 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Bias Mitigation Toward Fairness Without Harm from Vision to LVLMs
Feb 03, 2026Machine learning models trained on real-world data often inherit and amplify biases against certain social groups, raising urgent concerns about their deployment at scale. While numerous bias mitigation methods have been proposed, comparing the effectiveness of bias mitigation methods remains difficult due to heterogeneous datasets, inconsistent fairness metrics, isolated evaluation of vision versus multi-modal models, and insufficient hyperparameter tuning that undermines fair comparisons. We introduce NH-Fair, a unified benchmark for fairness without harm that spans both vision models and large vision-language models (LVLMs) under standardized data, metrics, and training protocols, covering supervised and zero-shot regimes. Our key contributions are: (1) a systematic ERM tuning study that identifies training choices with large influence on both utility and disparities, yielding empirically grounded guidelines to help practitioners reduce expensive hyperparameter tuning space in achieving strong fairness and accuracy; (2) evidence that many debiasing methods do not reliably outperform a well-tuned ERM baseline, whereas a composite data-augmentation method consistently delivers parity gains without sacrificing utility, emerging as a promising practical strategy. (3) an analysis showing that while LVLMs achieve higher average accuracy, they still exhibit subgroup disparities, and gains from scaling are typically smaller than those from architectural or training-protocol choices. NH-Fair provides a reproducible, tuning-aware pipeline for rigorous, harm-aware fairness evaluation.
Observations and Remedies for Large Language Model Bias in Self-Consuming Performative Loop
Jan 08, 2026The rapid advancement of large language models (LLMs) has led to growing interest in using synthetic data to train future models. However, this creates a self-consuming retraining loop, where models are trained on their own outputs and may cause performance drops and induce emerging biases. In real-world applications, previously deployed LLMs may influence the data they generate, leading to a dynamic system driven by user feedback. For example, if a model continues to underserve users from a group, less query data will be collected from this particular demographic of users. In this study, we introduce the concept of \textbf{S}elf-\textbf{C}onsuming \textbf{P}erformative \textbf{L}oop (\textbf{SCPL}) and investigate the role of synthetic data in shaping bias during these dynamic iterative training processes under controlled performative feedback. This controlled setting is motivated by the inaccessibility of real-world user preference data from dynamic production systems, and enables us to isolate and analyze feedback-driven bias evolution in a principled manner. We focus on two types of loops, including the typical retraining setting and the incremental fine-tuning setting, which is largely underexplored. Through experiments on three real-world tasks, we find that the performative loop increases preference bias and decreases disparate bias. We design a reward-based rejection sampling strategy to mitigate the bias, moving towards more trustworthy self-improving systems.
Understanding Structured Financial Data with LLMs: A Case Study on Fraud Detection
Dec 15, 2025Detecting fraud in financial transactions typically relies on tabular models that demand heavy feature engineering to handle high-dimensional data and offer limited interpretability, making it difficult for humans to understand predictions. Large Language Models (LLMs), in contrast, can produce human-readable explanations and facilitate feature analysis, potentially reducing the manual workload of fraud analysts and informing system refinements. However, they perform poorly when applied directly to tabular fraud detection due to the difficulty of reasoning over many features, the extreme class imbalance, and the absence of contextual information. To bridge this gap, we introduce FinFRE-RAG, a two-stage approach that applies importance-guided feature reduction to serialize a compact subset of numeric/categorical attributes into natural language and performs retrieval-augmented in-context learning over label-aware, instance-level exemplars. Across four public fraud datasets and three families of open-weight LLMs, FinFRE-RAG substantially improves F1/MCC over direct prompting and is competitive with strong tabular baselines in several settings. Although these LLMs still lag behind specialized classifiers, they narrow the performance gap and provide interpretable rationales, highlighting their value as assistive tools in fraud analysis.
Stabilizing Self-Consuming Diffusion Models with Latent Space Filtering
Nov 16, 2025As synthetic data proliferates across the Internet, it is often reused to train successive generations of generative models. This creates a ``self-consuming loop" that can lead to training instability or \textit{model collapse}. Common strategies to address the issue -- such as accumulating historical training data or injecting fresh real data -- either increase computational cost or require expensive human annotation. In this paper, we empirically analyze the latent space dynamics of self-consuming diffusion models and observe that the low-dimensional structure of latent representations extracted from synthetic data degrade over generations. Based on this insight, we propose \textit{Latent Space Filtering} (LSF), a novel approach that mitigates model collapse by filtering out less realistic synthetic data from mixed datasets. Theoretically, we present a framework that connects latent space degradation to empirical observations. Experimentally, we show that LSF consistently outperforms existing baselines across multiple real-world datasets, effectively mitigating model collapse without increasing training cost or relying on human annotation.
