 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Mar 03, 2026Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often struggle with fine-grained physical consistency, exhibiting physically implausible dynamics over time. In this work, we present \textbf{Phys4D}, a pipeline for learning physics-consistent 4D world representations from video diffusion models. Phys4D adopts \textbf{a three-stage training paradigm} that progressively lifts appearance-driven video diffusion models into physics-consistent 4D world representations. We first bootstrap robust geometry and motion representations through large-scale pseudo-supervised pretraining, establishing a foundation for 4D scene modeling. We then perform physics-grounded supervised fine-tuning using simulation-generated data, enforcing temporally consistent 4D dynamics. Finally, we apply simulation-grounded reinforcement learning to correct residual physical violations that are difficult to capture through explicit supervision. To evaluate fine-grained physical consistency beyond appearance-based metrics, we introduce a set of \textbf{4D world consistency evaluation} that probe geometric coherence, motion stability, and long-horizon physical plausibility. Experimental results demonstrate that Phys4D substantially improves fine-grained spatiotemporal and physical consistency compared to appearance-driven baselines, while maintaining strong generative performance. Our project page is available at https://sensational-brioche-7657e7.netlify.app/
PhyPrompt: RL-based Prompt Refinement for Physically Plausible Text-to-Video Generation
Mar 03, 2026State-of-the-art text-to-video (T2V) generators frequently violate physical laws despite high visual quality. We show this stems from insufficient physical constraints in prompts rather than model limitations: manually adding physics details reliably produces physically plausible videos, but requires expertise and does not scale. We present PhyPrompt, a two-stage reinforcement learning framework that automatically refines prompts for physically realistic generation. First, we fine-tune a large language model on a physics-focused Chain-of-Thought dataset to integrate principles like object motion and force interactions while preserving user intent. Second, we apply Group Relative Policy Optimization with a dynamic reward curriculum that initially prioritizes semantic fidelity, then progressively shifts toward physical commonsense. This curriculum achieves synergistic optimization: PhyPrompt-7B reaches 40.8\% joint success on VideoPhy2 (8.6pp gain), improving physical commonsense by 11pp (55.8\% to 66.8\%) while simultaneously increasing semantic adherence by 4.4pp (43.4\% to 47.8\%). Remarkably, our curriculum exceeds single-objective training on both metrics, demonstrating compositional prompt discovery beyond conventional multi-objective trade-offs. PhyPrompt outperforms GPT-4o (+3.8\% joint) and DeepSeek-V3 (+2.2\%, 100$\times$ larger) using only 7B parameters. The approach transfers zero-shot across diverse T2V architectures (Lavie, VideoCrafter2, CogVideoX-5B) with up to 16.8\% improvement, establishing that domain-specialized reinforcement learning with compositional curricula surpasses general-purpose scaling for physics-aware generation.
Towards Sparse Video Understanding and Reasoning
Feb 14, 2026We present \revise (\underline{Re}asoning with \underline{Vi}deo \underline{S}parsity), a multi-round agent for video question answering (VQA). Instead of uniformly sampling frames, \revise selects a small set of informative frames, maintains a summary-as-state across rounds, and stops early when confident. It supports proprietary vision-language models (VLMs) in a ``plug-and-play'' setting and enables reinforcement fine-tuning for open-source models. For fine-tuning, we introduce EAGER (Evidence-Adjusted Gain for Efficient Reasoning), an annotation-free reward with three terms: (1) Confidence gain: after new frames are added, we reward the increase in the log-odds gap between the correct option and the strongest alternative; (2) Summary sufficiency: at answer time we re-ask using only the last committed summary and reward success; (3) Correct-and-early stop: answering correctly within a small turn budget is rewarded. Across multiple VQA benchmarks, \revise improves accuracy while reducing frames, rounds, and prompt tokens, demonstrating practical sparse video reasoning.
Learning to Feel the Future: DreamTacVLA for Contact-Rich Manipulation
Dec 29, 2025Vision-Language-Action (VLA) models have shown remarkable generalization by mapping web-scale knowledge to robotic control, yet they remain blind to physical contact. Consequently, they struggle with contact-rich manipulation tasks that require reasoning about force, texture, and slip. While some approaches incorporate low-dimensional tactile signals, they fail to capture the high-resolution dynamics essential for such interactions. To address this limitation, we introduce DreamTacVLA, a framework that grounds VLA models in contact physics by learning to feel the future. Our model adopts a hierarchical perception scheme in which high-resolution tactile images serve as micro-vision inputs coupled with wrist-camera local vision and third-person macro vision. To reconcile these multi-scale sensory streams, we first train a unified policy with a Hierarchical Spatial Alignment (HSA) loss that aligns tactile tokens with their spatial counterparts in the wrist and third-person views. To further deepen the model's understanding of fine-grained contact dynamics, we finetune the system with a tactile world model that predicts future tactile signals. To mitigate tactile data scarcity and the wear-prone nature of tactile sensors, we construct a hybrid large-scale dataset sourced from both high-fidelity digital twin and real-world experiments. By anticipating upcoming tactile states, DreamTacVLA acquires a rich model of contact physics and conditions its actions on both real observations and imagined consequences. Across contact-rich manipulation tasks, it outperforms state-of-the-art VLA baselines, achieving up to 95% success, highlighting the importance of understanding physical contact for robust, touch-aware robotic agents.
A Theoretical Analysis of Discrete Flow Matching Generative Models
Sep 26, 2025We provide a theoretical analysis for end-to-end training Discrete Flow Matching (DFM) generative models. DFM is a promising discrete generative modeling framework that learns the underlying generative dynamics by training a neural network to approximate the transformative velocity field. Our analysis establishes a clear chain of guarantees by decomposing the final distribution estimation error. We first prove that the total variation distance between the generated and target distributions is controlled by the risk of the learned velocity field. We then bound this risk by analyzing its two primary sources: (i) Approximation Error, where we quantify the capacity of the Transformer architecture to represent the true velocity, and (ii) Estimation Error, where we derive statistical convergence rates that bound the error from training on a finite dataset. By composing these results, we provide the first formal proof that the distribution generated by a trained DFM model provably converges to the true data distribution as the training set size increases.
HDLxGraph: Bridging Large Language Models and HDL Repositories via HDL Graph Databases
May 21, 2025Large Language Models (LLMs) have demonstrated their potential in hardware design tasks, such as Hardware Description Language (HDL) generation and debugging. Yet, their performance in real-world, repository-level HDL projects with thousands or even tens of thousands of code lines is hindered. To this end, we propose HDLxGraph, a novel framework that integrates Graph Retrieval Augmented Generation (Graph RAG) with LLMs, introducing HDL-specific graph representations by incorporating Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs) to capture both code graph view and hardware graph view. HDLxGraph utilizes a dual-retrieval mechanism that not only mitigates the limited recall issues inherent in similarity-based semantic retrieval by incorporating structural information, but also enhances its extensibility to various real-world tasks by a task-specific retrieval finetuning. Additionally, to address the lack of comprehensive HDL search benchmarks, we introduce HDLSearch, a multi-granularity evaluation dataset derived from real-world repository-level projects. Experimental results demonstrate that HDLxGraph significantly improves average search accuracy, debugging efficiency and completion quality by 12.04%, 12.22% and 5.04% compared to similarity-based RAG, respectively. The code of HDLxGraph and collected HDLSearch benchmark are available at https://github.com/Nick-Zheng-Q/HDLxGraph.
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
May 16, 2025

