 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prediction to Diagnosis: Reasoning-Aware AI for Photovoltaic Defect Inspection
Mar 24, 2026Reliable photovoltaic defect identification is essential for maintaining energy yield, ensuring warranty compliance, and enabling scalable inspection of rapidly expanding solar fleets. Although recent advances in computer vision have improved automated defect detection, most existing systems operate as opaque classifiers that provide limited diagnostic insight for high-stakes energy infrastructure. Here we introduce REVL-PV, a vision-language framework that embeds domain-specific diagnostic reasoning into multimodal learning across electroluminescence, thermal, and visible-light imagery. By requiring the model to link visual evidence to plausible defect mechanisms before classification, the framework produces structured diagnostic reports aligned with professional photovoltaic inspection practice. Evaluated on 1,927 real-world modules spanning eight defect categories, REVL-PV achieves 93\% classification accuracy while producing interpretable diagnostic rationales and maintaining strong robustness under realistic image corruptions. A blind concordance study with a certified solar inspection expert shows strong semantic alignment between model explanations and expert assessments across defect identification, root-cause attribution, and visual descriptions. These results demonstrate that reasoning-aware multimodal learning establishes a general paradigm for trustworthy AI-assisted inspection of photovoltaic energy infrastructure.
MCU: Improving Machine Unlearning through Mode Connectivity
May 16, 2025Machine Unlearning (MU) aims to remove the information of specific training data from a trained model, ensuring compliance with privacy regulations and user requests. While one line of existing MU methods relies on linear parameter updates via task arithmetic, they suffer from weight entanglement. In this work, we propose a novel MU framework called Mode Connectivity Unlearning (MCU) that leverages mode connectivity to find an unlearning pathway in a nonlinear manner. To further enhance performance and efficiency, we introduce a parameter mask strategy that not only improves unlearning effectiveness but also reduces computational overhead. Moreover, we propose an adaptive adjustment strategy for our unlearning penalty coefficient to adaptively balance forgetting quality and predictive performance during training, eliminating the need for empirical hyperparameter tuning. Unlike traditional MU methods that identify only a single unlearning model, MCU uncovers a spectrum of unlearning models along the pathway. Overall, MCU serves as a plug-and-play framework that seamlessly integrates with any existing MU methods, consistently improving unlearning efficacy. Extensive experiments on the image classification task demonstrate that MCU achieves superior performance.
Latent Manifold Reconstruction and Representation with Topological and Geometrical Regularization
May 07, 2025
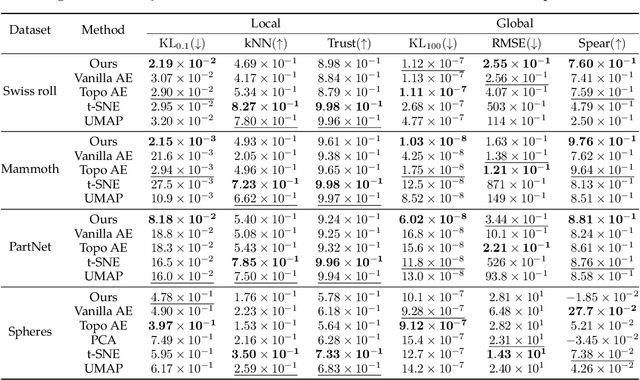