Achieving Fairness Without Harm via Selective Demographic Experts
Nov 09, 2025As machine learning systems become increasingly integrated into human-centered domains such as healthcare, ensuring fairness while maintaining high predictive performance is critical. Existing bias mitigation techniques often impose a trade-off between fairness and accuracy, inadvertently degrading performance for certain demographic groups. In high-stakes domains like clinical diagnosis, such trade-offs are ethically and practically unacceptable. In this study, we propose a fairness-without-harm approach by learning distinct representations for different demographic groups and selectively applying demographic experts consisting of group-specific representations and personalized classifiers through a no-harm constrained selection. We evaluate our approach on three real-world medical datasets -- covering eye disease, skin cancer, and X-ray diagnosis -- as well as two face datasets. Extensive empirical results demonstrate the effectiveness of our approach in achieving fairness without harm.
Self-Consuming Generative Models with Adversarially Curated Data
May 14, 2025Recent advances in generative models have made it increasingly difficult to distinguish real data from model-generated synthetic data. Using synthetic data for successive training of future model generations creates "self-consuming loops", which may lead to model collapse or training instability. Furthermore, synthetic data is often subject to human feedback and curated by users based on their preferences. Ferbach et al. (2024) recently showed that when data is curated according to user preferences, the self-consuming retraining loop drives the model to converge toward a distribution that optimizes those preferences. However, in practice, data curation is often noisy or adversarially manipulated. For example, competing platforms may recruit malicious users to adversarially curate data and disrupt rival models. In this paper, we study how generative models evolve under self-consuming retraining loops with noisy and adversarially curated data. We theoretically analyze the impact of such noisy data curation on generative models and identify conditions for the robustness of the retraining process. Building on this analysis, we design attack algorithms for competitive adversarial scenarios, where a platform with a limited budget employs malicious users to misalign a rival's model from actual user preferences. Experiments on both synthetic and real-world datasets demonstrate the effectiveness of the proposed algorithms.
BiasCause: Evaluate Socially Biased Causal Reasoning of Large Language Models
Apr 08, 2025While large language models (LLMs) already play significant roles in society, research has shown that LLMs still generate content including social bias against certain sensitive groups. While existing benchmarks have effectively identified social biases in LLMs, a critical gap remains in our understanding of the underlying reasoning that leads to these biased outputs. This paper goes one step further to evaluate the causal reasoning process of LLMs when they answer questions eliciting social biases. We first propose a novel conceptual framework to classify the causal reasoning produced by LLMs. Next, we use LLMs to synthesize $1788$ questions covering $8$ sensitive attributes and manually validate them. The questions can test different kinds of causal reasoning by letting LLMs disclose their reasoning process with causal graphs. We then test 4 state-of-the-art LLMs. All models answer the majority of questions with biased causal reasoning, resulting in a total of $4135$ biased causal graphs. Meanwhile, we discover $3$ strategies for LLMs to avoid biased causal reasoning by analyzing the "bias-free" cases. Finally, we reveal that LLMs are also prone to "mistaken-biased" causal reasoning, where they first confuse correlation with causality to infer specific sensitive group names and then incorporate biased causal reasoning.
DroughtSet: Understanding Drought Through Spatial-Temporal Learning
Dec 19, 2024Drought is one of the most destructive and expensive natural disasters, severely impacting natural resources and risks by depleting water resources and diminishing agricultural yields. Under climate change, accurately predicting drought is critical for mitigating drought-induced risks. However, the intricate interplay among the physical and biological drivers that regulate droughts limits the predictability and understanding of drought, particularly at a subseasonal to seasonal (S2S) time scale. While deep learning has been demonstrated with potential in addressing climate forecasting challenges, its application to drought prediction has received relatively less attention. In this work, we propose a new dataset, DroughtSet, which integrates relevant predictive features and three drought indices from multiple remote sensing and reanalysis datasets across the contiguous United States (CONUS). DroughtSet specifically provides the machine learning community with a new real-world dataset to benchmark drought prediction models and more generally, time-series forecasting methods. Furthermore, we propose a spatial-temporal model SPDrought to predict and interpret S2S droughts. Our model learns from the spatial and temporal information of physical and biological features to predict three types of droughts simultaneously. Multiple strategies are employed to quantify the importance of physical and biological features for drought prediction. Our results provide insights for researchers to better understand the predictability and sensitivity of drought to biological and physical conditions. We aim to contribute to the climate field by proposing a new tool to predict and understand the occurrence of droughts and provide the AI community with a new benchmark to study deep learning applications in climate science.