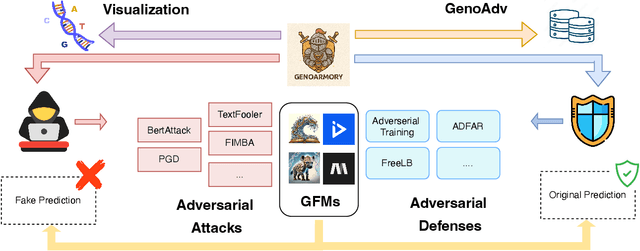

We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.
Computational and Statistical Asymptotic Analysis of the JKO Scheme for Iterative Algorithms to update distributions
Jan 14, 2025The seminal paper of Jordan, Kinderlehrer, and Otto introduced what is now widely known as the JKO scheme, an iterative algorithmic framework for computing distributions. This scheme can be interpreted as a Wasserstein gradient flow and has been successfully applied in machine learning contexts, such as deriving policy solutions in reinforcement learning. In this paper, we extend the JKO scheme to accommodate models with unknown parameters. Specifically, we develop statistical methods to estimate these parameters and adapt the JKO scheme to incorporate the estimated values. To analyze the adopted statistical JKO scheme, we establish an asymptotic theory via stochastic partial differential equations that describes its limiting dynamic behavior. Our framework allows both the sample size used in parameter estimation and the number of algorithmic iterations to go to infinity. This study offers a unified framework for joint computational and statistical asymptotic analysis of the statistical JKO scheme. On the computational side, we examine the scheme's dynamic behavior as the number of iterations increases, while on the statistical side, we investigate the large-sample behavior of the resulting distributions computed through the scheme. We conduct numerical simulations to evaluate the finite-sample performance of the proposed methods and validate the developed asymptotic theory.
CMoralEval: A Moral Evaluation Benchmark for Chinese Large Language Models
Aug 19, 2024



What a large language model (LLM) would respond in ethically relevant context? In this paper, we curate a large benchmark CMoralEval for morality evaluation of Chinese LLMs. The data sources of CMoralEval are two-fold: 1) a Chinese TV program discussing Chinese moral norms with stories from the society and 2) a collection of Chinese moral anomies from various newspapers and academic papers on morality. With these sources, we aim to create a moral evaluation dataset characterized by diversity and authenticity. We develop a morality taxonomy and a set of fundamental moral principles that are not only rooted in traditional Chinese culture but also consistent with contemporary societal norms. To facilitate efficient construction and annotation of instances in CMoralEval, we establish a platform with AI-assisted instance generation to streamline the annotation process. These help us curate CMoralEval that encompasses both explicit moral scenarios (14,964 instances) and moral dilemma scenarios (15,424 instances), each with instances from different data sources. We conduct extensive experiments with CMoralEval to examine a variety of Chinese LLMs. Experiment results demonstrate that CMoralEval is a challenging benchmark for Chinese LLMs. The dataset is publicly available at \url{https://github.com/tjunlp-lab/CMoralEval}.