Manifold learning aims to discover and represent low-dimensional structures underlying high-dimensional data while preserving critical topological and geometric properties. Existing methods often fail to capture local details with global topological integrity from noisy data or construct a balanced dimensionality reduction, resulting in distorted or fractured embeddings. We present an AutoEncoder-based method that integrates a manifold reconstruction layer, which uncovers latent manifold structures from noisy point clouds, and further provides regularizations on topological and geometric properties during dimensionality reduction, whereas the two components promote each other during training. Experiments on point cloud datasets demonstrate that our method outperforms baselines like t-SNE, UMAP, and Topological AutoEncoders in discovering manifold structures from noisy data and preserving them through dimensionality reduction, as validated by visualization and quantitative metrics. This work demonstrates the significance of combining manifold reconstruction with manifold learning to achieve reliable representation of the latent manifold, particularly when dealing with noisy real-world data. Code repository: https://github.com/Thanatorika/mrtg.
HODDI: A Dataset of High-Order Drug-Drug Interactions for Computational Pharmacovigilance
Feb 10, 2025
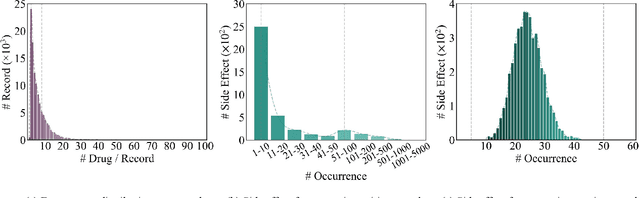
Drug-side effect research is vital for understanding adverse reactions arising in complex multi-drug therapies. However, the scarcity of higher-order datasets that capture the combinatorial effects of multiple drugs severely limits progress in this field. Existing resources such as TWOSIDES primarily focus on pairwise interactions. To fill this critical gap, we introduce HODDI, the first Higher-Order Drug-Drug Interaction Dataset, constructed from U.S. Food and Drug Administration (FDA) Adverse Event Reporting System (FAERS) records spanning the past decade, to advance computational pharmacovigilance. HODDI contains 109,744 records involving 2,506 unique drugs and 4,569 unique side effects, specifically curated to capture multi-drug interactions and their collective impact on adverse effects. Comprehensive statistical analyses demonstrate HODDI's extensive coverage and robust analytical metrics, making it a valuable resource for studying higher-order drug relationships. Evaluating HODDI with multiple models, we found that simple Multi-Layer Perceptron (MLP) can outperform graph models, while hypergraph models demonstrate superior performance in capturing complex multi-drug interactions, further validating HODDI's effectiveness. Our findings highlight the inherent value of higher-order information in drug-side effect prediction and position HODDI as a benchmark dataset for advancing research in pharmacovigilance, drug safety, and personalized medicine. The dataset and codes are available at https://github.com/TIML-Group/HODDI.
EvoAgent: Agent Autonomous Evolution with Continual World Model for Long-Horizon Tasks
Feb 09, 2025



Completing Long-Horizon (LH) tasks in open-ended worlds is an important yet difficult problem for embodied agents. Existing approaches suffer from two key challenges: (1) they heavily rely on experiences obtained from human-created data or curricula, lacking the ability to continuously update multimodal experiences, and (2) they may encounter catastrophic forgetting issues when faced with new tasks, lacking the ability to continuously update world knowledge. To solve these challenges, this paper presents EvoAgent, an autonomous-evolving agent with a continual World Model (WM), which can autonomously complete various LH tasks across environments through self-planning, self-control, and self-reflection, without human intervention. Our proposed EvoAgent contains three modules, i.e., i) the memory-driven planner which uses an LLM along with the WM and interaction memory, to convert LH tasks into executable sub-tasks; ii) the WM-guided action controller which leverages WM to generate low-level actions and incorporates a self-verification mechanism to update multimodal experiences; iii) the experience-inspired reflector which implements a two-stage curriculum learning algorithm to select experiences for task-adaptive WM updates. Moreover, we develop a continual World Model for EvoAgent, which can continuously update the multimodal experience pool and world knowledge through closed-loop dynamics. We conducted extensive experiments on Minecraft, compared with existing methods, EvoAgent can achieve an average success rate improvement of 105% and reduce ineffective actions by more than 6x.
Redefining Machine Unlearning: A Conformal Prediction-Motivated Approach
Jan 31, 2025



Machine unlearning seeks to systematically remove specified data from a trained model, effectively achieving a state as though the data had never been encountered during training. While metrics such as Unlearning Accuracy (UA) and Membership Inference Attack (MIA) provide a baseline for assessing unlearning performance, they fall short of evaluating the completeness and reliability of forgetting. This is because the ground truth labels remain potential candidates within the scope of uncertainty quantification, leaving gaps in the evaluation of true forgetting. In this paper, we identify critical limitations in existing unlearning metrics and propose enhanced evaluation metrics inspired by conformal prediction. Our metrics can effectively capture the extent to which ground truth labels are excluded from the prediction set. Furthermore, we observe that many existing machine unlearning methods do not achieve satisfactory forgetting performance when evaluated with our new metrics. To address this, we propose an unlearning framework that integrates conformal prediction insights into Carlini & Wagner adversarial attack loss. Extensive experiments on the image classification task demonstrate that our enhanced metrics offer deeper insights into unlearning effectiveness, and that our unlearning framework significantly improves the forgetting quality of unlearning methods.
Boosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Jan 15, 2025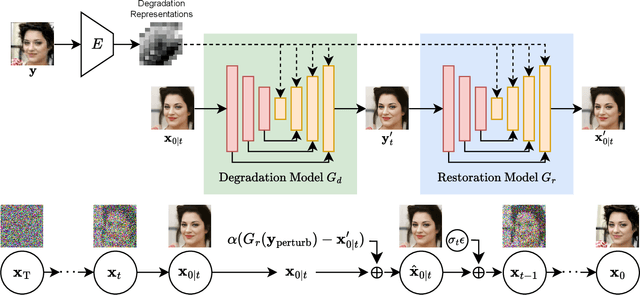