Open-Set Heterogeneous Domain Adaptation: Theoretical Analysis and Algorithm
Dec 17, 2024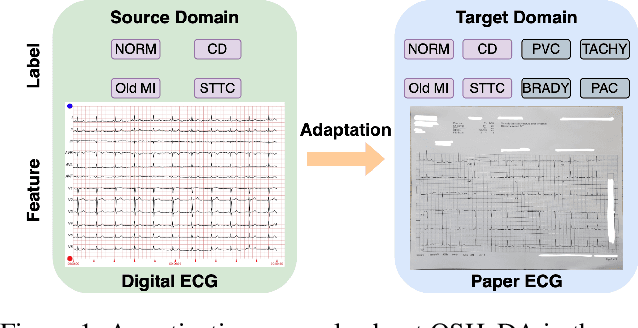
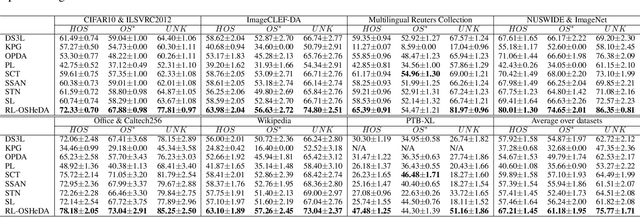
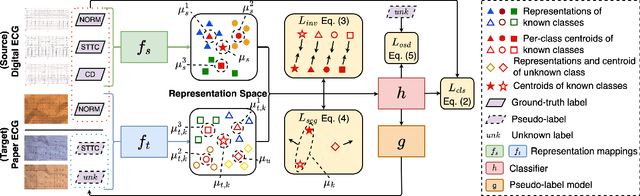
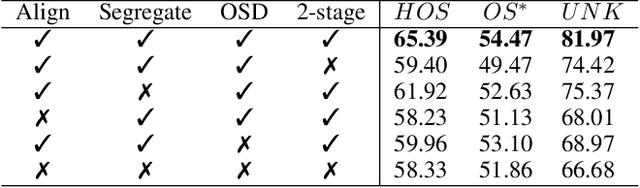
Domain adaptation (DA) tackles the issue of distribution shift by learning a model from a source domain that generalizes to a target domain. However, most existing DA methods are designed for scenarios where the source and target domain data lie within the same feature space, which limits their applicability in real-world situations. Recently, heterogeneous DA (HeDA) methods have been introduced to address the challenges posed by heterogeneous feature space between source and target domains. Despite their successes, current HeDA techniques fall short when there is a mismatch in both feature and label spaces. To address this, this paper explores a new DA scenario called open-set HeDA (OSHeDA). In OSHeDA, the model must not only handle heterogeneity in feature space but also identify samples belonging to novel classes. To tackle this challenge, we first develop a novel theoretical framework that constructs learning bounds for prediction error on target domain. Guided by this framework, we propose a new DA method called Representation Learning for OSHeDA (RL-OSHeDA). This method is designed to simultaneously transfer knowledge between heterogeneous data sources and identify novel classes. Experiments across text, image, and clinical data demonstrate the effectiveness of our algorithm. Model implementation is available at \url{https://github.com/pth1993/OSHeDA}.
Lookahead Counterfactual Fairness
Dec 02, 2024As machine learning (ML) algorithms are used in applications that involve humans, concerns have arisen that these algorithms may be biased against certain social groups. \textit{Counterfactual fairness} (CF) is a fairness notion proposed in Kusner et al. (2017) that measures the unfairness of ML predictions; it requires that the prediction perceived by an individual in the real world has the same marginal distribution as it would be in a counterfactual world, in which the individual belongs to a different group. Although CF ensures fair ML predictions, it fails to consider the downstream effects of ML predictions on individuals. Since humans are strategic and often adapt their behaviors in response to the ML system, predictions that satisfy CF may not lead to a fair future outcome for the individuals. In this paper, we introduce \textit{lookahead counterfactual fairness} (LCF), a fairness notion accounting for the downstream effects of ML models which requires the individual \textit{future status} to be counterfactually fair. We theoretically identify conditions under which LCF can be satisfied and propose an algorithm based on the theorems. We also extend the concept to path-dependent fairness. Experiments on both synthetic and real data validate the proposed method.