 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Reasoning Alignment: Reinforcement Learning from Hidden Representations
Mar 18, 2026We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representation learning with reinforcement learning to separate safe and unsafe reasoning trajectories, yielding a latent-space geometry that supports robust, reasoning-level safety alignment. Theoretically, we show that incorporating latent-textual consistency into GRPO eliminates superficially aligned policies by ruling them out as local optima. Empirically, we evaluate CRAFT on multiple safety benchmarks using two strong reasoning models, Qwen3-4B-Thinking and R1-Distill-Llama-8B, where it consistently outperforms state-of-the-art defenses such as IPO and SafeKey. Notably, CRAFT delivers an average 79.0% improvement in reasoning safety and 87.7% improvement in final-response safety over the base models, demonstrating the effectiveness of hidden-space reasoning alignment.
On Google's SynthID-Text LLM Watermarking System: Theoretical Analysis and Empirical Validation
Mar 03, 2026Google's SynthID-Text, the first ever production-ready generative watermark system for large language model, designs a novel Tournament-based method that achieves the state-of-the-art detectability for identifying AI-generated texts. The system's innovation lies in: 1) a new Tournament sampling algorithm for watermarking embedding, 2) a detection strategy based on the introduced score function (e.g., Bayesian or mean score), and 3) a unified design that supports both distortionary and non-distortionary watermarking methods. This paper presents the first theoretical analysis of SynthID-Text, with a focus on its detection performance and watermark robustness, complemented by empirical validation. For example, we prove that the mean score is inherently vulnerable to increased tournament layers, and design a layer inflation attack to break SynthID-Text. We also prove the Bayesian score offers improved watermark robustness w.r.t. layers and further establish that the optimal Bernoulli distribution for watermark detection is achieved when the parameter is set to 0.5. Together, these theoretical and empirical insights not only deepen our understanding of SynthID-Text, but also open new avenues for analyzing effective watermark removal strategies and designing robust watermarking techniques. Source code is available at https: //github.com/romidi80/Synth-ID-Empirical-Analysis.
SilentDrift: Exploiting Action Chunking for Stealthy Backdoor Attacks on Vision-Language-Action Models
Jan 20, 2026Vision-Language-Action (VLA) models are increasingly deployed in safety-critical robotic applications, yet their security vulnerabilities remain underexplored. We identify a fundamental security flaw in modern VLA systems: the combination of action chunking and delta pose representations creates an intra-chunk visual open-loop. This mechanism forces the robot to execute K-step action sequences, allowing per-step perturbations to accumulate through integration. We propose SILENTDRIFT, a stealthy black-box backdoor attack exploiting this vulnerability. Our method employs the Smootherstep function to construct perturbations with guaranteed C2 continuity, ensuring zero velocity and acceleration at trajectory boundaries to satisfy strict kinematic consistency constraints. Furthermore, our keyframe attack strategy selectively poisons only the critical approach phase, maximizing impact while minimizing trigger exposure. The resulting poisoned trajectories are visually indistinguishable from successful demonstrations. Evaluated on the LIBERO, SILENTDRIFT achieves a 93.2% Attack Success Rate with a poisoning rate under 2%, while maintaining a 95.3% Clean Task Success Rate.
VeFIA: An Efficient Inference Auditing Framework for Vertical Federated Collaborative Software
Jul 03, 2025



Vertical Federated Learning (VFL) is a distributed AI software deployment mechanism for cross-silo collaboration without accessing participants' data. However, existing VFL work lacks a mechanism to audit the execution correctness of the inference software of the data party. To address this problem, we design a Vertical Federated Inference Auditing (VeFIA) framework. VeFIA helps the task party to audit whether the data party's inference software is executed as expected during large-scale inference without leaking the data privacy of the data party or introducing additional latency to the inference system. The core of VeFIA is that the task party can use the inference results from a framework with Trusted Execution Environments (TEE) and the coordinator to validate the correctness of the data party's computation results. VeFIA guarantees that, as long as the abnormal inference exceeds 5.4%, the task party can detect execution anomalies in the inference software with a probability of 99.99%, without incurring any additional online inference latency. VeFIA's random sampling validation achieves 100% positive predictive value, negative predictive value, and true positive rate in detecting abnormal inference. To the best of our knowledge, this is the first paper to discuss the correctness of inference software execution in VFL.
Rectifying Privacy and Efficacy Measurements in Machine Unlearning: A New Inference Attack Perspective
Jun 16, 2025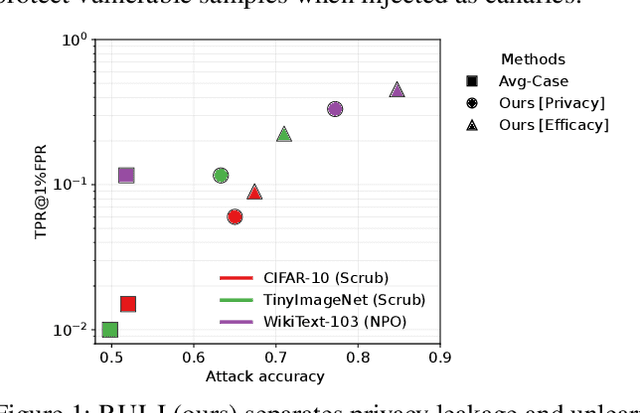