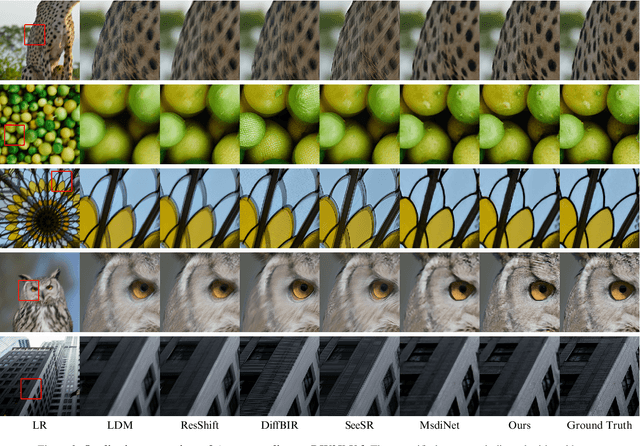
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we introduce degradation-aware models that can be integrated into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques input perturbation and guidance scalar to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks
Watermarking Graph Neural Networks via Explanations for Ownership Protection
Jan 09, 2025Graph Neural Networks (GNNs) are the mainstream method to learn pervasive graph data and are widely deployed in industry, making their intellectual property valuable. However, protecting GNNs from unauthorized use remains a challenge. Watermarking, which embeds ownership information into a model, is a potential solution. However, existing watermarking methods have two key limitations: First, almost all of them focus on non-graph data, with watermarking GNNs for complex graph data largely unexplored. Second, the de facto backdoor-based watermarking methods pollute training data and induce ownership ambiguity through intentional misclassification. Our explanation-based watermarking inherits the strengths of backdoor-based methods (e.g., robust to watermark removal attacks), but avoids data pollution and eliminates intentional misclassification. In particular, our method learns to embed the watermark in GNN explanations such that this unique watermark is statistically distinct from other potential solutions, and ownership claims must show statistical significance to be verified. We theoretically prove that, even with full knowledge of our method, locating the watermark is an NP-hard problem. Empirically, our method manifests robustness to removal attacks like fine-tuning and pruning. By addressing these challenges, our approach marks a significant advancement in protecting GNN intellectual property.
Forget Vectors at Play: Universal Input Perturbations Driving Machine Unlearning in Image Classification
Dec 21, 2024



Machine unlearning (MU), which seeks to erase the influence of specific unwanted data from already-trained models, is becoming increasingly vital in model editing, particularly to comply with evolving data regulations like the ``right to be forgotten''. Conventional approaches are predominantly model-based, typically requiring retraining or fine-tuning the model's weights to meet unlearning requirements. In this work, we approach the MU problem from a novel input perturbation-based perspective, where the model weights remain intact throughout the unlearning process. We demonstrate the existence of a proactive input-based unlearning strategy, referred to forget vector, which can be generated as an input-agnostic data perturbation and remains as effective as model-based approximate unlearning approaches. We also explore forget vector arithmetic, whereby multiple class-specific forget vectors are combined through simple operations (e.g., linear combinations) to generate new forget vectors for unseen unlearning tasks, such as forgetting arbitrary subsets across classes. Extensive experiments validate the effectiveness and adaptability of the forget vector, showcasing its competitive performance relative to state-of-the-art model-based methods. Codes are available at https://github.com/Changchangsun/Forget-Vector.
Efficient and Robust Continual Graph Learning for Graph Classification in Biology
Nov 18, 2024



Graph classification is essential for understanding complex biological systems, where molecular structures and interactions are naturally represented as graphs. Traditional graph neural networks (GNNs) perform well on static tasks but struggle in dynamic settings due to catastrophic forgetting. We present Perturbed and Sparsified Continual Graph Learning (PSCGL), a robust and efficient continual graph learning framework for graph data classification, specifically targeting biological datasets. We introduce a perturbed sampling strategy to identify critical data points that contribute to model learning and a motif-based graph sparsification technique to reduce storage needs while maintaining performance. Additionally, our PSCGL framework inherently defends against graph backdoor attacks, which is crucial for applications in sensitive biological contexts. Extensive experiments on biological datasets demonstrate that PSCGL not only retains knowledge across tasks but also enhances the efficiency and robustness of graph classification models in biology.