 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasCause: Evaluate Socially Biased Causal Reasoning of Large Language Models
Apr 08, 2025While large language models (LLMs) already play significant roles in society, research has shown that LLMs still generate content including social bias against certain sensitive groups. While existing benchmarks have effectively identified social biases in LLMs, a critical gap remains in our understanding of the underlying reasoning that leads to these biased outputs. This paper goes one step further to evaluate the causal reasoning process of LLMs when they answer questions eliciting social biases. We first propose a novel conceptual framework to classify the causal reasoning produced by LLMs. Next, we use LLMs to synthesize $1788$ questions covering $8$ sensitive attributes and manually validate them. The questions can test different kinds of causal reasoning by letting LLMs disclose their reasoning process with causal graphs. We then test 4 state-of-the-art LLMs. All models answer the majority of questions with biased causal reasoning, resulting in a total of $4135$ biased causal graphs. Meanwhile, we discover $3$ strategies for LLMs to avoid biased causal reasoning by analyzing the "bias-free" cases. Finally, we reveal that LLMs are also prone to "mistaken-biased" causal reasoning, where they first confuse correlation with causality to infer specific sensitive group names and then incorporate biased causal reasoning.
Providing Differential Privacy for Federated Learning Over Wireless: A Cross-layer Framework
Dec 05, 2024



Federated Learning (FL) is a distributed machine learning framework that inherently allows edge devices to maintain their local training data, thus providing some level of privacy. However, FL's model updates still pose a risk of privacy leakage, which must be mitigated. Over-the-air FL (OTA-FL) is an adapted FL design for wireless edge networks that leverages the natural superposition property of the wireless medium. We propose a wireless physical layer (PHY) design for OTA-FL which improves differential privacy (DP) through a decentralized, dynamic power control that utilizes both inherent Gaussian noise in the wireless channel and a cooperative jammer (CJ) for additional artificial noise generation when higher privacy levels are required. Although primarily implemented within the Upcycled-FL framework, where a resource-efficient method with first-order approximations is used at every even iteration to decrease the required information from clients, our power control strategy is applicable to any FL framework, including FedAvg and FedProx as shown in the paper. This adaptation showcases the flexibility and effectiveness of our design across different learning algorithms while maintaining a strong emphasis on privacy. Our design removes the need for client-side artificial noise injection for DP, utilizing a cooperative jammer to enhance privacy without affecting transmission efficiency for higher privacy demands. Privacy analysis is provided using the Moments Accountant method. We perform a convergence analysis for non-convex objectives to tackle heterogeneous data distributions, highlighting the inherent trade-offs between privacy and accuracy. Numerical results show that our approach with various FL algorithms outperforms the state-of-the-art under the same DP conditions on the non-i.i.d. FEMNIST dataset, and highlight the cooperative jammer's effectiveness in ensuring strict privacy.
