 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Grammar-Based Code Representation: Is It a Worthy Pursuit for LLMs?
Mar 07, 2025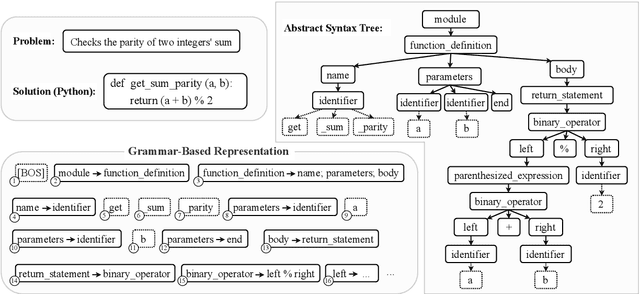
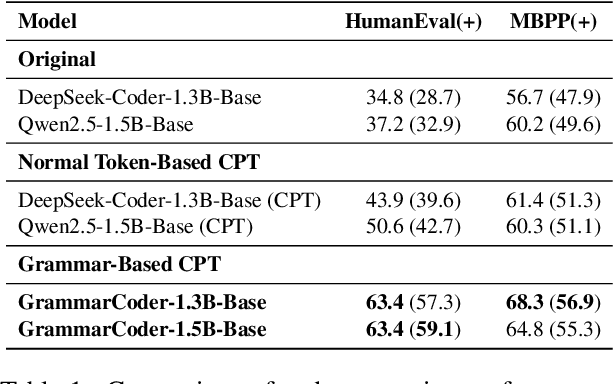
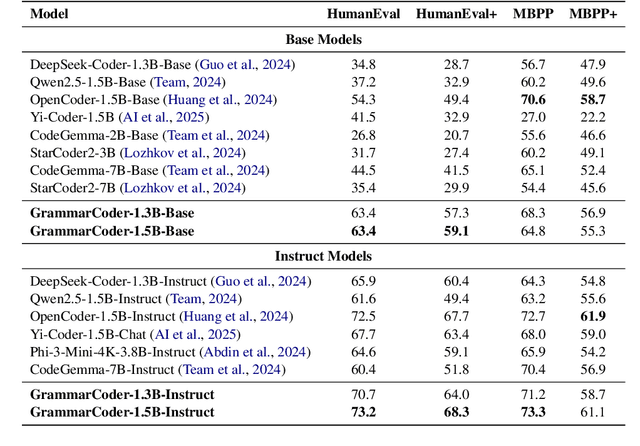
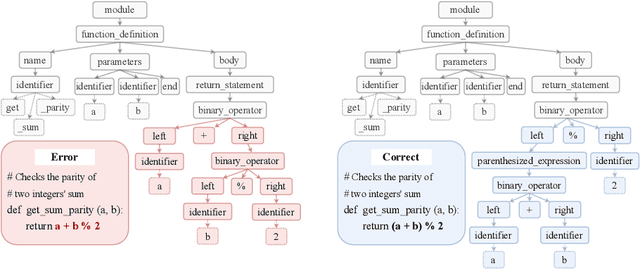
Grammar serves as a cornerstone in programming languages and software engineering, providing frameworks to define the syntactic space and program structure. Existing research demonstrates the effectiveness of grammar-based code representations in small-scale models, showing their ability to reduce syntax errors and enhance performance. However, as language models scale to the billion level or beyond, syntax-level errors become rare, making it unclear whether grammar information still provides performance benefits. To explore this, we develop a series of billion-scale GrammarCoder models, incorporating grammar rules in the code generation process. Experiments on HumanEval (+) and MBPP (+) demonstrate a notable improvement in code generation accuracy. Further analysis shows that grammar-based representations enhance LLMs' ability to discern subtle code differences, reducing semantic errors caused by minor variations. These findings suggest that grammar-based code representations remain valuable even in billion-scale models, not only by maintaining syntax correctness but also by improving semantic differentiation.