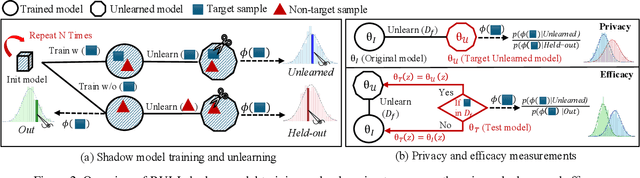
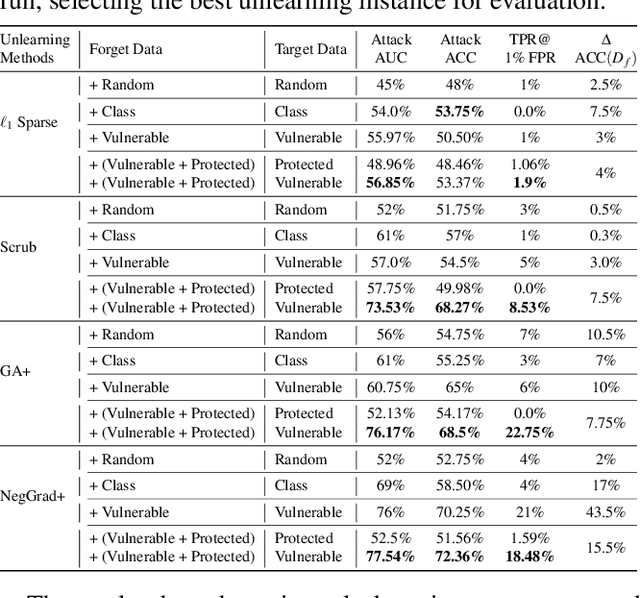
Machine unlearning focuses on efficiently removing specific data from trained models, addressing privacy and compliance concerns with reasonable costs. Although exact unlearning ensures complete data removal equivalent to retraining, it is impractical for large-scale models, leading to growing interest in inexact unlearning methods. However, the lack of formal guarantees in these methods necessitates the need for robust evaluation frameworks to assess their privacy and effectiveness. In this work, we first identify several key pitfalls of the existing unlearning evaluation frameworks, e.g., focusing on average-case evaluation or targeting random samples for evaluation, incomplete comparisons with the retraining baseline. Then, we propose RULI (Rectified Unlearning Evaluation Framework via Likelihood Inference), a novel framework to address critical gaps in the evaluation of inexact unlearning methods. RULI introduces a dual-objective attack to measure both unlearning efficacy and privacy risks at a per-sample granularity. Our findings reveal significant vulnerabilities in state-of-the-art unlearning methods, where RULI achieves higher attack success rates, exposing privacy risks underestimated by existing methods. Built on a game-based foundation and validated through empirical evaluations on both image and text data (spanning tasks from classification to generation), RULI provides a rigorous, scalable, and fine-grained methodology for evaluating unlearning techniques.
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
May 16, 2025

