 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Variational Contrastive Learning
Jun 11, 2025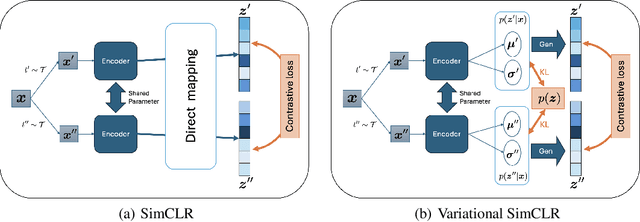

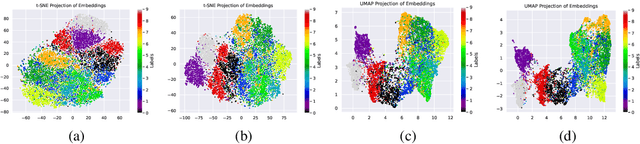
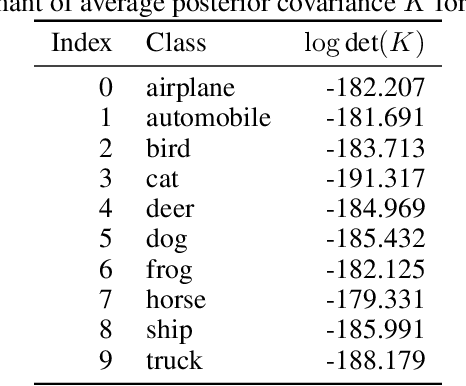
Deterministic embeddings learned by contrastive learning (CL) methods such as SimCLR and SupCon achieve state-of-the-art performance but lack a principled mechanism for uncertainty quantification. We propose Variational Contrastive Learning (VCL), a decoder-free framework that maximizes the evidence lower bound (ELBO) by interpreting the InfoNCE loss as a surrogate reconstruction term and adding a KL divergence regularizer to a uniform prior on the unit hypersphere. We model the approximate posterior $q_\theta(z|x)$ as a projected normal distribution, enabling the sampling of probabilistic embeddings. Our two instantiations--VSimCLR and VSupCon--replace deterministic embeddings with samples from $q_\theta(z|x)$ and incorporate a normalized KL term into the loss. Experiments on multiple benchmarks demonstrate that VCL mitigates dimensional collapse, enhances mutual information with class labels, and matches or outperforms deterministic baselines in classification accuracy, all the while providing meaningful uncertainty estimates through the posterior model. VCL thus equips contrastive learning with a probabilistic foundation, serving as a new basis for contrastive approaches.
Generalizing Supervised Contrastive learning: A Projection Perspective
Jun 11, 2025Self-supervised contrastive learning (SSCL) has emerged as a powerful paradigm for representation learning and has been studied from multiple perspectives, including mutual information and geometric viewpoints. However, supervised contrastive (SupCon) approaches have received comparatively little attention in this context: for instance, while InfoNCE used in SSCL is known to form a lower bound on mutual information (MI), the relationship between SupCon and MI remains unexplored. To address this gap, we introduce ProjNCE, a generalization of the InfoNCE loss that unifies supervised and self-supervised contrastive objectives by incorporating projection functions and an adjustment term for negative pairs. We prove that ProjNCE constitutes a valid MI bound and affords greater flexibility in selecting projection strategies for class embeddings. Building on this flexibility, we further explore the centroid-based class embeddings in SupCon by exploring a variety of projection methods. Extensive experiments on multiple datasets and settings demonstrate that ProjNCE consistently outperforms both SupCon and standard cross-entropy training. Our work thus refines SupCon along two complementary perspective--mutual information interpretation and projection design--and offers broadly applicable improvements whenever SupCon serves as the foundational contrastive objective.