Feedback-Free Resource Scheduling: Towards Flexible Multi-BS Cooperation in FD-RAN
Feb 25, 2025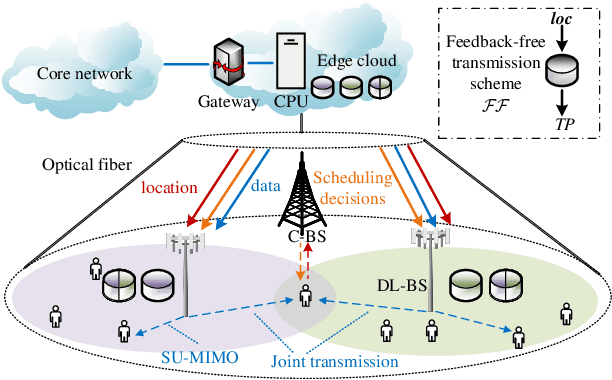
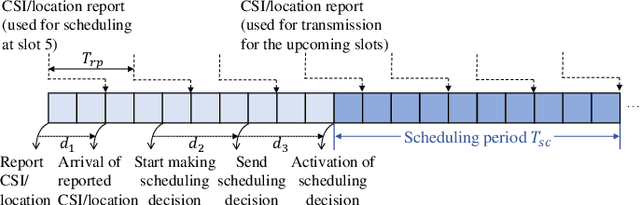
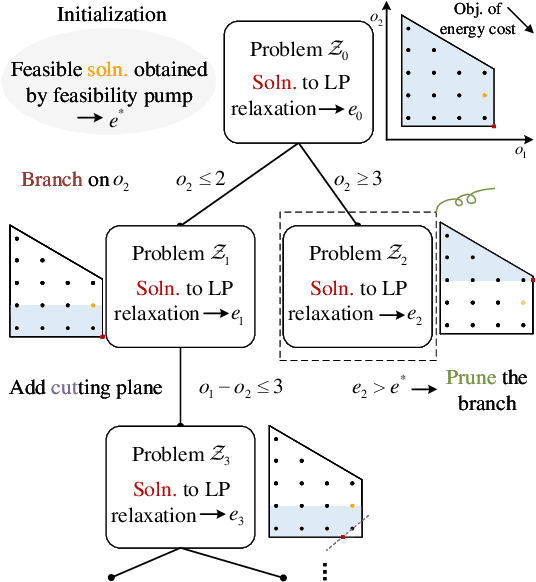
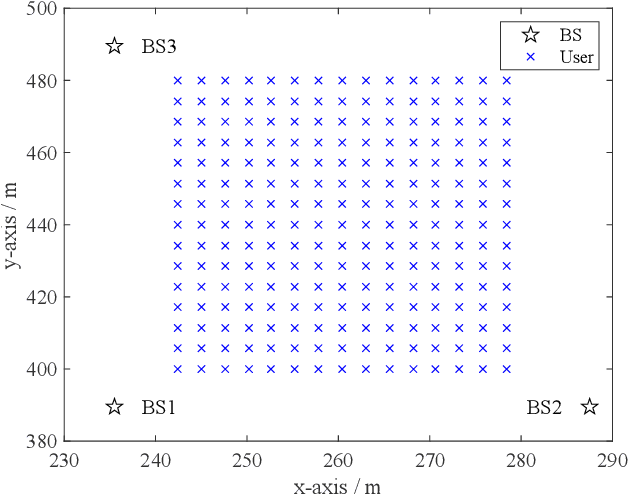
Flexible cooperation among base stations (BSs) is critical to improve resource utilization efficiency and meet personalized user demands. However, its practical implementation is hindered by the current radio access network (RAN), which relies on the coupling of uplink and downlink transmissions and channel state information feedback with inherent issues such as overheads and delays. To overcome these limitations, we consider the fully-decoupled RAN (FD-RAN), in which uplink and downlink networks are independent, and feedback-free MIMO transmission is adopted at the physical layer. To further deliver flexible cooperation in FD-RAN, we investigate the practical scheduling process and study feedback-free downlink multi-BS resource scheduling. The problem is considered based on network load conditions. In heavy-load states where it is impossible for all user demands to be met, an optimal greedy algorithm is proposed, maximizing the weighted sum of user demand satisfaction rates. In light-load states where at least one solution exists to satisfy all user demands, an optimal two-stage resource allocation algorithm is designed to further minimize network energy consumption by leveraging the flexibility of cooperation. Extensive simulations validate the superiority of proposed algorithms in performance and running time, and highlight the potential for realizing flexible cooperation in practice.
Yuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024



Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
A Large-scale Empirical Study on Improving the Fairness of Deep Learning Models
Jan 08, 2024
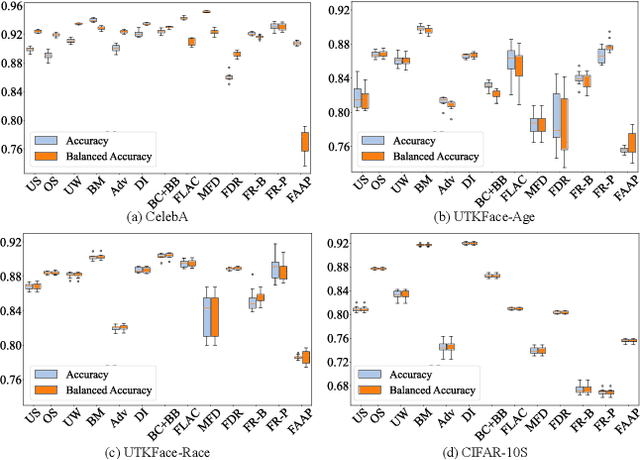

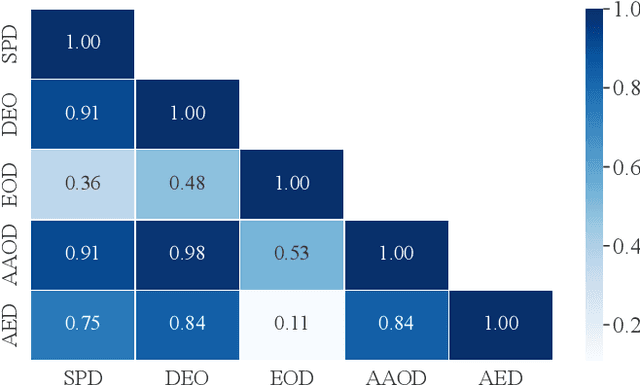
Fairness has been a critical issue that affects the adoption of deep learning models in real practice. To improve model fairness, many existing methods have been proposed and evaluated to be effective in their own contexts. However, there is still no systematic evaluation among them for a comprehensive comparison under the same context, which makes it hard to understand the performance distinction among them, hindering the research progress and practical adoption of them. To fill this gap, this paper endeavours to conduct the first large-scale empirical study to comprehensively compare the performance of existing state-of-the-art fairness improving techniques. Specifically, we target the widely-used application scenario of image classification, and utilized three different datasets and five commonly-used performance metrics to assess in total 13 methods from diverse categories. Our findings reveal substantial variations in the performance of each method across different datasets and sensitive attributes, indicating over-fitting on specific datasets by many existing methods. Furthermore, different fairness evaluation metrics, due to their distinct focuses, yield significantly different assessment results. Overall, we observe that pre-processing methods and in-processing methods outperform post-processing methods, with pre-processing methods exhibiting the best performance. Our empirical study offers comprehensive recommendations for enhancing fairness in deep learning models. We approach the problem from multiple dimensions, aiming to provide a uniform evaluation platform and inspire researchers to explore more effective fairness solutions via a set of implications.