Federated Learning with Reduced Information Leakage and Computation
Oct 10, 2023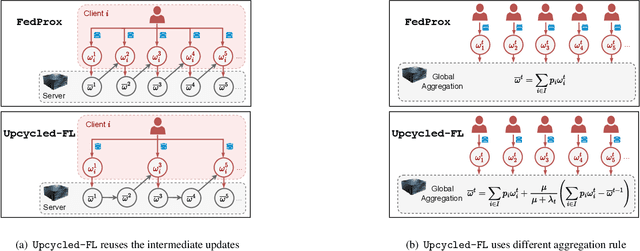
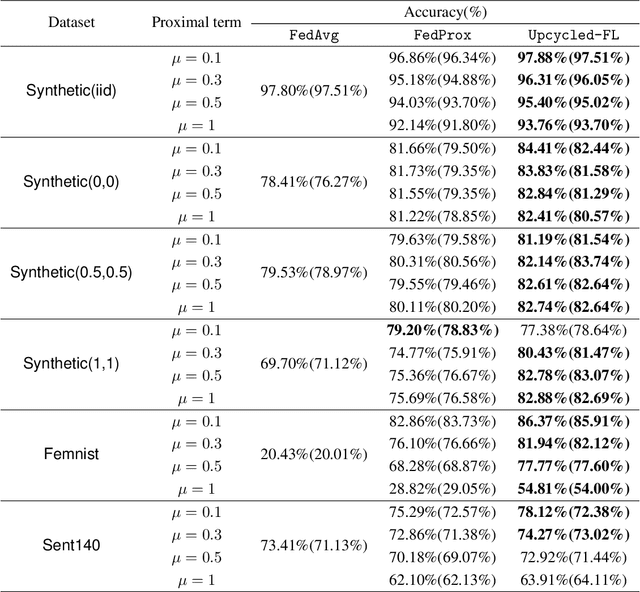
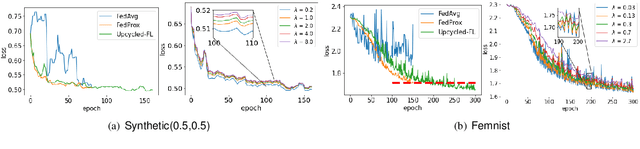
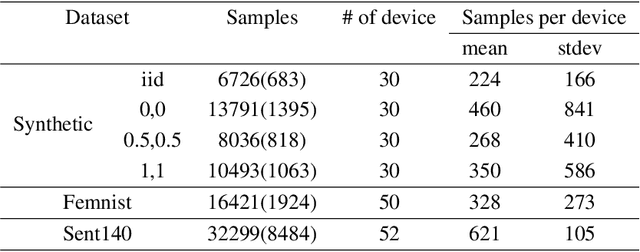
Federated learning (FL) is a distributed learning paradigm that allows multiple decentralized clients to collaboratively learn a common model without sharing local data. Although local data is not exposed directly, privacy concerns nonetheless exist as clients' sensitive information can be inferred from intermediate computations. Moreover, such information leakage accumulates substantially over time as the same data is repeatedly used during the iterative learning process. As a result, it can be particularly difficult to balance the privacy-accuracy trade-off when designing privacy-preserving FL algorithms. In this paper, we introduce Upcycled-FL, a novel federated learning framework with first-order approximation applied at every even iteration. Under this framework, half of the FL updates incur no information leakage and require much less computation. We first conduct the theoretical analysis on the convergence (rate) of Upcycled-FL, and then apply perturbation mechanisms to preserve privacy. Experiments on real-world data show that Upcycled-FL consistently outperforms existing methods over heterogeneous data, and significantly improves privacy-accuracy trade-off while reducing 48% of the training time on average.
Fair Classifiers that Abstain without Harm
Oct 09, 2023In critical applications, it is vital for classifiers to defer decision-making to humans. We propose a post-hoc method that makes existing classifiers selectively abstain from predicting certain samples. Our abstaining classifier is incentivized to maintain the original accuracy for each sub-population (i.e. no harm) while achieving a set of group fairness definitions to a user specified degree. To this end, we design an Integer Programming (IP) procedure that assigns abstention decisions for each training sample to satisfy a set of constraints. To generalize the abstaining decisions to test samples, we then train a surrogate model to learn the abstaining decisions based on the IP solutions in an end-to-end manner. We analyze the feasibility of the IP procedure to determine the possible abstention rate for different levels of unfairness tolerance and accuracy constraint for achieving no harm. To the best of our knowledge, this work is the first to identify the theoretical relationships between the constraint parameters and the required abstention rate. Our theoretical results are important since a high abstention rate is often infeasible in practice due to a lack of human resources. Our framework outperforms existing methods in terms of fairness disparity without sacrificing accuracy at similar abstention rates.