Hierarchical Sparse Bayesian Multitask Model with Scalable Inference for Microbiome Analysis
Feb 04, 2025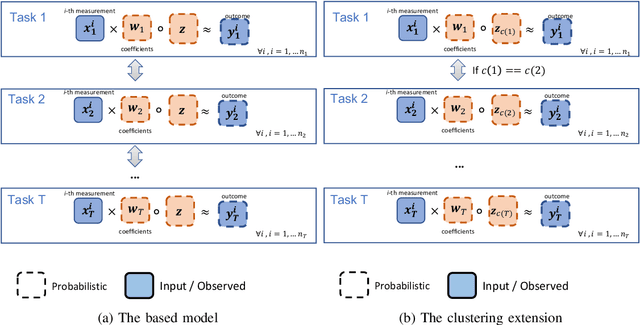
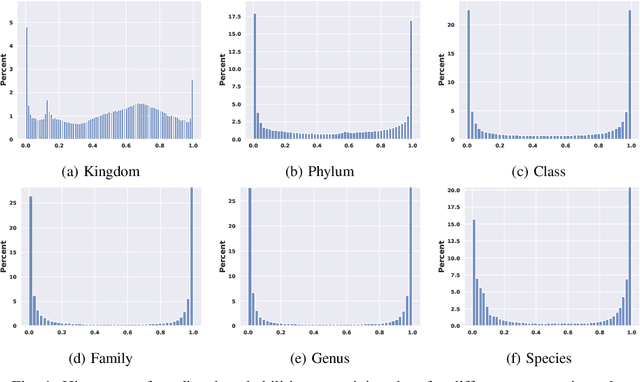
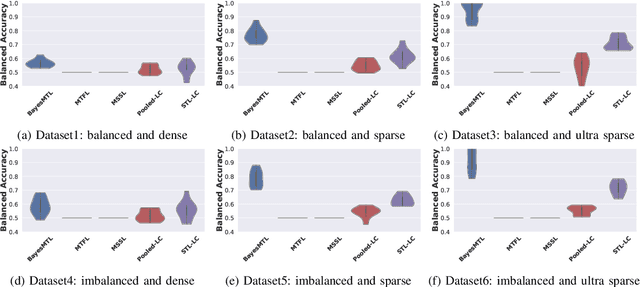
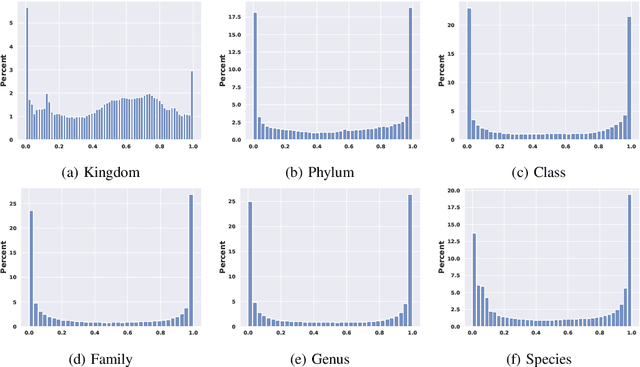
This paper proposes a hierarchical Bayesian multitask learning model that is applicable to the general multi-task binary classification learning problem where the model assumes a shared sparsity structure across different tasks. We derive a computationally efficient inference algorithm based on variational inference to approximate the posterior distribution. We demonstrate the potential of the new approach on various synthetic datasets and for predicting human health status based on microbiome profile. Our analysis incorporates data pooled from multiple microbiome studies, along with a comprehensive comparison with other benchmark methods. Results in synthetic datasets show that the proposed approach has superior support recovery property when the underlying regression coefficients share a common sparsity structure across different tasks. Our experiments on microbiome classification demonstrate the utility of the method in extracting informative taxa while providing well-calibrated predictions with uncertainty quantification and achieving competitive performance in terms of prediction metrics. Notably, despite the heterogeneity of the pooled datasets (e.g., different experimental objectives, laboratory setups, sequencing equipment, patient demographics), our method delivers robust results.