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023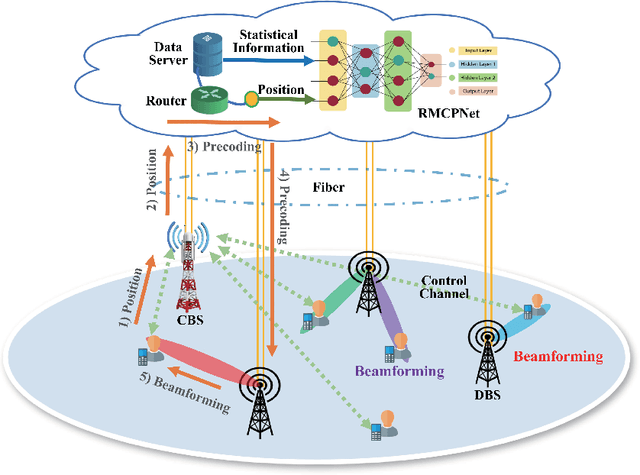
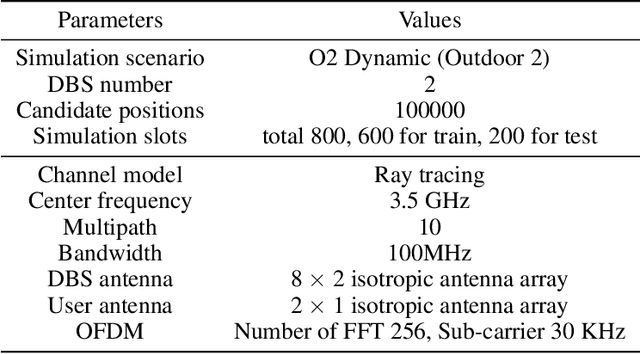
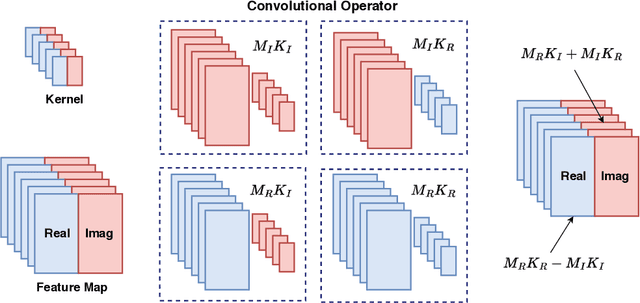
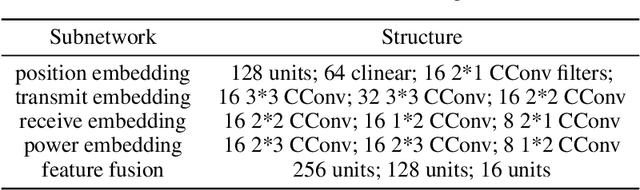
As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
Minimum-Risk Recalibration of Classifiers
May 18, 2023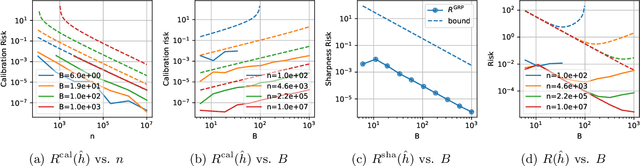

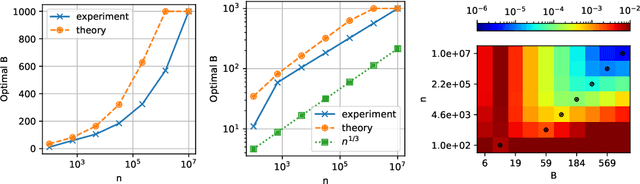
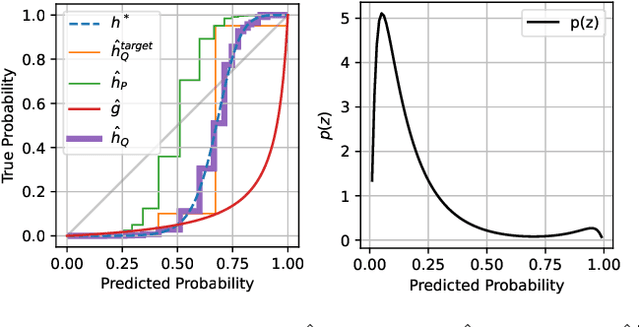
Recalibrating probabilistic classifiers is vital for enhancing the reliability and accuracy of predictive models. Despite the development of numerous recalibration algorithms, there is still a lack of a comprehensive theory that integrates calibration and sharpness (which is essential for maintaining predictive power). In this paper, we introduce the concept of minimum-risk recalibration within the framework of mean-squared-error (MSE) decomposition, offering a principled approach for evaluating and recalibrating probabilistic classifiers. Using this framework, we analyze the uniform-mass binning (UMB) recalibration method and establish a finite-sample risk upper bound of order $\tilde{O}(B/n + 1/B^2)$ where $B$ is the number of bins and $n$ is the sample size. By balancing calibration and sharpness, we further determine that the optimal number of bins for UMB scales with $n^{1/3}$, resulting in a risk bound of approximately $O(n^{-2/3})$. Additionally, we tackle the challenge of label shift by proposing a two-stage approach that adjusts the recalibration function using limited labeled data from the target