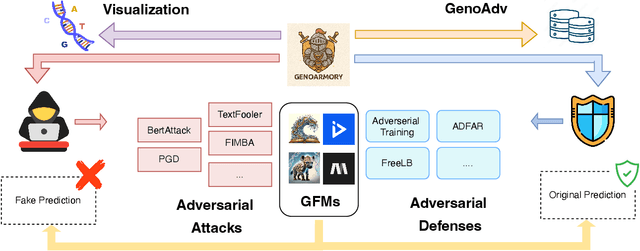

We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
FedTilt: Towards Multi-Level Fairness-Preserving and Robust Federated Learning
Mar 15, 2025Federated Learning (FL) is an emerging decentralized learning paradigm that can partly address the privacy concern that cannot be handled by traditional centralized and distributed learning. Further, to make FL practical, it is also necessary to consider constraints such as fairness and robustness. However, existing robust FL methods often produce unfair models, and existing fair FL methods only consider one-level (client) fairness and are not robust to persistent outliers (i.e., injected outliers into each training round) that are common in real-world FL settings. We propose \texttt{FedTilt}, a novel FL that can preserve multi-level fairness and be robust to outliers. In particular, we consider two common levels of fairness, i.e., \emph{client fairness} -- uniformity of performance across clients, and \emph{client data fairness} -- uniformity of performance across different classes of data within a client. \texttt{FedTilt} is inspired by the recently proposed tilted empirical risk minimization, which introduces tilt hyperparameters that can be flexibly tuned. Theoretically, we show how tuning tilt values can achieve the two-level fairness and mitigate the persistent outliers, and derive the convergence condition of \texttt{FedTilt} as well. Empirically, our evaluation results on a suite of realistic federated datasets in diverse settings show the effectiveness and flexibility of the \texttt{FedTilt} framework and the superiority to the state-of-the-arts.
Backdoor Attacks on Discrete Graph Diffusion Models
Mar 08, 2025Diffusion models are powerful generative models in continuous data domains such as image and video data. Discrete graph diffusion models (DGDMs) have recently extended them for graph generation, which are crucial in fields like molecule and protein modeling, and obtained the SOTA performance. However, it is risky to deploy DGDMs for safety-critical applications (e.g., drug discovery) without understanding their security vulnerabilities. In this work, we perform the first study on graph diffusion models against backdoor attacks, a severe attack that manipulates both the training and inference/generation phases in graph diffusion models. We first define the threat model, under which we design the attack such that the backdoored graph diffusion model can generate 1) high-quality graphs without backdoor activation, 2) effective, stealthy, and persistent backdoored graphs with backdoor activation, and 3) graphs that are permutation invariant and exchangeable--two core properties in graph generative models. 1) and 2) are validated via empirical evaluations without and with backdoor defenses, while 3) is validated via theoretical results.
Watermarking Graph Neural Networks via Explanations for Ownership Protection
Jan 09, 2025Graph Neural Networks (GNNs) are the mainstream method to learn pervasive graph data and are widely deployed in industry, making their intellectual property valuable. However, protecting GNNs from unauthorized use remains a challenge. Watermarking, which embeds ownership information into a model, is a potential solution. However, existing watermarking methods have two key limitations: First, almost all of them focus on non-graph data, with watermarking GNNs for complex graph data largely unexplored. Second, the de facto backdoor-based watermarking methods pollute training data and induce ownership ambiguity through intentional misclassification. Our explanation-based watermarking inherits the strengths of backdoor-based methods (e.g., robust to watermark removal attacks), but avoids data pollution and eliminates intentional misclassification. In particular, our method learns to embed the watermark in GNN explanations such that this unique watermark is statistically distinct from other potential solutions, and ownership claims must show statistical significance to be verified. We theoretically prove that, even with full knowledge of our method, locating the watermark is an NP-hard problem. Empirically, our method manifests robustness to removal attacks like fine-tuning and pruning. By addressing these challenges, our approach marks a significant advancement in protecting GNN intellectual property.
Practicable Black-box Evasion Attacks on Link Prediction in Dynamic Graphs -- A Graph Sequential Embedding Method
Dec 17, 2024



Link prediction in dynamic graphs (LPDG) has been widely applied to real-world applications such as website recommendation, traffic flow prediction, organizational studies, etc. These models are usually kept local and secure, with only the interactive interface restrictively available to the public. Thus, the problem of the black-box evasion attack on the LPDG model, where model interactions and data perturbations are restricted, seems to be essential and meaningful in practice. In this paper, we propose the first practicable black-box evasion attack method that achieves effective attacks against the target LPDG model, within a limited amount of interactions and perturbations. To perform effective attacks under limited perturbations, we develop a graph sequential embedding model to find the desired state embedding of the dynamic graph sequences, under a deep reinforcement learning framework. To overcome the scarcity of interactions, we design a multi-environment training pipeline and train our agent for multiple instances, by sharing an aggregate interaction buffer. Finally, we evaluate our attack against three advanced LPDG models on three real-world graph datasets of different scales and compare its performance with related methods under the interaction and perturbation constraints. Experimental results show that our attack is both effective and practicable.