Anchors Aweigh! Sail for Optimal Unified Multi-Modal Representations
Oct 02, 2024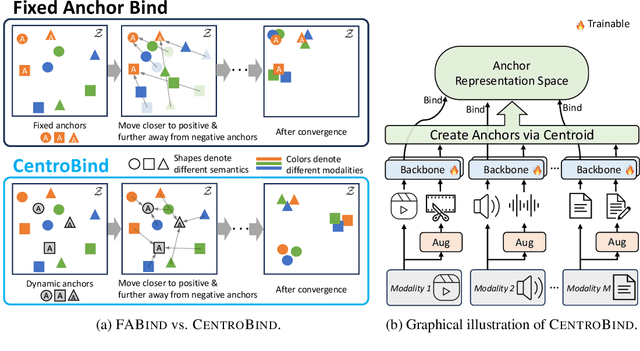
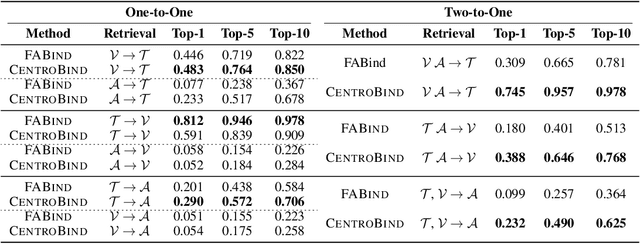
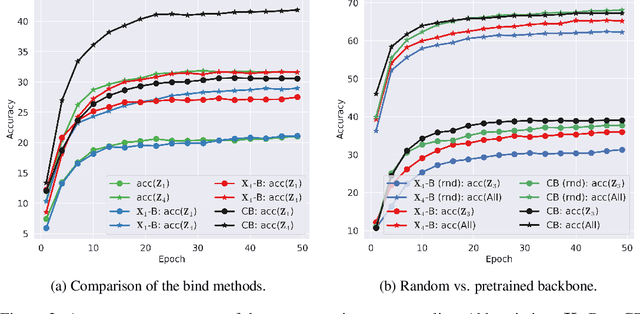
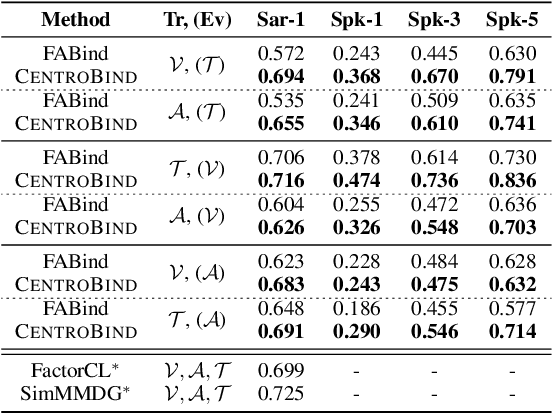
Multimodal learning plays a crucial role in enabling machine learning models to fuse and utilize diverse data sources, such as text, images, and audio, to support a variety of downstream tasks. A unified representation across various modalities is particularly important for improving efficiency and performance. Recent binding methods, such as ImageBind (Girdhar et al., 2023), typically use a fixed anchor modality to align multimodal data in the anchor modal embedding space. In this paper, we mathematically analyze the fixed anchor binding methods and uncover notable limitations: (1) over-reliance on the choice of the anchor modality, (2) failure to capture intra-modal information, and (3) failure to account for inter-modal correlation among non-anchored modalities. To address these limitations, we propose CentroBind, a simple yet powerful approach that eliminates the need for a fixed anchor; instead, it employs dynamically adjustable centroid-based anchors generated from all available modalities, resulting in a balanced and rich representation space. We theoretically demonstrate that our method captures three crucial properties of multimodal learning: intra-modal learning, inter-modal learning, and multimodal alignment, while also constructing a robust unified representation across all modalities. Our experiments on both synthetic and real-world datasets demonstrate the superiority of the proposed method, showing that dynamic anchor methods outperform all fixed anchor binding methods as the former captures more nuanced multimodal interactions.
Deep Adversarial Defense Against Multilevel-Lp Attacks
Jul 12, 2024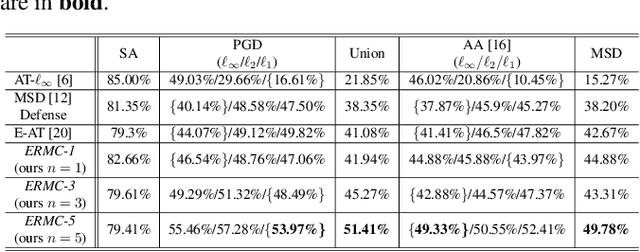
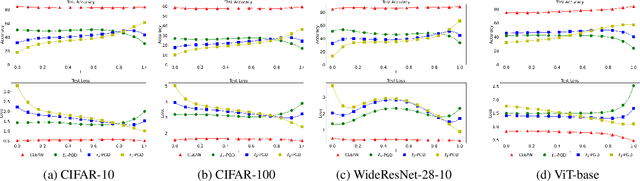
Deep learning models have shown considerable vulnerability to adversarial attacks, particularly as attacker strategies become more sophisticated. While traditional adversarial training (AT) techniques offer some resilience, they often focus on defending against a single type of attack, e.g., the $\ell_\infty$-norm attack, which can fail for other types. This paper introduces a computationally efficient multilevel $\ell_p$ defense, called the Efficient Robust Mode Connectivity (EMRC) method, which aims to enhance a deep learning model's resilience against multiple $\ell_p$-norm attacks. Similar to analytical continuation approaches used in continuous optimization, the method blends two $p$-specific adversarially optimal models, the $\ell_1$- and $\ell_\infty$-norm AT solutions, to provide good adversarial robustness for a range of $p$. We present experiments demonstrating that our approach performs better on various attacks as compared to AT-$\ell_\infty$, E-AT, and MSD, for datasets/architectures including: CIFAR-10, CIFAR-100 / PreResNet110, WideResNet, ViT-Base.
Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning
Mar 12, 2024The trustworthy machine learning (ML) community is increasingly recognizing the crucial need for models capable of selectively 'unlearning' data points after training. This leads to the problem of machine unlearning (MU), aiming to eliminate the influence of chosen data points on model performance, while still maintaining the model's utility post-unlearning. Despite various MU methods for data influence erasure, evaluations have largely focused on random data forgetting, ignoring the vital inquiry into which subset should be chosen to truly gauge the authenticity of unlearning performance. To tackle this issue, we introduce a new evaluative angle for MU from an adversarial viewpoint. We propose identifying the data subset that presents the most significant challenge for influence erasure, i.e., pinpointing the worst-case forget set. Utilizing a bi-level optimization principle, we amplify unlearning challenges at the upper optimization level to emulate worst-case scenarios, while simultaneously engaging in standard training and unlearning at the lower level, achieving a balance between data influence erasure and model utility. Our proposal offers a worst-case evaluation of MU's resilience and effectiveness. Through extensive experiments across different datasets (including CIFAR-10, 100, CelebA, Tiny ImageNet, and ImageNet) and models (including both image classifiers and generative models), we expose critical pros and cons in existing (approximate) unlearning strategies. Our results illuminate the complex challenges of MU in practice, guiding the future development of more accurate and robust unlearning algorithms. The code is available at https://github.com/OPTML-Group/Unlearn-WorstCase.
Gradient Coding through Iterative Block Leverage Score Sampling
Aug 06, 2023



We generalize the leverage score sampling sketch for $\ell_2$-subspace embeddings, to accommodate sampling subsets of the transformed data, so that the sketching approach is appropriate for distributed settings. This is then used to derive an approximate coded computing approach for first-order methods; known as gradient coding, to accelerate linear regression in the presence of failures in distributed computational networks, \textit{i.e.} stragglers. We replicate the data across the distributed network, to attain the approximation guarantees through the induced sampling distribution. The significance and main contribution of this work, is that it unifies randomized numerical linear algebra with approximate coded computing, while attaining an induced $\ell_2$-subspace embedding through uniform sampling. The transition to uniform sampling is done without applying a random projection, as in the case of the subsampled randomized Hadamard transform. Furthermore, by incorporating this technique to coded computing, our scheme is an iterative sketching approach to approximately solving linear regression. We also propose weighting when sketching takes place through sampling with replacement, for further compression.
Minimum-Risk Recalibration of Classifiers
May 18, 2023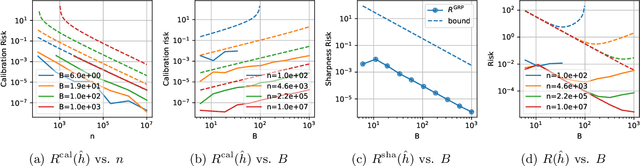

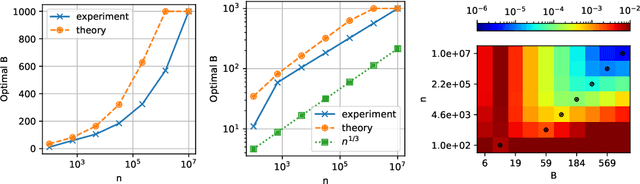
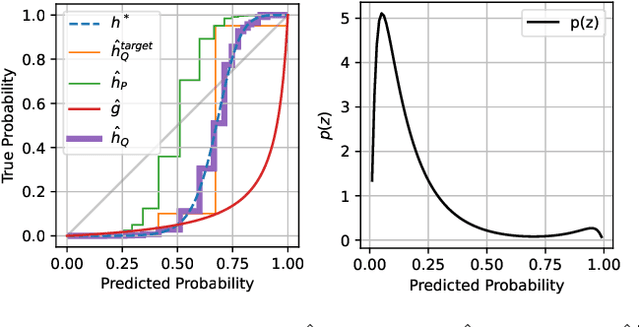
Recalibrating probabilistic classifiers is vital for enhancing the reliability and accuracy of predictive models. Despite the development of numerous recalibration algorithms, there is still a lack of a comprehensive theory that integrates calibration and sharpness (which is essential for maintaining predictive power). In this paper, we introduce the concept of minimum-risk recalibration within the framework of mean-squared-error (MSE) decomposition, offering a principled approach for evaluating and recalibrating probabilistic classifiers. Using this framework, we analyze the uniform-mass binning (UMB) recalibration method and establish a finite-sample risk upper bound of order $\tilde{O}(B/n + 1/B^2)$ where $B$ is the number of bins and $n$ is the sample size. By balancing calibration and sharpness, we further determine that the optimal number of bins for UMB scales with $n^{1/3}$, resulting in a risk bound of approximately $O(n^{-2/3})$. Additionally, we tackle the challenge of label shift by proposing a two-stage approach that adjusts the recalibration function using limited labeled data from the target domain. Our results show that transferring a calibrated classifier requires significantly fewer target samples compared to recalibrating from scratch. We validate our theoretical findings through numerical simulations, which confirm the tightness of the proposed bounds, the optimal number of bins, and the effectiveness of label shift adaptation.