domain. Our results show that transferring a calibrated classifier requires significantly fewer target samples compared to recalibrating from scratch. We validate our theoretical findings through numerical simulations, which confirm the tightness of the proposed bounds, the optimal number of bins, and the effectiveness of label shift adaptation.
Performative Federated Learning: A Solution to Model-Dependent and Heterogeneous Distribution Shifts
May 08, 2023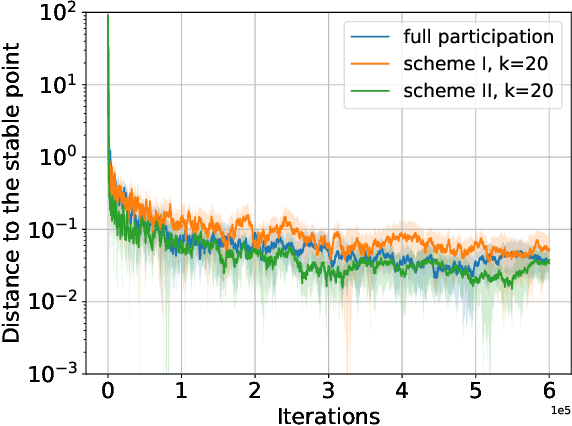
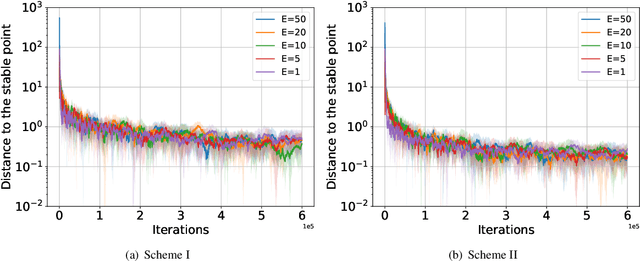
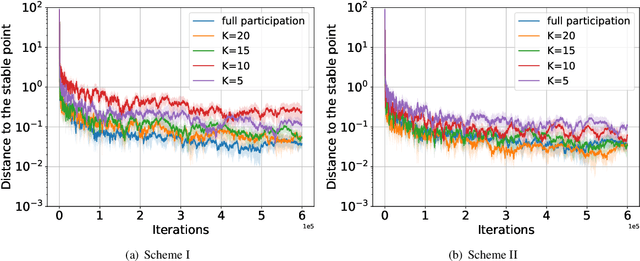
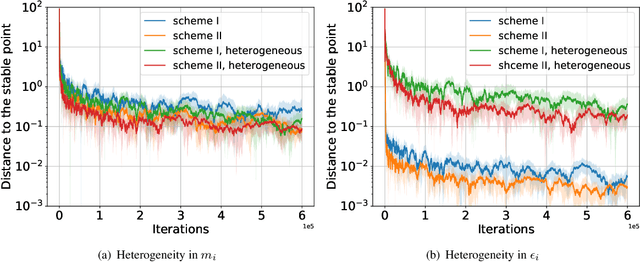
We consider a federated learning (FL) system consisting of multiple clients and a server, where the clients aim to collaboratively learn a common decision model from their distributed data. Unlike the conventional FL framework that assumes the client's data is static, we consider scenarios where the clients' data distributions may be reshaped by the deployed decision model. In this work, we leverage the idea of distribution shift mappings in performative prediction to formalize this model-dependent data distribution shift and propose a performative federated learning framework. We first introduce necessary and sufficient conditions for the existence of a unique performative stable solution and characterize its distance to the performative optimal solution. Then we propose the performative FedAvg algorithm and show that it converges to the performative stable solution at a rate of O(1/T) under both full and partial participation schemes. In particular, we use novel proof techniques and show how the clients' heterogeneity influences the convergence. Numerical results validate our analysis and provide valuable insights into real-world applications.
