remote Sensing Image Semantic Segmentation
Jan 13, 2025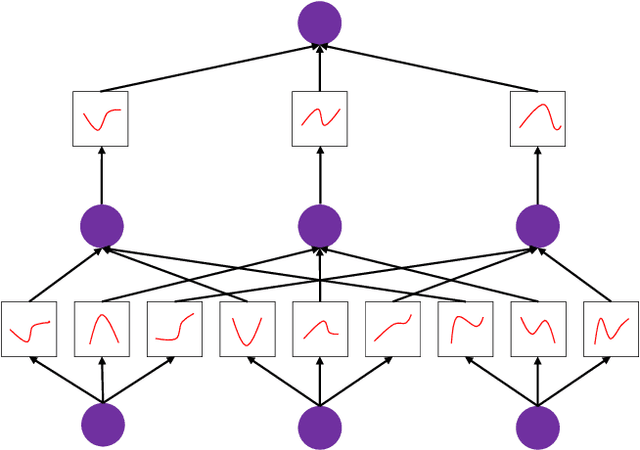
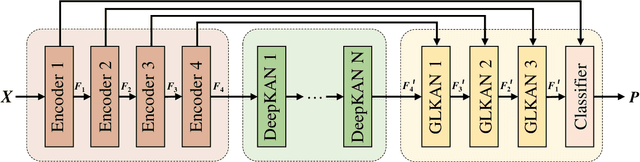
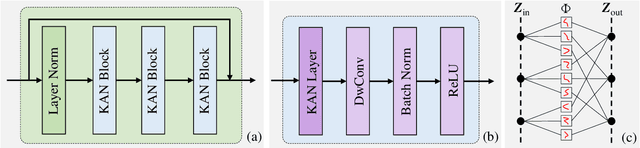
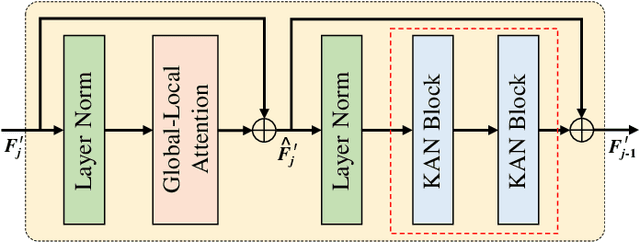
Semantic segmentation plays a crucial role in remote sensing applications, where the accurate extraction and representation of features are essential for high-quality results. Despite the widespread use of encoder-decoder architectures, existing methods often struggle with fully utilizing the high-dimensional features extracted by the encoder and efficiently recovering detailed information during decoding. To address these problems, we propose a novel semantic segmentation network, namely DeepKANSeg, including two key innovations based on the emerging Kolmogorov Arnold Network (KAN). Notably, the advantage of KAN lies in its ability to decompose high-dimensional complex functions into univariate transformations, enabling efficient and flexible representation of intricate relationships in data. First, we introduce a KAN-based deep feature refinement module, namely DeepKAN to effectively capture complex spatial and rich semantic relationships from high-dimensional features. Second, we replace the traditional multi-layer perceptron (MLP) layers in the global-local combined decoder with KAN-based linear layers, namely GLKAN. This module enhances the decoder's ability to capture fine-grained details during decoding. To evaluate the effectiveness of the proposed method, experiments are conducted on two well-known fine-resolution remote sensing benchmark datasets, namely ISPRS Vaihingen and ISPRS Potsdam. The results demonstrate that the KAN-enhanced segmentation model achieves superior performance in terms of accuracy compared to state-of-the-art methods. They highlight the potential of KANs as a powerful alternative to traditional architectures in semantic segmentation tasks. Moreover, the explicit univariate decomposition provides improved interpretability, which is particularly beneficial for applications requiring explainable learning in remote sensing.