Robustness-preserving Lifelong Learning via Dataset Condensation
Mar 07, 2023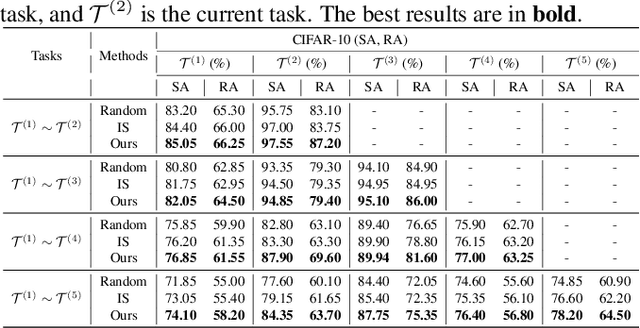
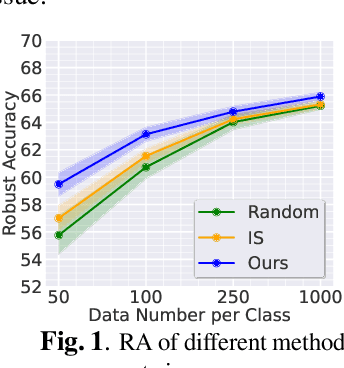
Lifelong learning (LL) aims to improve a predictive model as the data source evolves continuously. Most work in this learning paradigm has focused on resolving the problem of 'catastrophic forgetting,' which refers to a notorious dilemma between improving model accuracy over new data and retaining accuracy over previous data. Yet, it is also known that machine learning (ML) models can be vulnerable in the sense that tiny, adversarial input perturbations can deceive the models into producing erroneous predictions. This motivates the research objective of this paper - specification of a new LL framework that can salvage model robustness (against adversarial attacks) from catastrophic forgetting. Specifically, we propose a new memory-replay LL strategy that leverages modern bi-level optimization techniques to determine the 'coreset' of the current data (i.e., a small amount of data to be memorized) for ease of preserving adversarial robustness over time. We term the resulting LL framework 'Data-Efficient Robustness-Preserving LL' (DERPLL). The effectiveness of DERPLL is evaluated for class-incremental image classification using ResNet-18 over the CIFAR-10 dataset. Experimental results show that DERPLL outperforms the conventional coreset-guided LL baseline and achieves a substantial improvement in both standard accuracy and robust accuracy.
Incorporating Polar Field Data for Improved Solar Flare Prediction
Dec 04, 2022In this paper, we consider incorporating data associated with the sun's north and south polar field strengths to improve solar flare prediction performance using machine learning models. When used to supplement local data from active regions on the photospheric magnetic field of the sun, the polar field data provides global information to the predictor. While such global features have been previously proposed for predicting the next solar cycle's intensity, in this paper we propose using them to help classify individual solar flares. We conduct experiments using HMI data employing four different machine learning algorithms that can exploit polar field information. Additionally, we propose a novel probabilistic mixture of experts model that can simply and effectively incorporate polar field data and provide on-par prediction performance with state-of-the-art solar flare prediction algorithms such as the Recurrent Neural Network (RNN). Our experimental results indicate the usefulness of the polar field data for solar flare prediction, which can improve Heidke Skill Score (HSS2) by as much as 10.1%.