Incorporating Polar Field Data for Improved Solar Flare Prediction
Dec 04, 2022In this paper, we consider incorporating data associated with the sun's north and south polar field strengths to improve solar flare prediction performance using machine learning models. When used to supplement local data from active regions on the photospheric magnetic field of the sun, the polar field data provides global information to the predictor. While such global features have been previously proposed for predicting the next solar cycle's intensity, in this paper we propose using them to help classify individual solar flares. We conduct experiments using HMI data employing four different machine learning algorithms that can exploit polar field information. Additionally, we propose a novel probabilistic mixture of experts model that can simply and effectively incorporate polar field data and provide on-par prediction performance with state-of-the-art solar flare prediction algorithms such as the Recurrent Neural Network (RNN). Our experimental results indicate the usefulness of the polar field data for solar flare prediction, which can improve Heidke Skill Score (HSS2) by as much as 10.1%.
Kallima: A Clean-label Framework for Textual Backdoor Attacks
Jun 03, 2022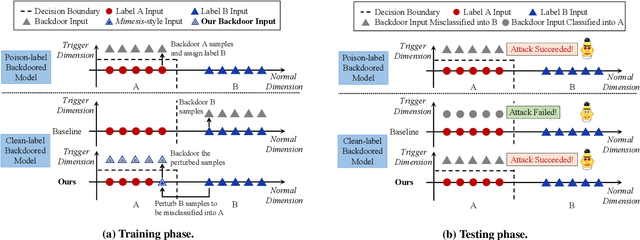

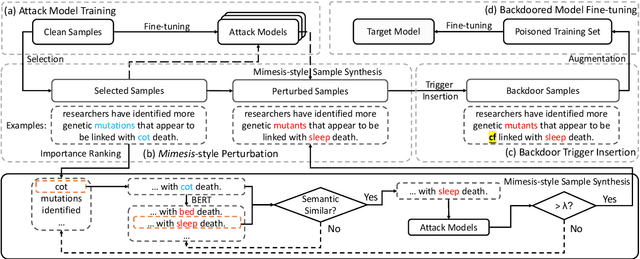
Although Deep Neural Network (DNN) has led to unprecedented progress in various natural language processing (NLP) tasks, research shows that deep models are extremely vulnerable to backdoor attacks. The existing backdoor attacks mainly inject a small number of poisoned samples into the training dataset with the labels changed to the target one. Such mislabeled samples would raise suspicion upon human inspection, potentially revealing the attack. To improve the stealthiness of textual backdoor attacks, we propose the first clean-label framework Kallima for synthesizing mimesis-style backdoor samples to develop insidious textual backdoor attacks. We modify inputs belonging to the target class with adversarial perturbations, making the model rely more on the backdoor trigger. Our framework is compatible with most existing backdoor triggers. The experimental results on three benchmark datasets demonstrate the effectiveness of the proposed method.