Performative Federated Learning: A Solution to Model-Dependent and Heterogeneous Distribution Shifts
May 08, 2023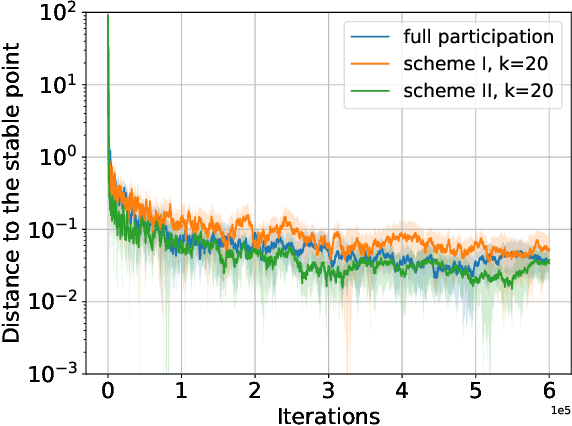
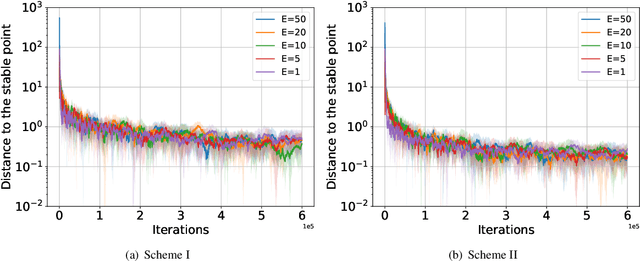
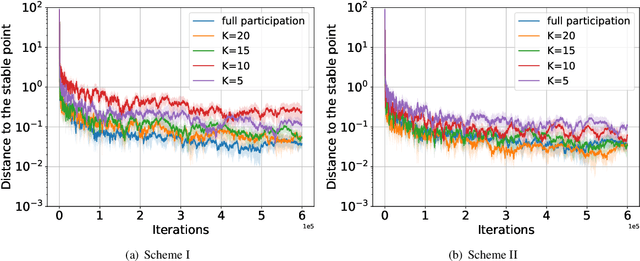
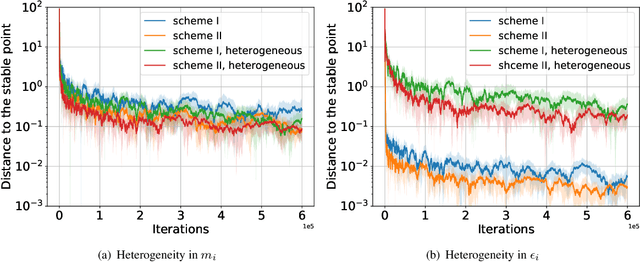
We consider a federated learning (FL) system consisting of multiple clients and a server, where the clients aim to collaboratively learn a common decision model from their distributed data. Unlike the conventional FL framework that assumes the client's data is static, we consider scenarios where the clients' data distributions may be reshaped by the deployed decision model. In this work, we leverage the idea of distribution shift mappings in performative prediction to formalize this model-dependent data distribution shift and propose a performative federated learning framework. We first introduce necessary and sufficient conditions for the existence of a unique performative stable solution and characterize its distance to the performative optimal solution. Then we propose the performative FedAvg algorithm and show that it converges to the performative stable solution at a rate of O(1/T) under both full and partial participation schemes. In particular, we use novel proof techniques and show how the clients' heterogeneity influences the convergence. Numerical results validate our analysis and provide valuable insights into real-world applications.
Long-Term Fairness with Unknown Dynamics
Apr 19, 2023



While machine learning can myopically reinforce social inequalities, it may also be used to dynamically seek equitable outcomes. In this paper, we formalize long-term fairness in the context of online reinforcement learning. This formulation can accommodate dynamical control objectives, such as driving equity inherent in the state of a population, that cannot be incorporated into static formulations of fairness. We demonstrate that this framing allows an algorithm to adapt to unknown dynamics by sacrificing short-term incentives to drive a classifier-population system towards more desirable equilibria. For the proposed setting, we develop an algorithm that adapts recent work in online learning. We prove that this algorithm achieves simultaneous probabilistic bounds on cumulative loss and cumulative violations of fairness (as statistical regularities between demographic groups). We compare our proposed algorithm to the repeated retraining of myopic classifiers, as a baseline, and to a deep reinforcement learning algorithm that lacks safety guarantees. Our experiments model human populations according to evolutionary game theory and integrate real-world datasets.